
Author:
(1) David Novoa-Paradela, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain & Corresponding author (Email: [email protected]);
(2) Oscar Fontenla-Romero, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: [email protected]);
(3) Bertha Guijarro-Berdiñas, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: [email protected]).
Table of Links
3. The proposed pipeline
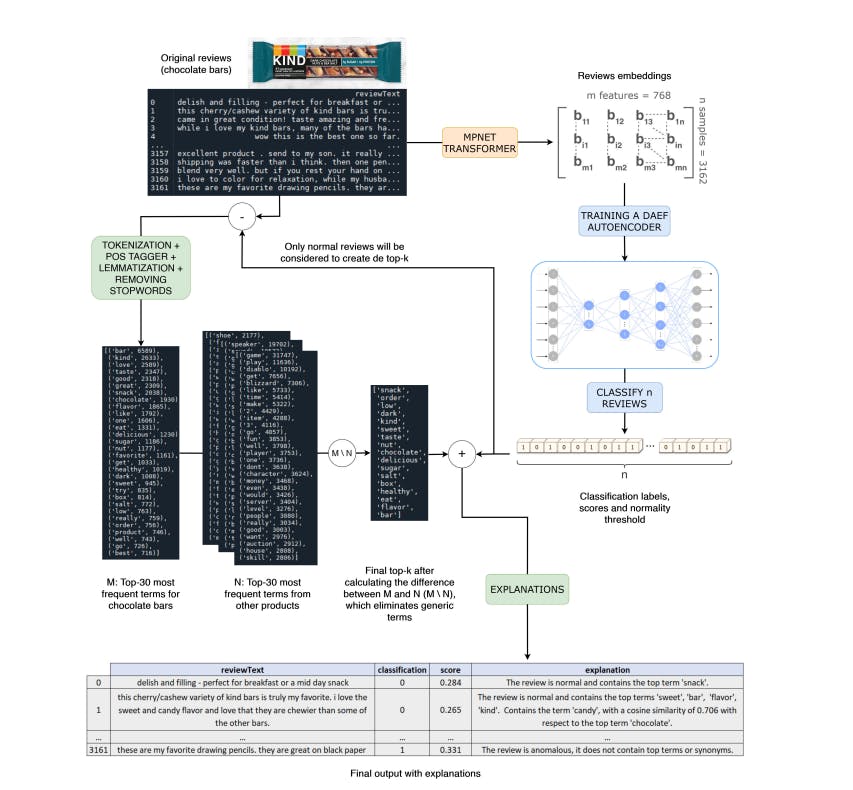
The purpose of the proposed pipeline is, given the text reviews of an Amazon product, to classify them as normal if they refer to it, and as anomalous if they describe different products or if they are so generic that they do not provide useful information to consumers. These classifications will be accompanied by a normality score and explanations that justify them. Figure 1 shows the modules that are part of the proposed pipeline to solve this task. In the first phase, we encode the text reviews of the target product using the pretrained MPNet transformer [25]. In the second phase, a DAEF [26] autoencoder is trained using these embeddings. Using the reconstruction errors issued by the network and a predefined threshold error, we can classify reviews as normal (error greater than the threshold) or anomalous (error less than the threshold). For the last phase, we propose a method based on the most frequent normal terms to generate an explanation associated with each classification.
Therefore, the proposed pipeline is composed of three main modules: (1) Text encoding; (2) Anomaly detection; (3) Explainability. The following sections describe each of them in detail.
3.1. Text encoding
Although there are models capable of dealing directly with images or text, machine learning models are usually designed to be trained using numerical vectors that represent the sample data (tabular data). This input format of the data is the usual one for classic anomaly detection methods. In the NLP area, there are multiple techniques to represent texts using vectors of real numbers, which are known as embeddings. These techniques allow the generation of vector spaces that try to represent the relationships and semantic similarities of the language, so that, for example, two synonymous words will be found at a shorter distance in the vector space than two unrelated words.
Embeddings can be calculated independently for each word of the language (word embeddings), which led to models such as word2vec [27] or Global Vectors (GloVe) [28]. The representation of a sentence (sentence embedding) or a document (document embedding) will therefore be the sum of all the individual representations of the terms that make it up. To obtain representations of fixed length, it is usual to perform operations such as the mean. In certain cases, these operations between embeddings can worsen or even invalidate the final embedding, so specific models have been developed capable of understanding and representing a text as a whole, instead of just encoding it word by word. Among these models are those based on transformers [29], such as BERT [30], XLNet [31], GPT-3 [32] or GPT-4 [33], which have been trained over large-scale datasets and can solve different tasks, including sentence embedding.
Since it inherits the advantages of the BERT and XLNet models while overcoming their limitations, we will use the pre-trained MPNet [25] model to calculate the embeddings of the reviews. MPNet combines Masked Language Modeling (MLM) and Permuted Language Modeling (PLM) to predict token dependencies, using auxiliary position information as input to enable the model to view a complete sentence and reduce position differences. Models like GPT-3 or GPT-4 are more advanced, but in addition to not being open source, they demand much higher computational resources, unaffordable for a significant part of the scientific community, as is our particular case.
MPNet maps sentences and paragraphs to a 768 dimensional dense vector space e ∈ R 768×1 , providing fast and quality encodings. Computing time is a critical aspect in the area in which this work is framed, since in e-commerce platforms (and online reviews in general) we can find a huge number of products and reviews to deal with. Therefore, the proposed pipeline uses MPNet to calculate the embeddings of the reviews, which allows them to be represented as numeric vectors of fixed size. This model and others are available in the Hugging Face repository [34].
3.2. Anomaly detection
Anomaly detection is a field with a large number of algorithms that solve the problem of distinguishing between normal and anomalous instances in a wide variety of ways [4, 35]. Depending on the assumptions made and the processes they employ, we can distinguish between five main types of methods: probabilistic, distance-based, information theory-based, boundarybased, and reconstruction-based methods. Among the latter are autoencoder networks (AE) [36], one of the most widely used models. AE are a type of self-associative neural network whose output layer seeks to reproduce the data presented to the input layer after having gone through a dimensional compression phase. In this way, they manage to obtain a representation of the input data in a space with a dimension smaller than the original, learning a compact representation of the data, retaining the important information, and compressing the redundant one.
One of the requirements of our proposed pipeline is to generate a normality score for each review. This score will allow us, among other things, to order the different reviews by their level of normality. When AE networks are used in anomaly detection scenarios, the classification is usually carried out based on the reconstruction error that they emit to reproduce in its output the embeddings of the reviews it receives as inputs, which represents the level of normality of the evaluated instance. This reconstruction error can be used as the normality score we are looking for.
Due to the speed of its training, we have decided to use DAEF (Deep Autoencoder for Federated learning) [26] as our anomaly detection model. Unlike traditional neural networks, DAEF trains a deep AE network in a non-iterative way, which drastically reduces its training time without losing the performance of traditional (iterative) AEs. The proposed pipeline uses DAEF to calculate the embeddings of the reviews, being able to issue a normality score associated with each of the review classifications.
3.3. Explainability
As black-box ML models are mainly being employed to make important predictions in critical contexts, the demand for transparency is increasing. The danger is in creating and using decisions that are not justifiable, legitimate, or that do not allow obtaining detailed explanations of their behaviour. Explanations supporting the output of a model are crucial, moreover in fields such as medicine, autonomous vehicles, security, or finance.
When ML models do not meet any of the criteria imposed to declare them explainable, a separate method must be applied to the model to explain its decisions. This is the purpose of post-hoc explainability techniques [37], which aim at communicating understandable information about how an already developed model produces its predictions for any given input. Within these techniques, the so-called model-agnostic techniques are those designed to be plugged into any model with the intent of extracting some information from its prediction procedure.
To generate the explanations we have implemented an approach based on a statistical analysis of the dataset. Based on the definitions of normal and anomalous review presented in Section 2, Our hypothesis assumes that normal reviews will always refer directly or indirectly to the target product so that there will be a list of terms used very frequently among normal texts. The appearance of one or more of these “normal” terms in a review would justify its classification by the system as normal. In the same way, anomalous reviews may be justified with the non-presence of said terms.
The original text reviews classified as normal using the AD model will be processed (tokenization, lemmatization and stopword removal) and analyzed to obtain the list of the top-n most frequent terms. This list of terms will be compared with the lists of frequent terms of other products in order to remove the terms they have in common, so that the final list for a product does not contain generic terms. This final list of terms will be used to generate the explanations. New reviews classified as normal will be searched for the presence of any of these terms. To make this search more flexible, it will also be analyzed if there are terms in the review semantically close to any of the words on the list. To quantify the closeness of two words, the cosine similarity emitted by the MPNet transformer model itself will be used as a measure of distance. Reviews classified as anomalous will be explained by the non-occurrence of terms from the list. Figure 2 represents an overall view of the pipeline considering the product “chocolate bars” as the normal class.
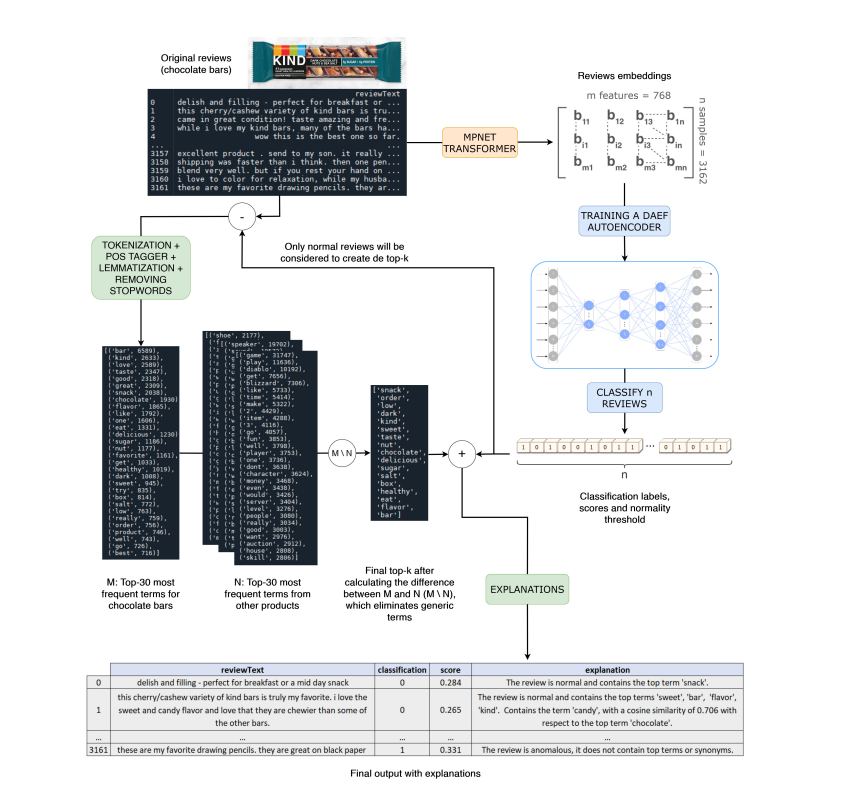
In summary, in this work, we propose the use of this statistical analysis of the terms to generate the explanations associated with the classification of the reviews.
This paper is available on arxiv under CC 4.0 license.