
Authors:
(1) Chengrun Yang, Google DeepMind and Equal contribution;
(2) Xuezhi Wang, Google DeepMind;
(3) Yifeng Lu, Google DeepMind;
(4) Hanxiao Liu, Google DeepMind;
(5) Quoc V. Le, Google DeepMind;
(6) Denny Zhou, Google DeepMind;
(7) Xinyun Chen, Google DeepMind and Equal contribution.
Table of Links
2 Opro: Llm as the Optimizer and 2.1 Desirables of Optimization by Llms
3 Motivating Example: Mathematical Optimization and 3.1 Linear Regression
3.2 Traveling Salesman Problem (TSP)
4 Application: Prompt Optimization and 4.1 Problem Setup
5 Prompt Optimization Experiments and 5.1 Evaluation Setup
5.4 Overfitting Analysis in Prompt Optimization and 5.5 Comparison with Evoprompt
7 Conclusion, Acknowledgments and References
B Prompting Formats for Scorer Llm
C Meta-Prompts and C.1 Meta-Prompt for Math Optimization
C.2 Meta-Prompt for Prompt Optimization
D Prompt Optimization Curves on the Remaining Bbh Tasks
E Prompt Optimization on Bbh Tasks – Tabulated Accuracies and Found Instructions
3 MOTIVATING EXAMPLE: MATHEMATICAL OPTIMIZATION
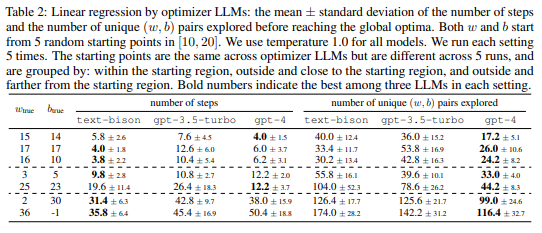
We first demonstrate the potential of LLMs in serving as optimizers for mathematical optimization. In particular, we present a case study on linear regression as an example of continuous optimization, and on the Traveling Salesman Problem (TSP) as an example of discrete optimization. On both tasks, we see LLMs properly capture the optimization directions on small-scale problems merely based on the past optimization trajectory provided in the meta-prompt.
3.1 LINEAR REGRESSION 

This paper is available on arxiv under CC0 1.0 DEED license.