
Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
Table of Links
2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
3.1 Preparing Models with Early Exits
Upon job registration with a generic DNN, Apparate’s initial task is to automatically prepare that model to leverage EEs, without requiring any developer effort. This phase repeats any time the submitted model changes, e.g., continual retraining to cope with data drift [13, 35, 51].
Ramp locations. Apparate accepts a model in the ONNX format, a widely used IR that represents the computation as a directed acyclic graph [6]. Once ingested, Apparate must first identify candidate layers for ramp addition. The goal is to maximize ramp coverage across the model (to provide more configuration options for Apparate’s runtime management), while avoiding ramps that are unlikely to be fruitful (but add complexity adaptation decisions). To balance these aspects for diverse models, Apparate marks feasible ramp locations as those where operators are cut vertices, i.e., a vertex whose removal would disconnect a graph into two or more disjoint sub-graphs. In other words, no edge can start before a ramp and re-enter the model’s computation after the ramp.
The idea is that such ramps take advantage of all available data outputs from the original model’s processing to that point, boosting their chance at accurate predictions. As an example, consider families like ResNet or BERT which enable deep models by stitching together series of residual blocks, i.e., ResNet blocks for convolutions, or BERT encoders that each embed multi-head attention and feed-forward network residual blocks. To avoid performance degradations late in the model, the output of each block is ultimately a combination of its processing results and its input. In such scenarios, Apparate injects ramps between blocks, but not within each block to avoid ramps making decisions on partial data, i.e., ignoring block inputs. In contrast, for VGG models, ramps are feasible at all layers since their intermediates represent the full extent of data flow throughout the model. Figure 8 depicts these examples.
Overall, this strategy results in 9.2-68.4% of layers having ramps for the models in our corpus, which we empirically observe is sufficient to adapt to dynamic workloads (§5.2). However, we note that Apparate can directly support any other ramp configuration strategy, and offers a simple
API for developers to express ramp policies or restrictions. Moreover, for each feasible ramp, Apparate’s runtime monitoring (§3.2-3.3) ultimately monitors its accuracy and utility (and thus, if it is ever activated) for the workload at hand.
Ramp architectures. For each feasible ramp location, Apparate must determine the style of ramp computations to use. Recall from §2 that ramps can ultimately be composed of arbitrary layers and computations, with the only prerequisite being that the final layer sufficiently mimics that of the original model to ensure that response formats match. Determining the appropriate ramp complexity in this large space presents a tradeoff: additional computation can improve the exit capabilities of a ramp, but comes at the expense of (1) increased ramp latency, and (2) coarser flexibility and coverage at runtime since ramps become illogical if their computation exceeds that in the original model up until the next ramp.
Apparate opts for the shallowest ramps that can transform the intermediates at any layer into a final model prediction. Specifically, ramps comprise the model’s final fullyconnected (fc) layer, prepended with a lightweight pooling operation that reduces the dimensionality of intermediates to ensure compatability with the fc layer. This manifests differently for various model types. For instance, for vision models like ResNet, pooling is simply the model’s penultimate layer. In contrast, for BERT, only the basic operator is drawn from the BERT pooler module, i.e., extracting the hidden state corresponding to the first token [19]. Note that, for all models, the input width of the fc layer is modified to match that of the intermediates at each ramp location; the output remains unchanged to preserve result formats.
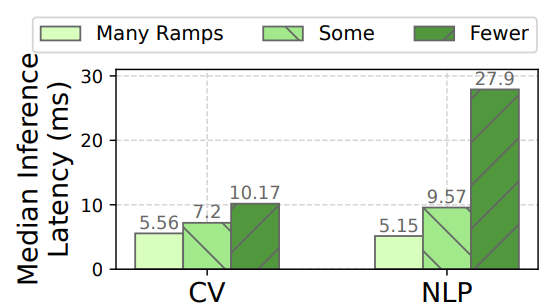
Figure 9 evaluates this methodology by comparing Apparate’s ramps with two, more expensive alternatives. With ResNet, to mimic model operations following each ramp, we add 1-2 convolution layers prior to pooling. For BERT, we consider two approaches: (1) add two fc layers after pooling, each with reduced width to shrink inputs to the final fc, and (2) inspired by DeeBERT [57], replacing the simple pooling operator with the entire BERT pooler block (which also includes dense linear and activation layers) and adding a dropout after pooling as in the original model. In all cases, the number of ramps is subject to the same ramp budget (i.e., Apparate’s default uses the most ramps), ramps are uniformly spaced across feasible positions in each model, and thresholds are optimally selected as in §2.2.
As shown, and in line with reflections from prior handdesigned EE models [53], we observe that the additional computation has minimal effect on ramp effectiveness. For example, median latencies are 1.3-1.8× and 1.9-5.4× larger with Apparate’s default ramps than the more complex alternatives for CV and NLP. Nonetheless, to showcase Apparate’s generality, we consider other ramp styles in §5.4.
Training ramps and deploying models. To determine the appropriate weights for each ramp, Apparate relies on an initial dataset that can either be user-provided or auto-generated by running the original model on historical data. Regardless, during training, Apparate freezes the original model weights to ensure that non-EE behavior and feedback for tuning EEs is unchanged from the user’s original intentions. In addition, Apparate enforces that all inputs are used to train all ramps, i.e., exiting is prohibited during training. This ensures that ramps are trained independently of the presence (or behavior) of any upstream ramps, which is crucial since the set of active ramps can vary at runtime. Further, such independence and the model freezing enable loss calculations to be backwards propagated in parallel across ramps, rapidly speeding up training despite Apparate’s use of many lightweight ramps. §4 details the training process.
For initial deployment, Apparate evenly spaces the max number of allowable ramps (based on the budget and GPU resources) across the model. To avoid accuracy dips due to discrepancies between training data and the current workload, each ramp begins with a threshold of 0, i.e., no exiting. The updated model definition (with enabled ramps) is passed to the serving platform which operates as normal, e.g., profiling expected model runtimes for different batch sizes [22].
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.