

Authors:
(1) Gladys Tyen, University of Cambridge, Dept. of Computer Science & Technology, ALTA Institute, and Work done during an internship at Google Research (e-mail: [email protected]);
(2) Hassan Mansoor, Google Research (e-mail: [email protected]);
(3) Victor Carbune, Google Research (e-mail: [email protected]);
(4) Peter Chen, Google Research and Equal leadership contribution ([email protected]);
(5) Tony Mak, Google Research and Equal leadership contribution (e-mail: [email protected]).
Table of Links
Conclusion, Limitations, and References
4 Backtracking
Madaan et al. (2023) and Huang et al. (2023) both demonstrate that self-correction is only effective with external feedback – for example, both Shinn et al. (2023) and Kim et al. (2023) rely on oracle labels for improvements – but there is often no external feedback available in many real-world applications.
As an alternative, we explore the possibility of replacing external feedback with a lightweight classifier trained on a small amount of data. Analogous to reward models in conventional reinforcement learning, this classifier detects any logical errors in a CoT trace, which is then fed back to the generator model to improve on the output. This can be done over multiple iterations to maximise improvements.
We propose a simple backtracking method to improve model outputs based on the location of logical errors:
1. First, the model generates an initial CoT trace. In our experiments, we use temperature = 0.
2. We then determine the mistake location in this trace using a reward model.
3. If there are no mistakes, we move onto the next trace. If there is a mistake (e.g. at Thought 4 in the example trace in Table 1),we prompt the model again for the same step but at temperature = 1, generating 8 outputs. We use same prompt and the partial trace containing all steps up to but not including the mistake step (e.g. up to Thought 3, prompting for Thought 4).
4. From the 8 outputs, we filter out any options that match what was previously identified as a mistake. From the remaining outputs, we select one with the highest log-probability.
5. Finally, with the new, regenerated step in place of the previous one, we generate the remaining steps of the trace again at temperature = 0.
Our backtracking method provides several benefits over existing self-correction methods:
• Unlike Shinn et al. (2023), Kim et al. (2023), etc., our approach does not depend on oracle knowledge of the answer. Instead, it relies on information (for example from trained a reward model) about logical errors, which can be determined on a step-by-step basis using a reward model. Logical errors can occur in correctans traces, or not occur in incorrectans traces8 .
• Unlike Shinn et al. (2023), Miao et al. (2023), and many others, backtracking does not rely on any specific prompt text or phrasing, thereby reducing associated idiosyncrasies.
• Compared to approaches that require regenerating the entire trace, backtracking reduces computational cost by reusing previous steps that are known to be logically sound.
• Backtracking improves on the quality of the intermediate steps directly, which can be useful in scenarios that require correct steps (e.g. generating solutions to math questions), and also generally improves interpretability.
Backtracking with mistake location information from a reward model can be construed as a lightweight RL method. However, unlike conventional deep reinforcement learning:
• Backtracking with a reward model does not does not require any training of the original generator model. Once the reward model is trained, it can be used for backtracking with any LLM as the generator, and can also be updated independently of the generator LM. This can be especially helpful when LLMs are frequently updated to new checkpoints.
• Backtracking only requires training of a small reward model. Compared to methods that require training of the generator model, backtracking is far more efficient in terms of computing resources and available data.
• The process of backtracking is more interpretable than updating the weights of the generator model directly, as is required for many deep RL methods. It clearly pinpoints the location at which an error occurs, which can help the debugging process and allow faster development and iterations of models.
4.1 Backtracking with gold mistake location
As an initial experiment, we use labels from BIGBench Mistake to test if an LLM is able to correct logical errors using backtracking, independent of its inherent ability to identify these errors or any other reward model.
For example, if the mistake location is in step 4, we use backtracking to regenerate that step and continue the rest of the chain. If the mistake location is that there are no logical mistakes, we do not backtrack and use the original result.
4.1.1 Results
The results are shown in Table 6. To show that performance increases are not due to randomly resampling outputs, we compare our results to a random baseline, where a mistake location9 is randomly selected for each trace and we perform backtracking based on the random location.
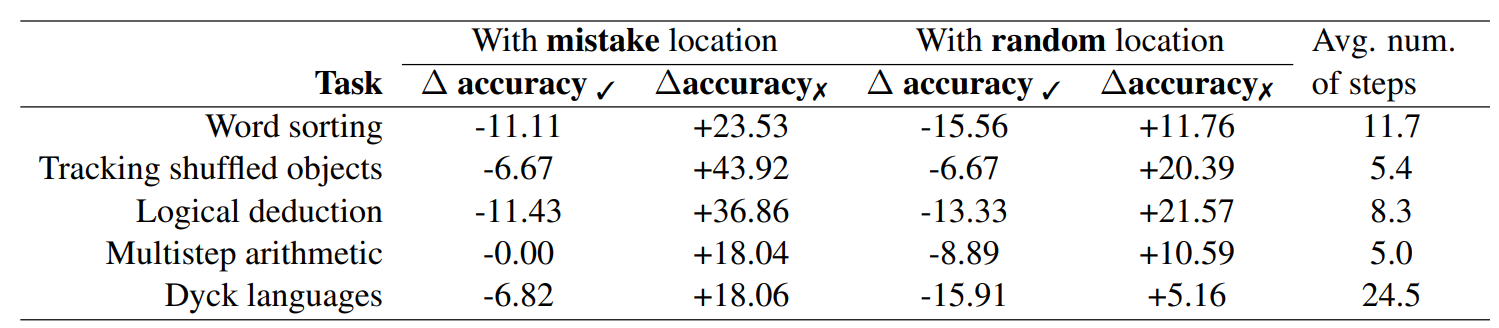
Note that Table 6 separates results into numbers for the correct set and the incorrect set, referring to whether the original trace was correctans or not. This gives a clearer picture than the overall accuracyans, which would be skewed by the proportion of traces that were originally correctans (15%) and incorrectans (85%)
Scores represent the absolute differences in accuracyans. We perform backtracking on both correctans and incorrectans traces, as long as there is a mistake in one of the steps.
∆accuracy✓ refers to differences in accuracyans on the set of traces whose original answer was correctans. Note that we take losses here because, despite the correct answer, there is a logical mistake in one of the steps. Therefore, the answer may change to an incorrect one when we backtrack.
∆accuracy✗ is the same but for incorrectans traces, so the answers may have been corrected, hence increasing accuracyans.
For example, for the word sorting task, 11.11% of traces that were originally correctans became incorrectans, while 23.53% of traces that were originally incorrectans became correctans.
4.1.2 Discussion
The scores show that the gains from correcting incorrectans traces are larger than losses from changing originally correct answers. Additionally, while the random baseline also obtained improvements, they are considerably smaller than if the true mistake location was used. Note that tasks involving fewer steps are more likely to improve performance in the random baseline, as the true mistake location is more likely to be identified.
While our numbers do show that our gains are higher than our losses, it should be noted that changes in the overall accuracy depends on the original accuracy achieved on the task. For example, if the original accuracy on the tracking shuffled objects task was 50%, the new accuracy would be 68.6%. On the other hand, if the accuracy was 99%, the new accuracy would drop to 92.8%. As our dataset is highly skewed and only contains 45 correctans traces per task, we leave to future work to assess the effectiveness of backtracking in a more comprehensive way.
4.2 Backtracking with a simulated reward model
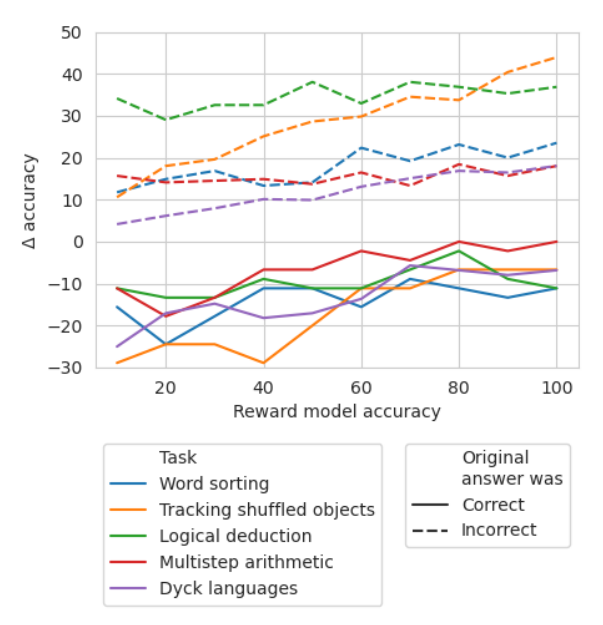
We show in subsection 4.1 that backtracking can be used to correct CoT traces using gold mistake location labels. To explore what level of accuracy reward model is needed when gold labels are not available, we use backtracking with simulated reward models, designed to produce labels at different levels of accuracy. We use accuracyRM to refer to the accuracy of the simulated reward model at identifying mistake locations.
For a given reward model at X% accuracyRM, we use the mistake location from BIG-Bench Mistake X% of the time. For the remaining (100 − X)%, we sample a mistake location randomly. To mimic the behaviour of a typical classifier, mistake locations are sampled to match the distribution found in the dataset. We also ensure that the sampled location does not match the correct location.
4.2.1 Results
Results are shown in Figure 2. We can see that the losses in ∆accuracy✓ begins to plateau at 65%. In fact, for most tasks, ∆accuracy✓ is already larger than ∆accuracy✗ at around 60-70% accuracyRM. This demonstrates that while higher accuracies produce better results, backtracking is still effective even without gold standard mistake location labels.
4.3 Reward Modeling
We perform a preliminary investigation of if mistake-finding can benefit from a dedicated reward model and if learning to find mistakes in a set of tasks can transfer to finding mistakes in out-of-distribution tasks. We fine-tuned a PaLM 2-XS-Otter model based on our available data for 20k steps and choose the checkpoint with the best validation results. We hold out one task for evaluation while training the reward model on the other 4 tasks.

Note the reward model we train is significantly smaller than our inference model. We show the relative improvements and losses in Table 7 vs. a zero-shot baseline on PaLM 2-L-Unicorn. We see gains for 4 out of 5 of the tasks. This provides initial indication that it maybe possible to train separate reward model classifiers to assist in backtracking and that these reward models do not have to be large. Further, a reward model can work on mistakes that are out-of-distribution.
However, we believe more data may be necessary to improve results across the board on all tasks. We leave the collection of this larger dataset and a more rigorous investigation of the trade-offs of model size vs. performance of the reward model to future work.
We also leave for future work the effect of backtracking iteratively with a reward model: for example, the generator model may make another mistake after backtracking for the first time, which can then be identified and corrected again.
This paper is available on arxiv under CC 4.0 license.