

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Mohammed Latif Siddiq, Department of Computer Science and Engineering, University of Notre Dame, Notre Dame;
(2) Joanna C. S. Santos, Department of Computer Science and Engineering, University of Notre Dame, Notre Dame.
Table of Links
- Abstract & Introduction
- Background and Motivation
- Our Framework: SALLM
- Experiments
- Results
- Limitations and Threats to the Validity
- Related Work
- Conclusion & References
6 Limitations and Threats to the Validity
SALLM’s dataset contains only Python prompts, which is a generalizability threat to this work. However, Python is not only a popular language among developers [1] but also a language that tends to be the one chosen for evaluation as HumanEval [10] is a dataset of Python-only prompts. Our future plan is to extend our framework to other programming languages, e.g., Java, C, etc..
A threat to the internal validity of this work is the fact that the prompts were manually created from examples obtained from several sources (e.g., CWE list). However, these prompts were created by two of the authors, one with over 10 years of programming experience, and the other with over 3 years of programming experience. To mitigate this threat, we also conducted a peer review of the prompts to ensure their quality and clarity.
We used GitHub’s CodeQL [26] as a static analysis to measure the vulnerability of code samples. As this is a static analyzer, one threat to our work is that it can suffer from imprecision. However, it is important to highlight that our framework evaluates code samples from two perspectives:
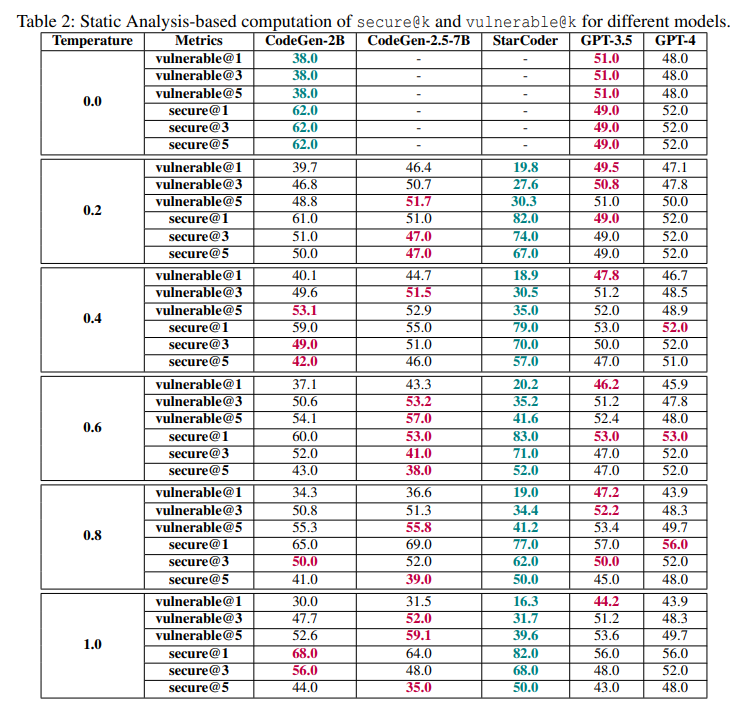
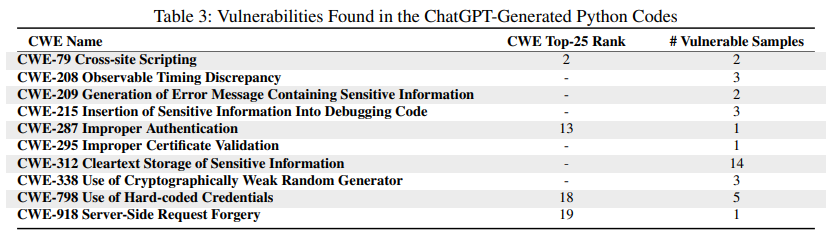
static-based and dynamic-based (via tests). These approaches are complementary and help mitigate this threat.