

Authors:
(1) Mingjie Liu, NVIDIA {Equal contribution};
(2) Teodor-Dumitru Ene, NVIDIA {Equal contribution};
(3) Robert Kirby, NVIDIA {Equal contribution};
(4) Chris Cheng, NVIDIA {Equal contribution};
(5) Nathaniel Pinckney, NVIDIA {Equal contribution};
(6) Rongjian Liang, NVIDIA {Equal contribution};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Table of Links
- Abstract and Intro
- Dataset
- ChipNemo Domain Adaptation Methods
- LLM Applications
- Evaluations
- Discussion
- Related Works
- Conclusions
- Acknowledgments, Contributions and References
- Appendix
Abstract
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there’s still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
I. INTRODUCTION
Over the last few decades, Electronic Design Automation (EDA) algorithms and tools have provided huge gains in chip design productivity. Coupled with the exponential increases in transistor densities provided by Moore’s law, EDA has enabled the development of feature-rich complex SoC designs with billions of transistors. More recently, researchers have been exploring ways to apply AI to EDA algorithms and the chip design process to further improve chip design productivity [1] [2] [3]. However, many time-consuming chip design tasks that involve interfacing with natural languages or programming languages still have not been automated. The latest advancements in commercial (ChatGPT, Bard, etc.) and open-source (Vicuna [4], LLaMA2 [5], etc.) large language models (LLM) provide an unprecedented opportunity to help automate these languagerelated chip design tasks. Indeed, early academic research [6] [7] [8] has explored applications of LLMs for generating RTL that can perform simple tasks in small design modules as well as generating scripts for EDA tools.
We believe that LLMs have the potential to help chip design productivity by using generative AI to automate many language related chip design tasks such as code generation, responses to engineering questions via a natural language interface, analysis §Equal contribution and report generation, and bug triage. In this study, we focus on these three specific LLM applications: an engineering assistant chatbot for GPU ASIC and Architecture design engineers, which understands internal HW designs and is capable of explaining complex design topics; EDA scripts generation for two domain specific tools based on Python and Tcl for VLSI timing analysis tasks specified in English; bug summarization and analysis as part of an internal bug and issue tracking system.
Although general-purpose LLMs trained on vast amounts of internet data exhibit remarkable capabilities in generative AI tasks across diverse domains (as demonstrated by Bubeck et al. in [9]), recent work such as BloombergGPT [10] and BioMedLLM [11] demonstrate that domain-specific LLM models can outperform a general-purpose model on domain-specific tasks. In the hardware design domain, [6] [12] showed that opensource LLMs (CodeGen [13]) fine-tuned on additional Verilog data can outperform state-of-art OpenAI models. Customizing LLMs in this manner also avoids security risks associated with sending proprietary chip design data to third party LLMs via APIs. However, it would be prohibitively expensive to train domain-specific models for every domain from scratch, since this often requires millions of GPU training hours. To cost-effectively train domain-specific models, we instead propose to combine the following techniques: Domain-Adaptive PreTraining (DAPT) [14] of foundation models with domain-adapted tokenizers, model alignment using general and domain specific instructions, and retrieval-augmented generation (RAG) [15] with a trained domain-adapted retrieval model.
As shown in Figure 1, our approach is to start with a base foundational model and apply DAPT followed by Supervised Fine-Tuning (SFT). DAPT, also known as continued pretraining with in-domain data, has been shown to be effective in areas such as biomedical and computer science publications, news, and reviews. In our case, we construct our domain-specific pre-training dataset from a collection of proprietary hardwarerelated code (e.g. software, RTL, verification testbenches, etc.) and natural language datasets (e.g. hardware specifications, documentation, etc.). We clean up and preprocess the raw dataset, then continued-pretrain a foundation model with the domain-specific data. We call the resulting model a ChipNeMo
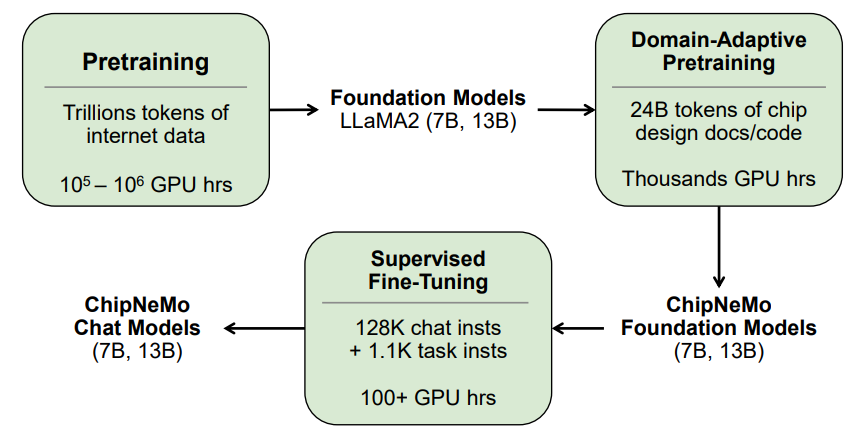
Foundation Model. DAPT is done on a fraction of the tokens used in pre-training, and is much cheaper, only requiring a few thousand GPU hours. As described in Section V, we find this approach to be more effective than Parameter Efficient Training (PEFT) techniques such as LoRA [16] for our use cases.
LLM tokenizers convert text into sequences of tokens for LLM training. A domain-specific tokenizer improves the tokenization efficiency by tailoring rules and patterns for domain-specific terms such as keywords commonly found in RTL. For DAPT, we cannot retrain a new domain-specific tokenizer from scratch, since it would make the foundation model invalid. Instead of restricting ChipNeMo to the pretrained general-purpose tokenizer used by the foundation model, we instead adapt the pre-trained tokenizer to our chip design dataset, only adding new tokens for domain-specific terms.
ChipNeMo foundation models are completion models which require supervised-fine-tuning (SFT) to adapt to tasks such as chat. We use largely publicly available general-purpose chat instruction datasets for multi-turn chat together with a small amount of domain-specific instruction datasets to perform SFT on the ChipNeMo foundation model, which produces the ChipNeMo Chat model. We observe that SFT with a general purpose chat instruction dataset is adequate to align the ChipNeMo foundation models with queries in the chip design domain. We also added a small amount of task-specific SFT instruction data, which further improves the alignment. We trained multiple ChipNeMo Foundation and Chat models based on variants of LLaMA2 models used as the base foundation model.
To improve performance on the engineering assistant chatbot application, we also leverage Retrieval Augmented Generation (RAG). RAG is an open-book approach for giving LLMs precise context for user queries. It retrieves relevant in-domain knowledge from its data store to augment the response generation given a user query. This method shows significant improvement in grounding the model to the context of a particular question. Crucially we observed significant improvements in retrieval hit rate when finetuning a pretrained retrieval model with domain data. This led to even further improvements in model quality.
We highlight the following contributions and findings related to adapting LLMs to the chip design domain:
• We demonstrate domain-adapted LLM effectiveness on three use-cases: an engineering assistant chatbot, EDA tool script generation, and bug summarization and analysis. We achieve a score of 7.4 out of 10 point scale for engineering assistant chatbot responses based on expert evaluations, achieve more than 50% correctness in EDA script generation, and expert evaluation rating of 4 to 5 out of 7 point scale for summarizations and assignment identification tasks.
• Domain-adapted ChipNeMo models dramatically outperforms all vanilla LLMs evaluated on both multiplechoice domain-specific AutoEval benchmarks and human evaluations for applications.
• For tasks where it is possible for the model to generate text from the prompt context (e.g. chat with RAG hits, summarization, code generation with provided documentation), domain-adaptation closes the gap between a state-of-theart LLaMA2 70B model and a much smaller 13B model (a small incremental training cost enables up to 5x parameter reduction for reduced inference cost).
• Customized tokenizers reduce DAPT token count by up to 3.3% without hurting effectiveness on applications.
• SFT on an additional 1.1K domain-specific instructions significantly improves applications proficiency by up to 0.33 out of 10-point scale, 18% correctness and 0.79 out of 7-point scale in engineering assistant chatbot, EDA scripts generation, and bug summarization and analysis, respectively.
• Fine-tuning our ChipNeMo retrieval model with domainspecific data improves the retriever hit rate by 30% over a pre-trained state-of-the-art retriever, in turn improving overall quality of RAG responses.
The paper is organized as follows. Section II describes our dataset and auto evaluation benchmarks for domain knowledge verification. Section III outlines domain adaptation and training methods used including the adapted tokenizer, DAPT, SFT, and RAG. Section IV provides details of each application and the experimental setup. Section V describes the experimental results including human evaluations for each application. Section VI discusses ChipNeMo limitations and future work. Section VII describes relevant LLM methods and other work targeting LLMs for chip design. Finally, complete results along with additional model training details and examples of text generated by the application use-cases are illustrated in the Appendix.
This paper is available on arxiv under CC 4.0 license.