This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Ke Hong, Tsinghua University & Infinigence-AI;
(2) Guohao Dai, Shanghai Jiao Tong University & Infinigence-AI;
(3) Jiaming Xu, Shanghai Jiao Tong University & Infinigence-AI;
(4) Qiuli Mao, Tsinghua University & Infinigence-AI;
(5) Xiuhong Li, Peking University;
(6) Jun Liu, Shanghai Jiao Tong University & Infinigence-AI;
(7) Kangdi Chen, Infinigence-AI;
(8) Yuhan Dong, Tsinghua University;
(9) Yu Wang, Tsinghua University.
Table of Links
- Abstract & Introduction
- Backgrounds
- Asynchronized Softmax with Unified Maximum Value
- Flat GEMM Optimization with Double Buffering
- Heuristic Dataflow with Hardware Resource Adaption
- Evaluation
- Related Works
- Conclusion & References
4 Flat GEMM Optimization with Double Buffering
Motivation. The process of the decode phase is mainly composed of GEMV (batch size=1) or flat GEMM (batch size>1) operation. Without loss of generality, GEMV/GEMM operations can be represented using M, N, K, where the sizes of two multiplied matrices are M × K and K × N. Previous LLM inference engines utilize Tensor Core to accelerate these operations using libraries like cuBLAS [24] and CUTLASS [25]. Although modern Tensor Core architectures [32] process GEMM with M = 8, these libraries usually tile the M−dimension to 64 to hide memory latency. However, for GEMV or flat GEMM operations in the decode phase, we usually have M ≪ 64 and the M−dimension is padded to 64 with zeros. The padding leads to under-utilized computation, and the key problem is to process GEMV or flat GEMM operations with smaller tiles (i.e., padding to 8 corresponding to modern Tensor Core architectures) in the M−dimension.
the K−dimension. Tiles on the K−dimension are processed sequentially in a GPU block to avoid atomic operations during reduction. Tiling on the N−dimension affects both parallelism and computation/memory ratio, which are both important for GEMV and flat GEMM acceleration.
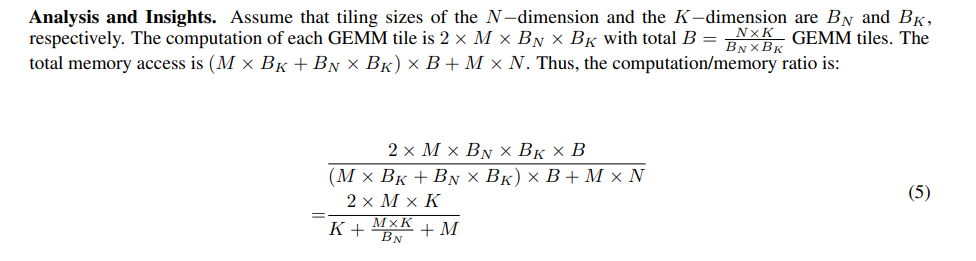
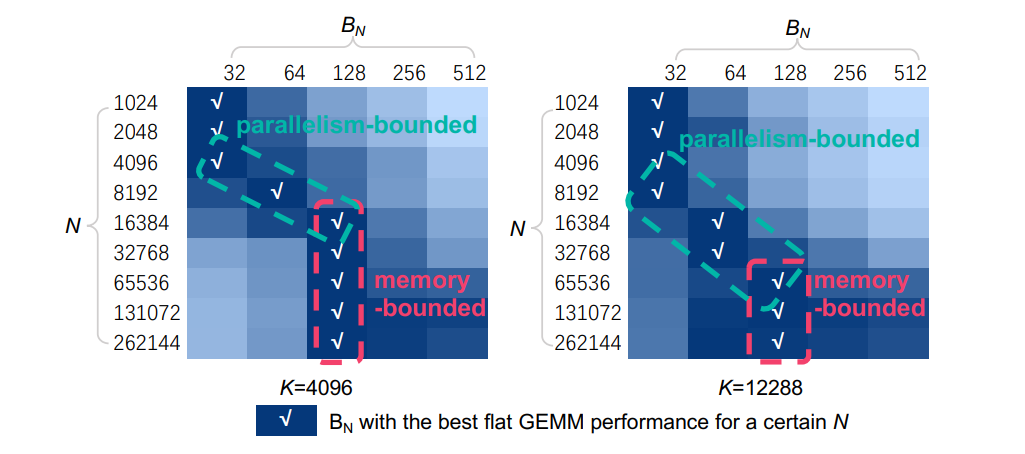
On the other hand, the parallelism is N BN . Thus, the computation/memory ratio shows a positive correlation with BN while the parallelism shows a negative correlation with BN , exposing a contradiction on improving the performance of GEMV or flat GEMM. We depict the normalized performance of the flat GEMM in Figure 7 with different N and BN . Our key insight is, for the smaller N, the flat GEMM is parallelism-bounded. There are 108 Streaming Multiprocessors (SMs) in the NVIDIA Tesla A100. N BN tends to be a constant (e.g., 128 or 256), which is related to the hardware parallelism (number of SMs). Another key insight is, for the larger N, the flat GEMM becomes memory-bounded. The performance of these cases can be improved by hiding memory access latency.
Approach: Double Buffering. In order to hide memory access latency, we introduce the double buffering technique. for the flat GEMM operation. We allocate two separate buffers in the shared memory. The tile in one buffer performs the GEMM operation, while another buffer loads a new tile for the next GEMM operation. Thus, the computation and the memory access are overlapped. We apply such a technique when N is large in our practice.
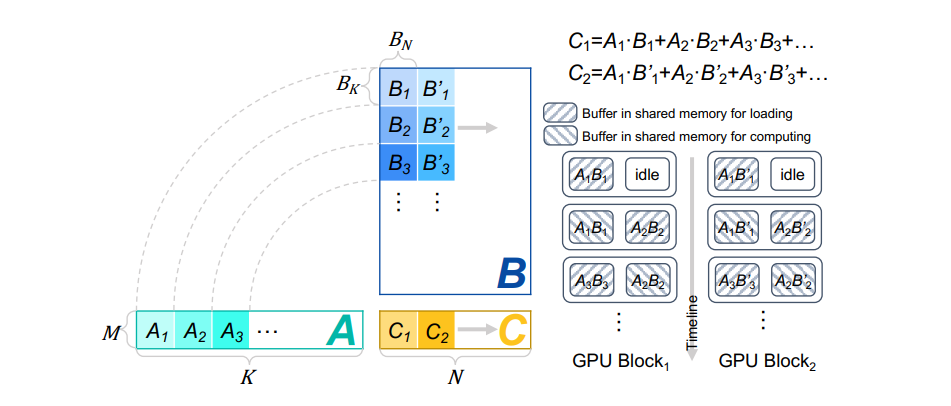
Example. Figure 8 shows the example of our flat GEMM optimization with double buffering. For M < 8, the M−dimension is first padded to 8 considering modern Tensor Core architectures. Workloads in the K−dimension are processed within one GPU block (e.g., A1, A2, A3, ...), while workloads in the N−dimension are processed in parallel using different GPU blocks (e.g., C1, C2, ...). We take GPU Block1 as an example, the first tile for each matrix in the K−dimension (i.e., A1 and B1) is loaded to the left buffer in the shared memory. Then, the GEMM operation is performed between A1 and B1. Consequently, A2 and B2 are loaded to the right buffer in the shared memory. The following tiles are processed similarly according to the double buffering scheme.