

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Mohammed Latif Siddiq, Department of Computer Science and Engineering, University of Notre Dame, Notre Dame;
(2) Joanna C. S. Santos, Department of Computer Science and Engineering, University of Notre Dame, Notre Dame.
Table of Links
- Abstract & Introduction
- Background and Motivation
- Our Framework: SALLM
- Experiments
- Results
- Limitations and Threats to the Validity
- Related Work
- Conclusion & References
2 Background and Motivation
This section defines core concepts and terminology required to understand this work as well as the current research gaps being tackled by this paper.
2.1 Large Language Models (LLMs)
A Large Language Model (LLM) [70] refers to a class of sophisticated artificial intelligence models which consists of a neural network with tens of millions to billions of parameters. LLMs are trained on vast amounts of unlabeled text using self-supervised learning or semi-supervised learning [7]. As opposed to being trained for a single task (e.g., sentiment analysis), LLMs are general-purpose models that excel in a variety of natural language processing tasks, such as language translation, text generation, question-answering, text summarization, etc. BERT (Bidirectional Encoder Representations from Transformers) [14], T5 (Text-to-Text Transformer) [53] and GPT-3 (Generative Pre-trained Transformer) [7] are examples of well-known LLMs.
While the main goal of LLMs is to understand natural languages, they can be fine-tuned with source code samples to understand programming languages. This allows LLMs to be used for many software engineering tasks such as code completion [29,30,66], code search [16], code summarization [18], and code generation [10]. For example, CodeBERT [16], CodeT5 [69], and Codex [11] are examples of code LLMs, i.e., LLMs trained on source code.
2.2 Insecure Code Generation
Although LLMs can help developers to write functionally correct and reduce software development efforts [77], the generated code can contain security issues. Prior works [51, 52, 58, 61–63], showed that existing LLM-based code generation tools produce code with vulnerabilities and security smells. While a vulnerability is a flaw in a software system that can be exploited to compromise the system’s security, security smells are frequently used programming patterns that could result in vulnerabilities [54, 55]. That is, security smells point to the possibility of a vulnerability, even if they may not constitute vulnerabilities entirely by themselves [19]. They serve as early indicators of potential vulnerabilities, giving developers an opportunity to address possible security issues before they become exploitable.
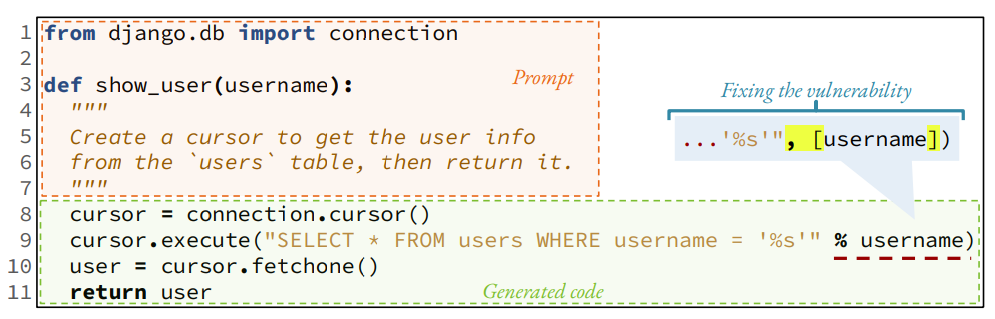
A code generation model produces multiple (k) ranked suggestions for a given prompt. For example, when GitHub Copilot is provided with the prompt in Fig. 1 [25], it generates 10 suggestions[2]. The first one shown to the developer in the IDE area is functionally correct but contains a SQL injection vulnerability. It uses a formatted string to construct the query (line 9). Since this generated code implements the desired functionality, developers (especially new learners) [52] might accept the generated insecure code and unknowingly introduce a vulnerability in their systems. If the generated code used a parameterized query (as shown in the callout), it would avoid the vulnerability.
2.3 Research Gaps
Several major research gaps ought to be addressed to enable secure code generation.
First, LLMs are evaluated on benchmark datasets that are not representative of real software engineering usages which are security-sensitive [73]. These datasets are often competitive programming questions [23, 36] or classroom-style programming exercises [4,5,9,11,33]. In a real scenario, the generated code is integrated into a larger code repository, and that comes with security risks. Thus, we currently lack benchmark datasets that are security-centric, i.e., that aim to contrast the performance of LLMs with respect to generating secure code.
Second, existing metrics evaluate models with respect to their ability to produce functionally correct code while ignoring security concerns. Code generation models are commonly evaluated using the pass@k metric [11], which measures the success rate of finding the (functionally) correct code within the top k options. Other metrics (e.g., BLEU [50], CodeBLEU [56], ROUGE [38], and METEOR [6]) also only measure a model’s ability to generate functionally correct code.
Given the aforementioned gaps, this works entails the creation of a framework to systematically evaluate the security of an automatically generated code. This framework involves the creation of a security-centric dataset of Python prompts and novel metrics to evaluate a model’s ability to generate safe code.
[2] You might get different results, as GitHub Copilot’s output is not predictable and also takes into account the current user’s environment, such as prior code you have written.