

Authors:
(1) Xueguang Ma, David R. Cheriton School of Computer Science, University of Waterloo;
(2) Liang Wang, Microsoft Research;
(3) Nan Yang, Microsoft Research;
(4) Furu Wei, Microsoft Research;
(5) Jimmy Lin, David R. Cheriton School of Computer Science, University of Waterloo.
Table of Links
Conclusion, Acknowledgements and References
4 Ablation Study and Analysis
4.1 Full Fine-Tuning vs. LoRA
When fine-tuning large language models, a key decision is whether to conduct full fine-tuning, which updates all parameters in the model, or to use a parameter-efficient method such as LoRA. Table 4 compares the effectiveness of RepLLaMA when trained with full fine-tuning and LoRA for the passage retrieval task. Both models are trained on the training set for one epoch.
We see that full fine-tuning achieves an MRR@10 score that is approximately 6 points higher than with LoRA on the training set. However, on the development set, full fine-tuning only improves effectiveness by 0.4 points compared to LoRA. Interestingly, on the TREC DL19/DL20 datasets, which are derived from independent human judgments, LoRA demonstrates better effectiveness. This suggests that full fine-tuning may be prone to overfitting on the training set distribution, while LoRA, with significantly fewer parameters, can generalizable better. For this reason, all the models presented in our main experiments (Section 3) use LoRA instead of full fine-tuning.
4.2 Input Sequence Length
As discussed in Section 3.2, RankLLaMA has the advantage of accommodating longer inputs compared to previous models like BERT since its LLaMA backbone was pre-trained with a longer context window. We investigate the effects of varying the maximum training input length and inference input length on model effectiveness for the document reranking task. Results presented in Figure 2 show a clear trend: the effectiveness of RankLLaMA improves as the maximum training length increases from 512 to 2048, with the MRR@100 score improving from 48.5 to 50.3. When the reranking input length is further increased to 4096, the MRR@100 score rises to 50.6. This demonstrates the model’s ability to exploit longer sequences for improved effectiveness.
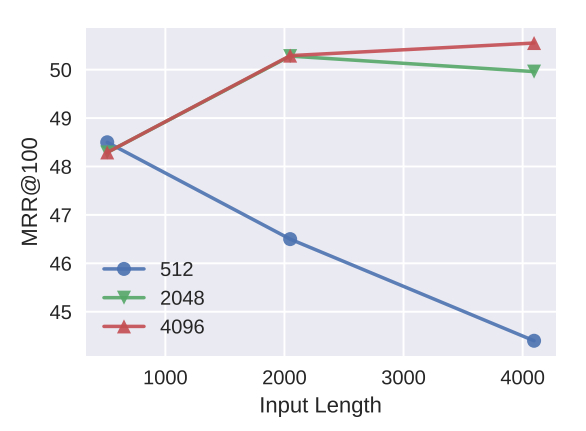
However, it is important to note that the gains plateau beyond a certain length, suggesting a point of diminishing returns. The MRR@100 for the model trained with a length of 4096 is only 0.3 points higher than the model trained with a length of 2048, when evaluated on input lengths that match their training lengths. Moreover, the model trained with a length of 4096 takes about 8 days to train using 16 × V100 GPUs, while the model with a length of 2048 takes about 4 days. The same relative latency costs apply to inference as well. Therefore, while RankLLaMA can handle much longer input documents, it is crucial to balance this capability with the practical considerations of computational efficiency.
This paper is available on arxiv under CC 4.0 license.