

Table of Links
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
A ADDITIONAL EXPERIMENTS
A.1 ADDITIONAL NATURAL LANGUAGE UNDERSTANDING RESULTS
We evaluate the natural language processing capabilities of DREAMLLM post-multimodal adaptation learning via zero-shot experiments on language-only tasks. These included commonsense reasoning (PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019), WinoGrande (Sakaguchi et al., 2021)), reading comprehension (BoolQ (Clark et al., 2019)), and a general multi-task benchmark (MMLU 5-shot (Hendrycks et al., 2021)).
As Table 4 illustrates, DREAMLLM outperforms the Vicuna baseline on most language benchmarks. This suggests that DREAMLLM’s multimodal adaptation does not compromise the language learning model’s (LLM) capabilities. When compared to prior Multimodal Language Learning Models (MLLMs), DREAMLLM demonstrates superior performance, although this may be attributed to the higher baseline results. This finding suggests that a more robust LLM base model could yield improved results.
A.2 ADDITIONAL MULTIMODAL COMPREHENSION RESULTS
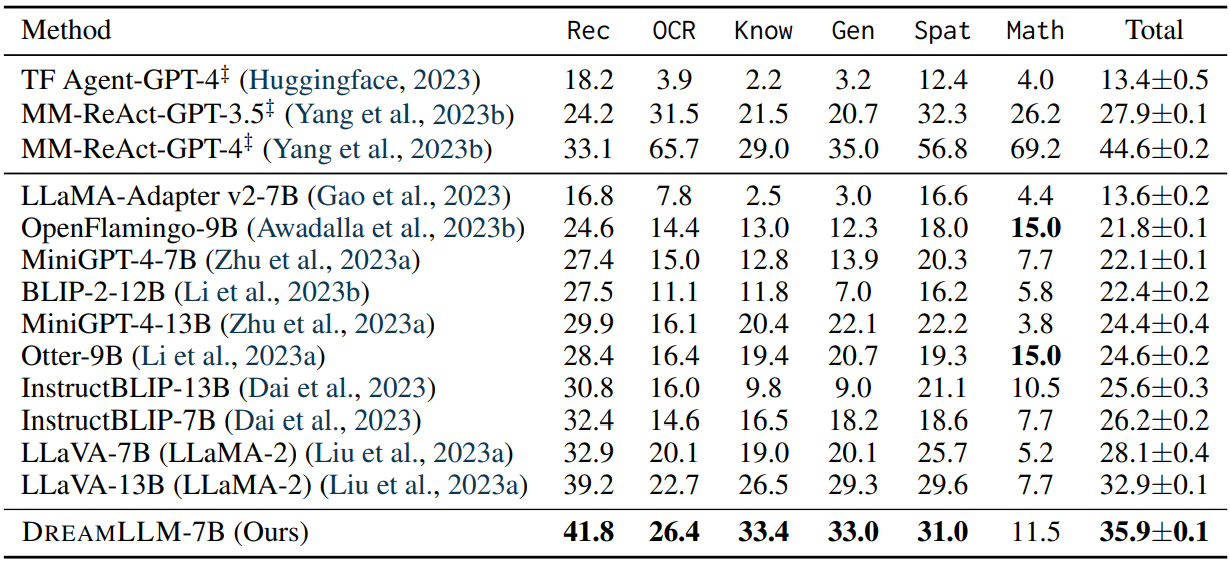
Detailed Comprehensive Comparison The evaluation results on MMBench (Liu et al., 2023c) and MM-Vet (Yu et al., 2023b) are presented in Table 5 and Table 6, respectively.
The key observations from these results are as follows: i) Our DREAMLLM-7B outperforms all other 7B MLLMs, setting a new benchmark in overall performance. Notably, it even exceeds the performance of some 13B models, including LLaVA and MiniGPT-4. ii) A detailed capability evaluation reveals DREAMLLM’s superior performance in fine-grained understanding and relational/spatial comprehension. This advantage is likely due to DREAMLLM’s unique learning synergy, where image distributions are comprehended not solely through language-posterior comprehension, but also through creation.
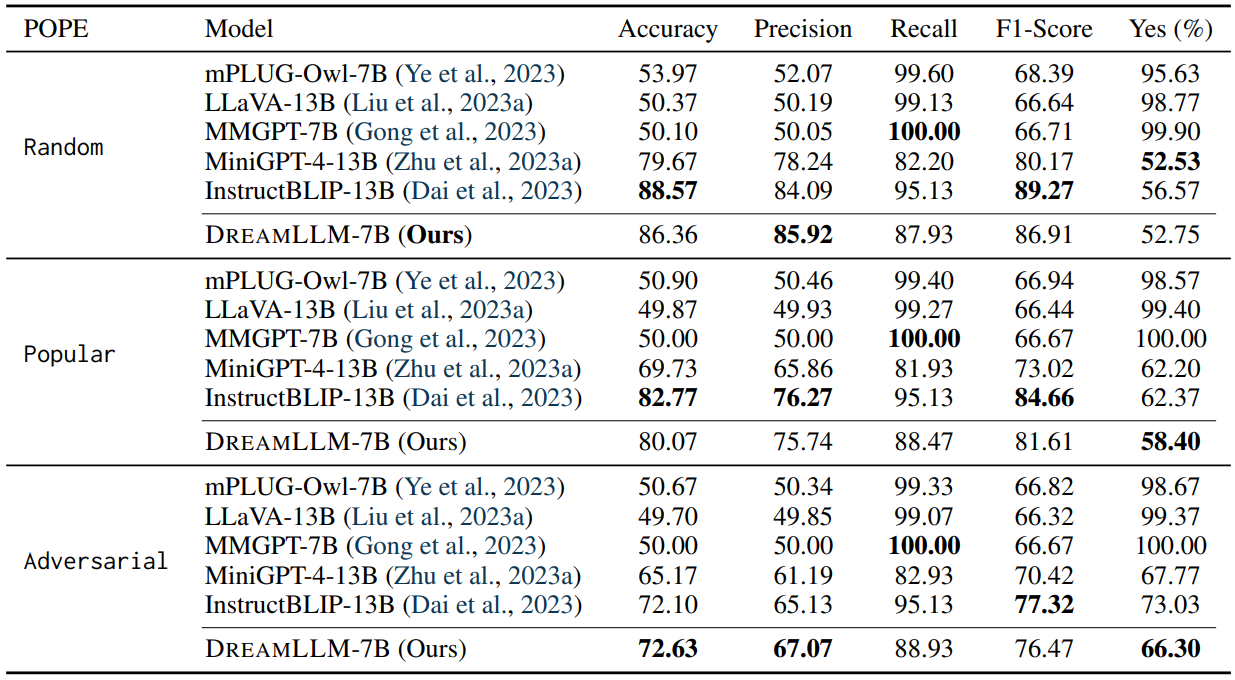
Visual Hallucination Visual hallucination, a phenomenon where Multimodal Large Language Models (MLLMs) generate non-existent objects or identities in images, significantly compromises their multimodal comprehension capabilities and may pose safety risks (MacLeod et al., 2017; Rohrbach et al., 2018). We assess the robustness of DREAMLLM against visual hallucination using the recently developed POPE benchmark (Li et al., 2023d).
Refer to Table 7 for a detailed comparison with concurrent comprehension-only MLLMs. Our results indicate that DREAMLLM-7B exhibits robustness to visual hallucination, matching or surpassing the performance of 13B counterparts. Remarkably, DREAMLLM achieves most best or second-best performance in the most challenging setting. We posit that this robust anti-hallucination property stems from a deep understanding of object concepts and semantics, fostered by multimodal creation learning.

A.3 ADDITIONAL ABLATION STUDY
Query Number In Table 8a, we show the results of DREAMLLM using different numbers of the proposed learnable queries. i.e., queries. The results show that 64 queries achieve the best result, while 128 may be too many that may impact the performance. However, the choice of query number is also related to the training data size and diffusion model choice. For example, if given more data and a stronger diffusion model image decoder, queries more than 64 may be better.
A.4 INFERENCE LATENCY
In Table 8b, we present a comparison of real-time inference latency between DREAMLLM and SD. Relative to SD, DREAMLLM introduces a marginal latency cost of 0.2s on average. This is because the latency primarily stems from the computational demands of the diffusion U-Net denoising, rather than the text condition embedding.
To enhance inference efficiency, potential strategies could include the adoption of Consistency Models (Song et al., 2023), or the implementation of model compression techniques such as quantization (Yao et al., 2022; Dong et al., 2022; Shang et al., 2023).
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.