

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Anh Nguyen-Duc, University of South Eastern Norway, BøI Telemark, Norway3800 and Norwegian University of Science and Technology, Trondheim, Norway7012;
(2) Beatriz Cabrero-Daniel, University of Gothenburg, Gothenburg, Sweden;
(3) Adam Przybylek, Gdansk University of Technology, Gdansk, Poland;
(4) Chetan Arora, Monash University, Melbourne, Australia;
(5) Dron Khanna, Free University of Bozen-Bolzano, Bolzano, Italy;
(6) Tomas Herda, Austrian Post - Konzern IT, Vienna, Austria;
(7) Usman Rafiq, Free University of Bozen-Bolzano, Bolzano, Italy;
(8) Jorge Melegati, Free University of Bozen-Bolzano, Bolzano, Italy;
(9) Eduardo Guerra, Free University of Bozen-Bolzano, Bolzano, Italy;
(10) Kai-Kristian Kemell, University of Helsinki, Helsinki, Finland;
(11) Mika Saari, Tampere University, Tampere, Finland;
(12) Zheying Zhang, Tampere University, Tampere, Finland;
(13) Huy Le, Vietnam National University Ho Chi Minh City, Hochiminh City, Vietnam and Ho Chi Minh City University of Technology, Hochiminh City, Vietnam;
(14) Tho Quan, Vietnam National University Ho Chi Minh City, Hochiminh City, Vietnam and Ho Chi Minh City University of Technology, Hochiminh City, Vietnam;
(15) Pekka Abrahamsson, Tampere University, Tampere, Finland.
Table of Links
- Abstract and Introduction
- Background
- Research Approach
- Research Agenda
- Outlook and Conclusions
- References
4. Research Agenda
We grouped the research concerns and questions into eleven tracks based on the thematic similarities and differences of the questions. While this grouping is one of the several possible ways to create the categories, it served the purpose of easing the presentation and discussion of the research agenda, shown in Figure 4. For each category, we present (1) its historical context, (2) key RQs, (3) State-of-the-art, (4) current challenges and limitations, and (6) future prospects.
4.1. GenAI in Requirements Engineering
4.1.1. Historical Context.
Requirements Engineering (RE) plays a pivotal role in the success of software projects. Although numerous techniques exist to support RE activities, specifying the right requirements has remained challenging as requirements are seldom ready for collection in the initial stages of development [40]. Stakeholders rarely know what they really need, typically having only a vague understanding of their needs at the beginning of the project. These needs evolve during the project largely due to the dynamism inherent in business and software development environments [41]. Among Agile projects, RE has new challenges, such as minimal documentation, customer availability, lack of well-understood RE practices, neglecting non-functional requirements, lack of the big picture, inaccurate effort estimation and lack of automated support [42, 43]. Moreover, several other avenues in RE have remained relatively under-explored or under-developed, even in agile. These include, among others, the traceability and maintenance of requirements, stringent validation and verification processes, coverage of human factors in RE, ethical considerations while employing automation to RE or RE for AI software systems [44], coverage of domain specificity in requirements (e.g., stringent regulatory compliance for healthcare domain). RE, replete with its historical challenges and contemporary complexities, will need to adapt and evolve its role to the landscape of modern software development with technologies like GenAI, which alleviates some of these challenges [45].
4.1.2. Key RQs.
Regardless of the order in which RE tasks are performed or their application in either a waterfall or agile framework, the foundational RE stages and corresponding tasks remain consistent. This means that one still needs to identify stakeholders, elicit requirements, specify them in a format of choice, e.g., as user stories or shall-style requirements, analyze them, and perform other V&V tasks using them. Based on these considerations, we identified the following RQs.
1. How can GenAI support requirements elicitation?
2. How can GenAI effectively generate requirements specifications from high-level user inputs?
3. How can GenAI facilitate the automatic validation of requirements against domain-specific constraints and regulations?
4. How can GenAI be used to predict change requests?
5. What are the challenges and threats of adopting GenAI for RE tasks in different RE stages (pre-elicitation, elicitation, specification, analysis)?
4.1.3. State-of-the-art
Many research endeavors seek to utilize GenAI in order to automate tasks such as requirements elicitation, analysis, and classification. The current literature is dominant by preliminary empirical evidence of the significant role that LLMs in RE [46, 47, 48, 49, 50, 51, 52]. For instance, White et al. [46] introduced a catalog of prompt patterns, enabling stakeholders to assess the completeness and accuracy of software requirements interactively. Ronanki et al. [47] further substantiated this by comparing requirements generated by ChatGPT with those formulated by RE experts from both academia and industry. The findings indicate that LLM-generated requirements tend to be abstract yet consistent and understandable.
In addition to requirements elicitation, there’s also a focus on requirements analysis and classification. Zhang et al. [53] developed a framework to empirically evaluate ChatGPT’s ability in retrieving requirements information, specifically Non-Functional Requirements (NFR), features, and domain terms. Their evaluations highlight ChatGPT’s capability in general requirements retrieval, despite certain limitations in specificity. In agile RE practice, Arulmohan et al. [49] conducted experiments on tools like Visual Narrator and GPT-3.5, along with a conditional random field (CRF)-based approach, to automate domain concept extraction from agile product backlogs. Their work provides evidence of the advancements in automating domain concept extraction. Both Ezzini et al. [2022] [50] and Moharil et al. [2023] [51] have tackled issues pertaining to anaphoric ambiguity in software requirements. Anaphoric ambiguity emerges when a pronoun can plausibly reference different entities, resulting in diverse interpretations among distinct readers [50]. Ezzini et al. [2022] [50] have developed an automated approach that tackles anaphora interpretation by leveraging SpanBERT. Conversely, Moharil et al. [2023] [51] have introduced a tool based on BERT for the detection and identification of ambiguities. This tool can be utilized to generate a report for each target noun, offering details regarding the various contexts in which this noun has been employed within the project. Additionally, De Vito et al. [54] proposed the ECHO framework, designed to refine use case quality interactively with ChatGPT, drawing from practitioner feedback. The findings indicate the efficacy of the approach for identifying missing requirements or ambiguities and streamlining manual verification efforts. BERT-based models have also been applied in RE to improve the understanding of requirements and regulatory compliance via automated question-answering [55, 56].
Hey et al. [2020] [57] introduced NoRBERT, which involves fine-tuning BERT for various tasks in the domain of requirements classification. Their findings indicate that NoRBERT outperforms state-of the-art approaches in most tasks. Luo et al. [2022] [58], in a subsequent study, put forward a prompt-based learning approach for requirement classification using a BERTbased pre-trained language model (PRCBERT). PRCBERT utilizes flexible prompt templates to achieve accurate requirements classification. The conducted evaluation suggests that PRCBERT exhibits moderately superior classification performance compared to NoRBERT. Additionally, Chen et al. [59] evaluated GPT-4’s capabilities in goal modeling with different abstraction levels of information, revealing its retained knowledge and ability to generate comprehensive goal models.
4.1.4. Challenges and Limitations
Automation of RE tasks with GenAI techniques is undoubtedly promising; however, it is paramount for practitioners to be aware of several risks to ensure a judicious blend of domain and RE expertise and AI’s capabilities. Hallucination is a common challenge for adopting GenAI for all RE activities. GenAI techniques might generate requirements that appear sound but are either superfluous, incorrect, or inconsistent in a given domain context. Such inconsistencies can inadvertently lead to projects straying off course if not meticulously reviewed by stakeholders with relevant experience. Furthermore, some RE tasks (e.g., traceability) would require fine-tuning LLMs to the task data, but historically, not much RE data is publicly available to finetune these models accurately. We present some challenges and limitations of GenAI models regarding each RE stage, as below: Pre-Elicitation Stage: While LLMs can use preliminary research materials such as existing systems, universal documents, and app reviews to automate domain and stakeholder analysis, they sometimes fail to capture the broader context. Inaccurate identification of key domain concepts or overlooking intricate relationships can lead to suboptimal domain models.
Elicitation Stage: LLMs can process interview transcripts, survey responses, and observation notes to aid in the requirements elicitation process. However, the inherent biases of LLMs can affect the coding, analysis, and summarization of this data, potentially leading to skewed requirements.
Specification Stage: LLMs offer automated generation and classification of requirements. However, these generated requirements can sometimes lack clarity or coherence without proper human oversight. The reliance on LLMs for regulatory compliance or requirements prioritization might also result in overlooking important nuances in legal or organizational guidelines.
Analysis Stage: Using LLMs for requirements quality analysis, traceability, and change management can automate and streamline the RE process. However, LLMs might sometimes struggle with intricate defect detection, traceability challenges, or handling complex change scenarios, leading to gaps in the analysis.
Validation Stage: Generative models often lose the broader context, especially with intricate requirements, potentially leading to discrepancies or conflicts within the generated requirements. The onus then lies on SE teams to validate such AI-generated requirements or other automated outputs, introducing an additional layer of complexity and potential validation challenges.
Overall, the ethical and security ramifications of delegating pivotal RE tasks to AI also warrant attention, mainly in safety-critical systems or application domains such as healthcare, defense, or cybersecurity. Lastly, a challenge that spans beyond just RE is the potential bias and fairness issues. If unchecked, generative models can perpetuate or even intensify biases in their foundational data. This can lead to skewed requirements that might not represent the diverse needs of end-users [60].
4.1.5. Future Prospects.
The future holds intriguing prospects regarding automating most RE tasks and making requirements engineers’ lives easier. We believe that the future way of working will be AI-human collaborative platforms where GenAI assists domain experts, requirements engineers, and users in real-time, allowing for instantaneous feedback loops and iterative refining of requirements might be the new norm [61]. Such platforms could also offer visualization tools that help stakeholders understand how the AI interprets given inputs, fostering a more transparent understanding of system requirements and the generated outputs. We expect to witness LLMs capable of deeper contextual understanding, reducing inaccuracies in the pre-elicitation and elicitation stages. An important prospect would be allowing fine-tuning of models without exposing sensitive information from requirements (i.e., data leakage). Considering the ethical and safety concerns, there is an evident need for establishing robust frameworks and guidelines for the responsible use of AI in RE. In the near future, the research could be directed at creating models with built-in ethical considerations capable of addressing the known biases, ensuring that the generated requirements uphold the standards and are truly representative and inclusive.
4.2. GenAI in Software Design
4.2.1. Historical Context
Design and architecture decisions are at the core of every software system. While some well-known structures are easy to replicate and create templates, some decisions need an evaluation of the trade-offs involved, especially on how these decisions affect the system’s quality attributes. In this context, choosing the pattern or solution is just the last step of the process, which requires identifying all factors that influence and might be affected by the decision. We can find in the literature several works that proposed solutions to automate design decisions, mainly based on the choice of patterns, such as based on questions and answers [62], based on anti-patterns detection [63], based on text classification [64], and based on ontologies [65]. However, it is a fact that these approaches are not yet widely used in industry, and GenAI is attracting interest from professionals as a promising approach to be adopted for design decisions in real projects.
4.2.2. Key RQs
Similar to Requirements Engineering, it is necessary to explore the possible adoption of GenAI in all software design activities. As listed below, we present RQs addressing specific software design activities to illustrate open challenges in GenAI and software design:
1. How can GenAI assist in identifying and selecting appropriate design and architectural patterns based on requirements and constraints?
2. What strategies can be adopted to promote collaboration for decisionmaking between professionals and GenAI in the software design process?
3. What are the limitations and risks associated with using GenAI in software design, and how can these be mitigated to ensure their reliability and validity?
4. How can GenAI be employed in a continuous software design process, automating the identification of improvements and refactoring to optimize key quality attributes?
5. How can generative AI be utilized to automate the design and implementation of user interfaces, improving user experience in software applications?
6. How can GenAI optimize the trade-offs between different quality attributes, such as performance, scalability, security, and maintainability?
7. What strategies can be employed to enable GenAI to adapt and evolve system architectures over time, considering changing requirements, technologies, and business contexts?
4.2.3. State-of-the-art
We do not find many papers exploring GenAI or LLM for software design activities. Ahmad et al. described a case study of collaboration between a novice software architect and ChatGPT to architect a service-based software [66]. Herold et al. proposed a conceptual framework for applying machine learning to mitigate architecture degradation [67]. A recent exploratory study evaluated how well ChatGPT can answer that describes a context and answer which design pattern should be applied [68], demonstrating the potential of such a tool as a valuable resource to help developers. However, in the cases where ChatGPT give a wrong answer, a qualitative evaluation pointed out that the answer could mislead the developers. Stojanovi´c et al. presented a small experiment where ChatGPT identified microservices and their dependencies from three pieces of system descriptions [69]. Feldt et al. proposed a hierarchy of design architecture for GenAI-based software testing agents [70].
4.2.4. Challenges and Limitations
The challenges of GenAI in software design go beyond just receiving the correct answer for a design problem. It is essential to understand what role it should play and how it will interact with the software developers and architects in a team. Considering that design decisions happen at several moments during a project, it is also important to understand how a GenAI can be integrated into that process.
A limitation of the current literature on the topic is the lack of studies in real and industrial environments. While the techniques were experimented with in a controlled environment, it is still unknown how useful they can really be in practice. While studies show that the usage of AI can provide correct answers to software design problems with good accuracy, inside a real project environment, it is still a challenge to understand which information needs to be provided and if the answer can really be insightful and not just bring information that the team already knows. While the recent works delimit the scope in a limited set of patterns, usually the classic Gang of Four (Gof) patterns [71], for industrial usage, answers are expected to consider a wide spectrum of solutions. Considering the findings of a recent study that exposed several problems in how non-functional requirements are handled [72], real projects might not have all the information needed as input for a GenAI tool to give an accurate answer.
4.2.5. Future Prospects
With access to tools that can give useful answers, the key challenge for the future of GenAI in software design is how GenAI tools will fit into the existing processes to enable its usage more consistently. Considering that the design of the architecture happens continuously, using these tools only as an oracle to talk about the solutions as a personal initiative might be an underutilization of its potential. To address the RQs in this domain, it is imperative to comprehend the roles GenAI tools can assume in the software design process and the approaches for engaging with them using prompt patterns, as discussed in [73]. It is expected that new good and bad software design practices will soon emerge from the first experiences with this kind of tool.
4.3. GenAI in Software Implementation
4.3.1. Historical Context
Software implementation is the crucial phase where the designed solution is transformed into a functional working application. With the advent of object-oriented programming in the 1990s, software systems have rapidly grown in size and complexity. Automation is an important research direction to increase productivity while ensuring the quality of software code. Modern Integrated Development Environments (IDEs) with features, i.e. compiling, deploying, debugging and even code generating, are continuously evolving to maximize the support for software developers.
However, implementing software systems in industries today presents several challenges. First, there is the constant pressure to keep up with rapidly evolving technology, which often leads to compatibility issues with legacy systems. Second, ensuring security and data privacy has become increasingly complex as cyber threats continue to evolve. Third, scalability and performance optimization are critical as software systems must handle growing amounts of data and users. Lastly, the shortage of skilled software engineers and the rising cost of software development further exacerbate these challenges. Thus, successful software implementation requires careful planning, ongoing maintenance, and adaptability to stay ahead in today’s competitive technological landscape.
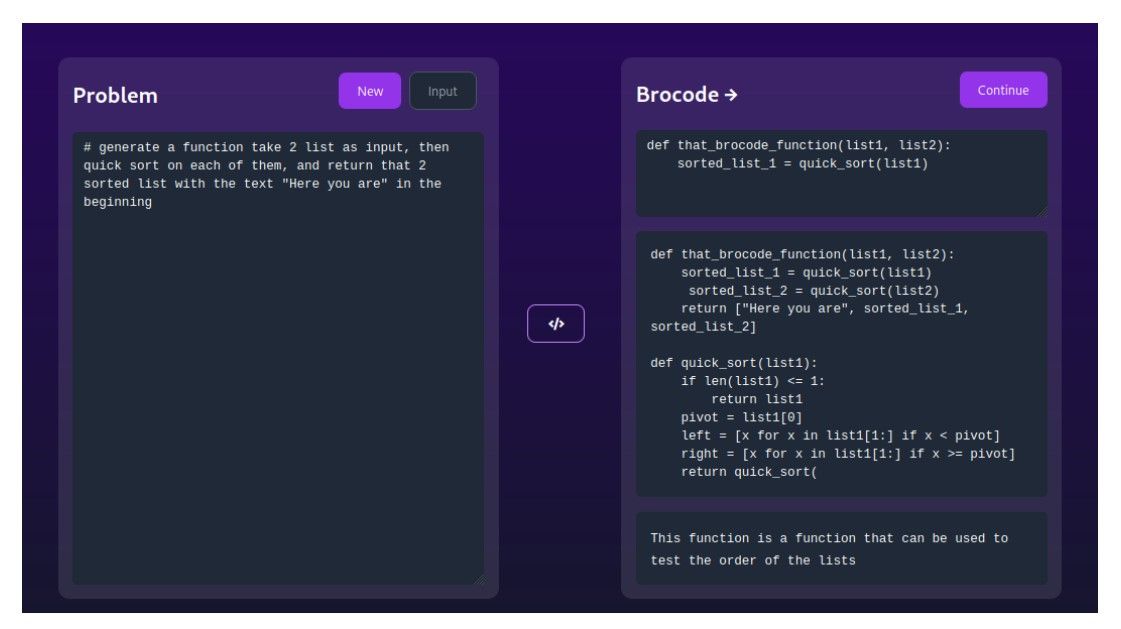
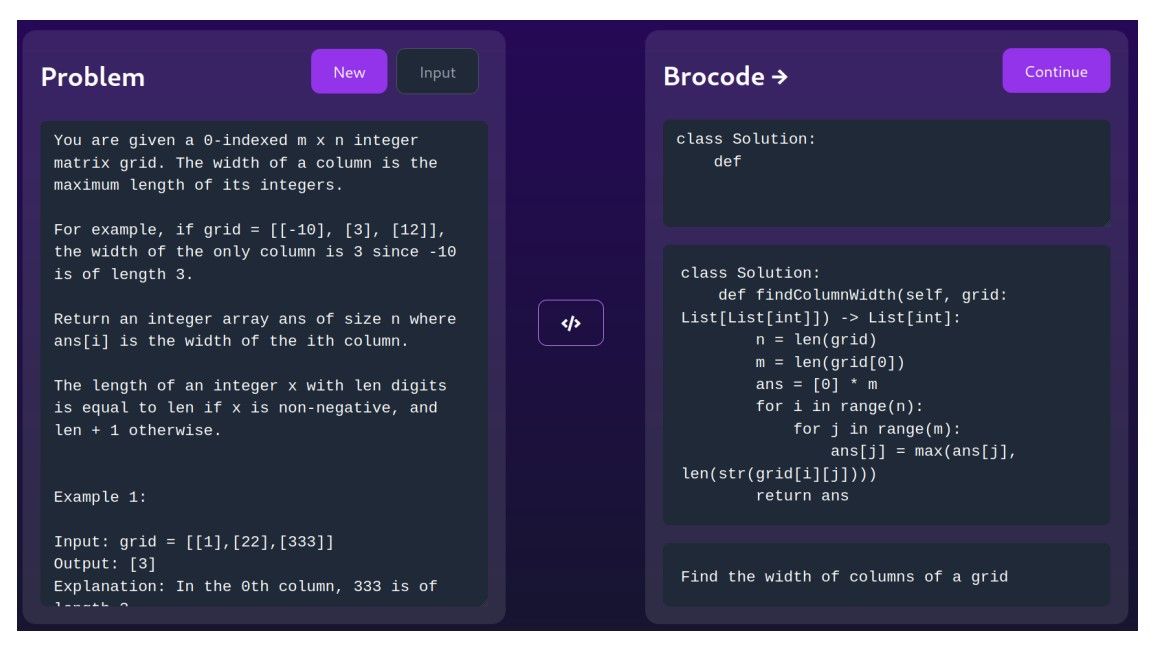
Code generation stands as a crucial challenge in both the field of GenAI and the software development industry. Its objective is to automatically generate code segments using requirements and descriptions expressed in natural language. Addressing this challenge can yield a multitude of advantages, including streamlining the programming process, improving the efficiency and accuracy of software development, reducing the time and effort required for coding, and ensuring the uniformity and correctness of the generated code. To showcase the capability of code generation, we requested ChatGPT with a simple task:” Create a function that takes two arrays as input, then performs the quick sort algorithm on each array and returns the results of the two sorted arrays with the phrase ’Here you go’.” (Figure 5) To complex requests, such as a new algorithm problem taken from Leetcode. (Figure 6). The result is a complete solution that, when submitted, is correct for all test cases on Leetcode8.
4.3.2. Key RQs
Considering the challenges identified for modeling and training GenAI architecture in the field of Software Implementation, We highlight particular RQs (RQs) related to the process of building a model that can be used in a real-world industrial environment
1. To what extent GenAI-assisted programming, i.e. code summarization, code generation, code completion, comment generation, code search, and API search can be effectively integrated into practical software development projects?
2. How can GenAI models be specialized for specific software domains, such as web development, game development, or embedded systems, to generate domain-specific code more effectively?
3. How to ensure the correctness and reliability of generated results, carefully consider the potential for hidden malicious output that we are unaware of?
4. How can software companies both leverage the capacity of LLMs and secure their private data in software development?
5. Does the outcome generated by a GenAI model have a significant bias towards the knowledge learned from LLMs while overlooking important input segments from private datasets of an enterprise?
6. How can the system effectively specify user intent when users communicate by progressively providing specifications in natural language
7. How can GenAI model be built, trained and retrained for a cost-based performance in various types of software implementation tasks? [74] [75]
8. What needs to be done to achieve a Natural Language Interface for Coding where non-IT people can also interact and develop their wanted software?
9. What methods can be employed to validate AI-generated code against functional and non-functional requirements?
10. How can we ensure GenAI models comply with certain legal and regulation constraints [76] [77] ?
4.3.3. State-of-the-art
Developing code in an efficient, effective, and productive manner has always been an important topic for SE research. Since 2020, there has been extensive research about LLMs for various coding tasks, such as code generation, code completion, code summarization, code search, and comment generation. Various studies investigate the code generation performance of GitHub Copilot in different work contexts and across different Copilot versions, e.g., [78, 79, 80]. Jiang et al. proposed a two-step pipeline that use input prompts to generate intermediate code, and then to debug this code [81]. The approach is promising to bring consistent efficacy improvement. Dong et al. treated LLMs as agents, letting multiple LLMs play distinct roles in addressing code generation tasks collaboratively and interactively [82]. Borji et al. presented a rigorous, categorized and systematic analysis of LLM code generation failures for ChatGPT [83]. Eleven categories of failures, including reasoning, factual errors, mathematics, coding, and bias, are presented and discussed in their work. Sun et al. focus on users’ explainability needs for GenAI in three software engineering use cases: code generation based on natural language description (with Copilot), translation between different programming languages (with Transcoder), and code autocompletion (with Copilot) [84].
Several studies attempt to compare different code generation tools. Li et al. proposed an approach called AceCoder that surpasses existing LLMbased code generation tools, i.e. CodeX, CodeGeeX, CodeGen, and InCoder on several benchmarks [85]. Doderlein et al. experimented with various input parameters for Copilot and Codex, finding that varying the input parameters can significantly improve the performance of LLMs in solving programming problems [3]. Yetistiren et al. [74] presented a comprehensive evaluation of the performance of Copilot, CodeWhisperer, and ChatGPT, covering different aspects, including code validity, code correctness, code security, and code reliability. Their results show a wide degree of divergence in performance, motivating the need for further research and investigation [86]
Salza et al. presented a novel LLM-driven code search approach by pre-training a BERT-based model on combinations of natural language and source code data and fine-tuning with data from StackOverflow [87]. Chen et al. explored the setting of pre-train language models on code summarization and code search on different program languages [88]. Guo et al. developed a model named CodeBERT with Transformer-based neural architecture for code search and code generation [89]. The model has been widely popular and serves as a baseline for a lot of LLM driven code generation approaches. For instance, Guo et al. proposed a model called GraphCodeBERT, a pretrained model for programming language that considers the inherent structure of code. GraphCodeBert uses data flow in the pre-training stage and is texted on code search and code generation [90]. Code retrieval, a practice to reuse existing code snippets in open source repositories [91], is also experimented GenAI. Li et al. proposed a Generation-Augmented Code Retrieval framework for code retrieval task [92].
Automatic API recommendation is also a sub-area of LLM applications. Wei et al. proposed CLEAR, an API recommendation approach that leverages BERT sentence embedding and contrastive learning [93]. Zhang et al. [387] developed ToolCoder, which combines API search tools with existing models to aid in code generation and API selection [94]. Patil et al. [95] developed a tool called Gorilla. This is a fine-tuned LLaMA-based model that is able to interact and perform with API, i.e. API call and verification.
Comment generation is also an active research area, as source code is not always documented, and code and comments do not always co-evolve- [96]. Mastropaoplo et al. studied comment completion by validating the usage of Text-To-Text Transfer Transformer (T5) architecture in autocompleting a code comment [96]. Geng et al. adopted LLMs to generate comments that can fulfill developers’ diverse intents [97]. The authors showed that LLM could significantly outperform other supervised learning approaches in generating comments with multiple intents.
Several works have been done in an industrial setting. Vaithilingam et al. [98] explored how LLMs (GitHub Copilot) are utilized in practice in programming, finding that even though they did not necessarily increase work performance, programmers still preferred using them. Barke et al. [99],
in a similar study of how programmers utilize LLMs, highlighted two use modes: acceleration (next action is known and LLM is used to code faster) and exploration (next action is unknown and LLM is used to explore options). Denny et al. showed that Copilot could help solve 60 percent of programming problems and a potential way to learn writing code [2]. Ziegler et al. [100] explored potential measures of productivity of LLM use in programming, finding that the ”rate with which shown suggestions are accepted” is a metric programmers themselves use to gauge productivity when utilizing LLMs.
Ouyang et al. empirically studied the nondeterminism of ChatGPT in code generation and found that over 60% of the coding tasks have zero equal test output across different requests [5]. Pearce et al. discussed potential security issues related to code generated with GitHub Copilot [101]. Finally, in terms of programming practices, the use of LLM-based assistants such as GitHub copilot is often likened to pair programming [102, 79].
4.3.4. Relevant technologies
The flow of constructing the code generation model is depicted in Figure 7. As seen, the flow of the automatic code generation system is defined as follows:
Step 1: Research and utilize LLMs that have the best performance and an appropriate number of parameters for tasks related to automatic code generation and code summarization. In this case, the author employs two models: CodeGen-6B-Mono for code generation (Generation) and CodeT5-Large for code summarization.
Step 2: Implement methods to optimize parameter fine-tuning on specific private datasets or carefully select public datasets that were not part of the training set of the initial large models (downstream datasets). Here, the author uses the LoRA method and the HuggingFace Peft library5 to handle the two defined downstream tasks.
Step 3: Store the trained model and develop a user interface, enabling users to interact and experience automatic code generation and summarization based on the initial specific dataset.
Step 4: Develop secure storage mechanisms for user-specific projects and continue training on new user datasets.
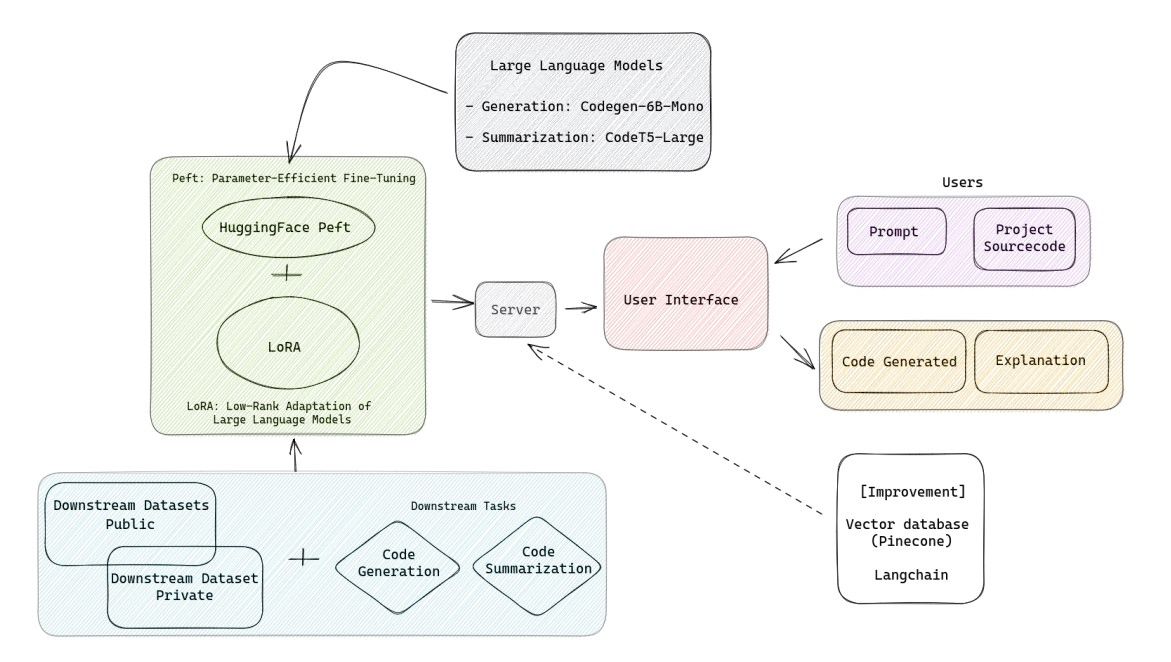
4.3.5. Challenges and Limitations
Challenges and Limitations of current GenAI applications on software implementation can be presented under three aspects: (1) expressiveness, (2) program complexity, and (3) security and specification requirements.
Heterogeneous inputs For an AI generation system to function effectively, the first unavoidable challenge is understanding the input requirements. The system needs to analyze and grasp specific requirements, determining what it needs to generate to satisfy those particular demands. Users’ intentions can be expressed in heterogeneous manners, i.e. specifying logical rules, using input-output examples, or describing in natural language. Addressing all logical rules comprehensively is demanding, while input-output examples often don’t sufficiently describe the entire problem. It can be argued that the ability to recognize and articulate user intentions is the key to the success of automated code generation systems, a challenge that traditional approaches have yet to solve.
Model Size With the increasing size and complexity of codebases and the emergence of numerous new technologies, understanding and generating code is also becoming more and more complex. GenAI model might need to include more and more dimensions, making it impractical and unrealistic for most people to fine-tune large models for smaller tasks. It’s turning into a race dominated by big global tech corporations. Notable applications such as ChatGPT, Microsoft’s Github Copilot], Google’s Bard, and Amazon’s Code Whisperer share a common goal: harnessing AI to make programming more accessible and efficient. This race is intensifying. In May 2023, HuggingFace launched its LLM BigCode [110], while Google announced its enhanced PaLM-2 model. Both made astonishing advancements, competing directly with Microsoft’s famous GPT models. Recently, in August 2023, Facebook announced Code LLaMa, which is expected to give the open-source community easier access to this exciting race.
Security and Specification Requirements Security is also a major challenge for GenAI systems. Due to their vast and comprehensive knowledge base, they are in a position where they ”know everything, but not specifically what.” Alongside this, there’s an increasing need for code security and very specific logical inputs in real-world scenarios. Consider not retraining the GenAI system with the code and knowledge of a specific (private) project but instead applying general knowledge to everyday tasks in the Software Industry. It can be easily predicted that the system won’t be able to generate code satisfying complex real-world requirements. Applying the specific logic of each company’s security project requires the system to grasp not just general knowledge but also the business and specific logic of each particular project. However, suppose an organization or individual tries to retrain a LLM on their project’s source code. This is not very feasible. First, training an LLM requires robust hardware infrastructure that most individuals or organizations cannot guarantee. Secondly, the training time is usually significant. Lastly, the result of training is a massive weight set, consuming vast storage space and operational resources. Resources and efforts spent on training multiple different projects can be wastefully redundant, especially when users only need the model to work well on a few specific, smaller projects. On the contrary, focusing on training specific projects from the outset means we can’t leverage the general knowledge LLMs offer, leading to lower-quality generated code. Thus, the author believes that while automated code generation might work well for general requirements using LLM, there remain many challenges when applying them to specific and unique projects. To address these challenges, recent years have seen numerous studies dedicated to discovering methods to fine-tune LLM using parameter optimization methods. Most of these approaches share a goal: applying general knowledge to specific problems under hardware constraints while retaining comparable efficiency and accuracy.
4.3.6. Future Prospects
The intrinsic appeal of GenAI on a global scale is undeniable. Ongoing research endeavors are significantly focused on enhancing optimization techniques and LLMs to yield forthcoming generations of GenAI models characterized by heightened potency, user-friendliness, rapid trainability, and adaptability to specific projects or downstream applications. Adaptive GenAI-based tools, such as PrivateGPT 9, an enclosed ChatGPT that encapsulates comprehensive organizational knowledge, have surfaced and garnered substantial community support. Another tool, MetaGPT 10 illustrates a vision where a software development project can be fully automated via the adoption of role-based GPT agents.
For the first time in history, programming is becoming accessible to a broad spectrum of individuals, including those lacking a formal background in Software Engineering (SE). GenAI will offer opportunities to democratize coding, enabling individuals from diverse backgrounds to partake in software development. With its intuitive interface and robust automation capabilities, GenAI serves as a conduit for individuals to unlock their creative potential and manifest innovative concepts through coding, irrespective of their prior technical acumen. This inclusive approach to programming not only fosters a more diverse and equitable technology community but also initiates novel avenues for innovation and complex problem-solving within the digital era.
The current AI landscape parallels the challenges inherent in edge machine learning, wherein persistent constraints related to memory, computation, and energy consumption are encountered. These hardware limitations are being effectively addressed through established yet efficacious technologies such as quantization and pruning. Concomitant with these hardware optimizations, there is a notable rise in community involvement, affording opportunities for research groups beyond the purview of major technology corporations. This augurs the imminent development of groundbreaking GenAI products finely tailored for the software industry.
4.4. GenAI in Quality Assurance
4.4.1. Historical Context
Software Quality Assurance (SQA) activities are imperative to ensure the quality of software and its associated artifacts throughout the software development life-cycle. It encompasses the systematic execution of all the necessary actions to build the confidence that the software conforms to the implied requirements, standards, processes, or procedures and is fit for use[111]. The implied quality requirements include, but are not limited to, functionality, maintainability, reliability, efficiency, usability, and portability. Often, SQA and software testing are used interchangeably when software quality is concerned. However, both these terms are intricately intertwined[111]. While SQA is a broader domain, testing remains a key and integral part of it, executing the software to detect defects and issues associated with quality requirements. Testing is widely practiced in the software industry despite the fact that it is considered an expensive process.
The testing process begins with understanding the requirements and generating test case requirements thereafter. Depending on the software system under test, software development life cycle in practice and implied requirements, various types of tests are usually conducted. These include but are not confined to (functional) unit testing, integration testing, system testing, acceptance testing, and finally, testing the (required) quality attributes as per the non-functional requirements.
Through a recent and extensive survey[112], several key challenges related to SQA and testing are disseminated by the SQA community. Development of automated tests, limited time, budget, and human resources, inadequacies of SQA training, adapting SQA to contemporary and evolving software development workflows, and understanding requirements before coding are among the key challenges. A similar list of challenges is presented in another study[113]. It reports that traditional methods of testing, and test case design consume a significant amount of energy, time and human resources. For Yuan et al.[114], generating tests manually, according to the existing practices, is laborious and time-consuming. As a result, the efficiency of conducting these activities becomes low while the extent and intensity of these activities also rely on the experience of the SQA professionals[113].
These challenges make it hard to meet the increasing demand for SQA and testing across software companies. On the other hand, recent advancements in GenAI, especially in automatic code generation through LLMs, demand a significant transformation in how SQA functions within the current paradigm. Reduced time and resources required to perform SQA functions by automating various activities are among the evident benefits of utilizing GenAI for SQA. In fact, one of the existing obstacles faced by the SQA community is the flaws in the test data that make automated test sets fail for software systems[112]. Utilizing GenAI in SQA to generate diverse test data based on specified requirements, scenarios, and use cases effectively addresses these challenges. Moreover, GenAI has the potential to generate insights from the analysis of existing test data, enabling the SQA community to produce more reliable software systems effectively and efficiently.
4.4.2. Key RQs
In light of the challenges faced by the SQA community, we propose several key questions for using GenAI in software quality. The questions include:
1. To what extent GenAI can replace developers in code reviews?
2. Can GenAI help to produce test cases and test scenarios from Software Requirements Specification (SRS)?
3. Are there common error patterns of AI-generated code?
4. How GenAI can be integrated effectively into quality assurance pipelines?
5. How can GenAI be utilized to automate acceptance criteria from highlevel requirements?
6. How can GenAI be used to aid the creation of diverse and effective test suites for software testing?
7. How can GenAI assist in maintaining and updating test cases in case of requirement changes?
8. What strategies can be employed to ensure that the generated test cases by GenAI are reliable, effective, and representative of real-world usage scenarios?

4.4.3. State-of-the-art
Considering the challenges faced within this domain, a large number of studies have been conducted to explore, propose and evaluate different QA approaches. The adoption of AI also has a long history in software quality research. Primarily, AI has been utilized in automating and optimizing tests, predicting faults, and maintaining software quality[115]. With the recent advancement in AI models, GenAI might support various SQA activities. However, existing GenAI models (e.g. ChatGPT) are not particularly trained to perform these specialized jobs. Thus, they might offer limited performance when applied to particular situations[116]. Nevertheless, these recent breakthroughs in the field have invited several researchers to find possible ways to address the challenges faced by the SQA community and tailor and evaluate existing models for SQA tasks. Regarding this, we report a number of studies that are aimed at understanding and evaluating the use and effectiveness of GenAI models in specialized settings.

Jalil et al. [116] explored the use of GenAI to educate novice software test engineers. The authors reported that LLMs, like, for instance, ChatGPT have been able to respond to 77.5% of the testing questions while 55.6% of the provided answers were correct or partially correct. The explanations to these answers were correct by the of 53%. With these percentages in mind, it has been ascertained that prompting techniques and additional information in queries might enhance the likelihood of accurate answers[116]. Ma et al.[117] agreed with this by pointing out that the prompt design significantly impacts the performance of GenAI models. In this context, White et al [118] proposed various prompt patterns to improve code quality and perform testing while interacting with GenAI models.
Akbar et al. [119] reported the possible uses of GenAI models for software quality and testing. Yuan et al.[114] showed the potential of LLMs in unit test generation, which is among the most popular test phases in testing after model-based testing [120]. Similarly, it is also ascertained that GenAI models can be optimized to simulate various testing activities like, for instance, testing usability-related requirements of software systems[119]. As a result, software companies can save time and resources[116][114] and simultaneously improve the software quality and performance[119]. In addition, based on the literature survey, the study[119] also identifies several factors that can make an organization adopt GenAI models for testing and software quality. These factors include the generation of software test data, the capability to fine-tune these models for SQA tasks, generating test scenarios, bug reporting, automated reporting on the performance and software quality, and the tailored use of these models as testing assistants. Keeping these enablers in mind, we observed that the current literature provides no clear guidelines on how to achieve the objectives of using GenAI in SQA.
Liu et al.[113], in their recent study, attempted to leverage the capabilities of ChatGPT for testing purposes and developed a system for automated test case generation using ChatGPT. They report interesting comparisons between manually constructing test suites and generating them through ChatGPT. According to the experimental results of the study [113], the efficiency in generating test suits through their ChatGPT-based system exceeds 70%. The new system uses ChatGPT as an intelligent engine to do the job. In contrast to Liu et al.[113], Yuan et al. [114] claimed that only 24.8% of tests generated by ChatGPT were executed successfully. The remaining tests suffered from correctness issues[114][121]. Most of these issues include compilation errors (57.9%) followed by incorrect assertions (17.3%). While on the other hand, Yuan et al. [114] found that the tests generated by ChatGPT are similar to human-generated tests with a sufficient level of readability and cover the highest test coverage.
While discussing the scope of ChatGPT for code analysis, Ma et al. [117] used a significant number of codes and concluded that ChatGPT is great at understanding code syntax. However, it fails to fully comprehend dynamic semantics. The experimental evaluation of this study also demonstrates the GenAI model’s limited ability to approximate dynamic behaviors.
Lastly, in a large-scale literature review, Wang et al. [121] collected and analyzed 52 empirical and experimental studies on the use of GenAI LLMs for software testing. The authors reported commonly employed LLMs, and software testing tasks that can be accomplished through LLMs. In this regard, test case preparation and program repair remained the two most commonly explored areas of prior investigations[121]. Other areas include test oracle generation, bug analysis, debugging, and program repair. On the contrary, CodeX, ChatGPT, codeT5, CodeGen and GPT-3 are commonly utilized models by researchers to verify and validate particular but a few aspects of the software quality.
4.4.4. Challenges and Limitations
Like software implementation, the utility of GenAI models for SQA activities is fully potential, but also challenging. The above studies show the illustrative use of GenAI in assessing code quality, analyzing both human and AI-generated code, conducting code reviews, and generating tests and test data. Nevertheless, inadequacies of current models do exist e.g. to assess the dynamic behavior of the code, human intervention to identify the hallucination, when dealing with code semantic structures and non-existent codes. Therefore, despite the promising benefits that GenAI offers to SQA, there is a need to evolve the existing methodologies, tools, and practices. We present some of the challenges and limitations of GenAI for SQA extracted from the literature review:
• The tests generated by GenAI models currently demonstrate issues related to correctness, hallucination, and a limited understanding of code semantics[113][117][122]. These challenges are particularly notable in comprehending the dynamic behavior of the code. In addition, these challenges highlight the need for tremendous training data to refine models to perform specialized SQA tasks[119][? ]. The training requires investing a significant amount of resources, which might not be a feasible option for all software development companies[123]. These issues make the limited practicality of GenAI models in their current state, within the SQA context.
• Biasness in the training data may also affect the potential behavior of GenAI models towards SQA activities[119]. As a result, human intervention for manual correction or identification of vulnerabilities remains mandatory. Alongside this, biases in the training data might raise ethical issues or lead to a negative impact on software quality.
• Output of GenAI models is highly associated with the prompting techniques[? ][118]. Providing more information or additional context of testing or quality might result in a better or improved answer. It further requires researchers to design proper prompt engineering techniques for SQA professionals.
• Almost all of the existing studies on the topic(e.g. [? ][113][117][114]) are mostly experimental studies and thus do not take into consideration the industrial context. Therefore, how GenAI models deal with real-world software quality issues remains a mystery. We need more real-world case studies and industrial examples to understand the effectiveness of various tasks of SQA with GenAI. Moreover, it would be interesting to study how well GenAI enhances the productivity of SQA professionals.
4.4.5. Future Prospects
The existing studies stimulate the potential of utilizing GenAI in assessing software quality and thus demand reshaping the traditional SQA implementation methods, practices, and tools. Shortly, we foresee a significant number of studies within this domain. Therefore, based on the existing understanding of the use of GenAI in this domain and considering the challenges and limitations faced, we propose several possible avenues for forthcoming research studies:
Exploring GenAI for Further SQA Tasks: Future research might investigate conducting and evaluating early activities of SQA through GenAI. This includes creating a complete test plan or generating test requirements based on SRS. However, automating this process would still require a human expert to validate the outcome because these activities rely heavily on domain knowledge. The alternative way to achieve this could be training the GenAI models with relevant domain data[121].
Likewise, much of the existing literature studied functional testing followed by security testing in terms of finding vulnerabilities and asking for bug repair[121]. We found only one study [119] that alludes to the use of GenAI to test usability requirements. However, even in this case, the practices are not obviously described. Similarly, other areas of testing are not currently the focus of existing studies, i.e. acceptance testing, integration testing, and testing other software quality requirements like performance, reliability, efficiency, and portability. Therefore, future research on these SQA activities would be useful to show the effectiveness and limitations of existing GenAI models.
Exploring the Impact of Prompt Strategies :Further research is also required to evaluate the effect of prompt strategies on GenAI to accomplish particular SQA tasks. The existing studies only employed four prompt engineering techniques so far, out of 12 [121]. The effect of prompting on the GenAI models is also acknowledged by other studies e.g. [118][117][119]. Therefore, a future prospect might be to identify effective prompting strategies for a particular task, such as unit test code generation.
Utilizing Latest GenAI Models: Wang et al. [121] found that Codex and ChatGPT are two largely explored GenAI models to assess the usefulness of GenAI for SQA activities. However, as expected, we do not find any study utilizing the latest version of ChatGPT i.e. ChatGPT 4.0. Therefore, investigating the use of the latest GenAI model might produce different performance results for varying SQA activities. Using a different dataset and a different GenAI model would offer a different effect on the performance results.
4.5. GenAI in Maintenance and Evolution
4.5.1. Historical Context
Software maintenance encompasses all the activities involved in managing and enhancing a software system after it has been deployed, ensuring the system’s continued quality in responding to changing requirements and environments [124]. As software maintenance is an expensive activity that consumes a considerable portion of the cost of the total project [125, 124], software systems should be developed with maintainability in mind. Unfortunately, software maintainability is frequently neglected, resulting in products lacking adequate testing, documentation, and often being difficult to comprehend. Therefore, to maintain a software system, one must usually rely on the knowledge embodied and embedded in the source code [124]. In practice, software engineers spend a lot of time understanding code to be maintained, converting or translating code from one environment to another, and refactoring and repairing code. This is also an area with intensive research on the application of GenAI.
4.5.2. Key RQs
Excluding open challenges in code generation or quality assurance, which have already discussed in previous sections, we present below RQs that are specific to software maintenance tasks, i.e., code translation, refactoring, and code repair:
1. How to improve code correctness in code translation tasks?
2. How can GenAI be leveraged to migrate an entire codebase to another language or framework?
3. How can GenAI be leveraged to refactor a monolithic system into its microservices counterpart?
4. How can GenAI support automatic program repair?
5. How to integrate multiple LLMs or combine LLMs with specialized traditional ML models to leverage the collective strengths for automatic program repair?
6. How can GenAI be leveraged to automate code smells and anomaly detection, facilitating the early identification and resolution of issues in software maintenance?
7. How can GenAI be leveraged to automate bug triage?
8. How can GenAI be leveraged to automate clone detection?
4.5.3. State-of-the-art
The past year has witnessed significant transformations in software maintenance practice, largely catalyzed by the introduction of GitHub Copilot powered by OpenAI Codex. Leveraging LLMs can assist software maintainers in a wide range of activities, including code summarization, code translation, code refactoring, code repair, and more.
Code summarization is the task of writing natural language descriptions of source code. Taking into account that according to several studies [126, 125, 124], from 40% to 60% of the software maintenance effort is spent trying to understand the system, code summarization stands out as a pivotal technique for enhancing program comprehension and facilitating automatic documentation generation. It effectively addresses the frequent disconnect between the evolution of code and its accompanying documentation. Noever and Williams [127] demonstrated the value of AI-driven code assistants in simplifying the explanation or overall functionality of code that has shaped modern technology but lacked explanatory commentary. On a related note, Ahmed and Devanbu [128] investigated the effectiveness of few-shot training with ten samples for the code summarization task and found that the Codex model can significantly outperform fine-tuned models. Apart from writing new comments, automated code summarization could potentially help update misaligned and outdated comments, which are very common in SE projects[128].
Code translation involves the intricate process of converting code between different programming languages while preserving its functionality and logic. This task holds substantial practical value, especially in scenarios like migrating legacy code to modern technologies. For instance, billions of lines written in Cobol and other obsolete languages are still in active use, yet it is increasingly challenging to find and recruit COBOL programmers to maintain and update these systems. To bridge the gap between the available knowledge of individuals and the expertise needed to effectively address legacy problems, IBM recently introduced Watsonx Code Assistant for IBM Z mainframes. This tool helps enable faster translation of COBOL to Java and is powered by a code generating model called CodeNet, which can understand not only COBOL and Java but also approximately 115 different programming languages.
Code refactoring is the process of restructuring and improving the internal structure of existing source code without changing its external behavior. Madaan et al. [129] explored the application of LLMs in suggesting performance-enhancing code edits. They observed that both Codex and CodeGen can generate such edits, resulting in speedups of more than 2.5× for over 25% of the investigated programs in both C++ and Python. Notably, these improvements persisted even after compiling the C++ programs using the O3 optimization level. On a related note, Poldrack et al. showed that GPT-4 refactoring of existing code can significantly improve code quality according to complexity metrics [1].
Code repair refers to the identification and fixing of code errors that may cause program crashes, performance bottlenecks, or security vulnerabilities. Accelerating this process using LLMs is crucial, as developers invest a significant amount of engineering time and effort in identifying and resolving bugs that could otherwise be devoted to the creative process of software development. Automated program repair (APR) has been a topic of much interest for over a decade in the SE research community. Zhang et al. proposed a pre-trained model-based technique to automate the program repair [130]. Xia et al. [131] designed three different repair settings to evaluate the different ways in which state-of-the-art LLMs can be used to generate patches: 1) generate the entire patch function, 2) fill in a chunk of code given the prefix and suffix 3) output a single line fix. The findings suggest that directly applying state-of-the-art LLMs can substantially outperform all existing APR techniques. In contrast, Pearce et al. [132] examined zero-shot vulnerability repair using LLMs (including Codex) and found that off-the-shelf models struggle to generate plausible security fixes in real-world scenarios. In a different context, Asare et al. [133] discovered that Copilot has the potential to aid developers in identifying potential security vulnerabilities. However, it falls short when it comes to the task of actually fixing these vulnerabilities. Lastly, Mastropaolo et al. [96] fine-tuned the T5 model by reusing datasets used in four previous works that used deep learning techniques to (i) fix bugs, (ii) inject code mutants, (iii) generate assert statements, and (iv) generate code comments. They compared the performance of this model with the results reported in the four original papers proposing deep learningbased solutions for those four tasks. The findings suggest that the T5 model achieved performance improvements over the four baselines.
4.5.4. Challenges and Limitations
As detailed in the preceding subsections, GenAI models demonstrate proficiency in maintenance tasks that require an understanding of syntax, such as code summarization and code repair. However, they encounter challenges when it comes to grasping code semantics [122, 134]. Consequently, the performance of GenAI is still limited when it comes to several realistic scenarios [85].
Moreover, applying available GenAI tools to code translation tasks also faces challenges and limitations. Primarily, the amount of source code that LLMs can consider when generating a response is constrained by the size of the context window. To illustrate, ChatGPT Plus imposes a token limitation of 8,000 characters, equivalent to roughly 100 lines of code. Consequently, when dealing with extensive codebases, a straightforward approach of inputting the entire source code at once becomes unfeasible. For instance, in the case of GPT Migrate 11, code migration is a solvable problem if the entire codebase is small enough to fit in the context window. However, addressing larger codebases remains an unresolved issue. As this restriction on code length is inherent in the transformer architecture, overcoming this limitation would necessitate a significant breakthrough in the field. Besides, acquiring a large amount of high-quality source code and target code pairs is challenging, which may limit the model’s learning and generalization capabilities. Finally, as even minor translation errors can render the generated code non-functional, code correctness and precision are of paramount importance, posing challenges for LLMs.
4.5.5. Future Prospects
At the current stage, LLMs can serve as useful assistants to software maintainers, but they are very far from replacing completely humans [122]. Nonetheless, LLMs are continuously advancing, and they still hold significant untapped potential. One promising avenue is the concept of Collaborative LLMs [134]. This approach involves the integration of multiple LLMs or their combination with specialized ML models to minimize the necessity for human intervention. In this setup, multiple LLMs function as distinct ”experts”, each handling a specific subtask within a complex task [82]. By harnessing the collective strengths of diverse models, more precise and efficient outcomes can be achieved [134]. Furthermore, regarding the enhancement of correctness and performance in LLMs for vulnerability detection, future research should focus on combining LLMs with formal verification techniques, incorporating previously related edits, or implementing self-debugging algorithms [122].
4.6. GenAI in Software Processes and Tools
4.6.1. Historical Context.
Software processes are essential components of software development, helping developers create, maintain, and deploy software applications efficiently and effectively. Industry continues to look for novel ways of improving SE processes. So far, common software processes include Waterfall, Agile, Continuous Sofware Engineering and Lean Software Development [135, 136, 137]. The implementation of software processes often goes hand in hand with the adoption of various tools. For instance, Agile projects utilize Kanban-based management tools, and Continous Software Engineering with Continuous to automate the build, testing, and deployment of software, enabling rapid and reliable releases. As the latest movement, ML/AI for SE and specifically GenAI is receiving widespread interest in this regard. While early pioneers have been investigating and employing ML in SE even before the popularity of systems like ChatGPT, the integration of GenAI into SE practices has emerged as a critical industry priority. Although individual developers have started embracing these technologies for personal assistance[138], the endorsement and implementation of GenAI tools at the company level by management in many organizations are lagging.
4.6.2. Key RQs
In this regard, the main question is what to do with GenAI, and how to do so effectively while considering the current working processes, practices and environments. For example, a practitioner looking into Copilot could ask which tasks are the tool suited for and what are the good and best practices for utilizing them for said tasks. Given the versatility of GenAI, the potential applications of these tools in SE are still being explored. To this end, as GenAI tools are used to support and automate tasks by different personnel, the question of how they impact productivity becomes increasingly relevant from a business point of view. In the long run, the question of how these tools will transform SE processes and what types of new processes are born due to their use is important. We highlight specific RQs related to the SE process as below:
1. What strategies can be developed to enable GenAI models to support continuous integration and deployment (CI/CD) practices?
2. How can different GenAI tools be incorporated into software development environments?
3. To what degree do GenAI tools improve developer productivity?
4. How can GenAI be utilized to aid in the automation of code commit, pull, and push requests?
5. What approaches can be used to enhance the integration of GenAI into development environments, providing real-time intelligent assistance and feedback during code editing and development activities?
6. How can GenAI support the automation of build and deployment processes?
7. What is the impact of GenAI tools on developer productivity in various software development tasks and across different levels of developer seniority?
8. How can GenAI contribute to Citizen development?
9. How will GenAI tools transform fast-faced software development processes, i.e. Agile, Continuous Development and Lean Development?
4.6.3. State-of-the-art.
There currently exist a few studies focusing on GenAI and software processes. The tertiary study by Kotti et al. [18] provides an overview of AI use in SE overall, reconsidering deficient SE methods and processes. Weisz et al. [139] and Whites [46] explore the applications of GenAI in programming related tasks, while in another work, Whites and co-authors also discuss prompt patterns for SE-related prompts [73]. Ross et al. proposed a programmer assistant based on LLMs, and explored the utility of conversational interactions grounded in code [140]. The impacts of the utilization of GenAI tools have also been discussed, primarily from the point of view of productivity [100]. While some existing papers speculate on how SE might be transformed by (Gen)AI going forward, this remains on the level of speculation, although Bird et al. [102] provide some insights into how the use of GitHub Copilot changes the way software developers work.
Software processes are more often presented as a part of study contexts. Petrovic et al. presented a use case where ChatGPT can be used for runtime DevSecOps scenarios [141]. In a game development context, Lanzi et al. proposed a collaborative design framework that combines interactive evolution and large language models to simulate the typical human design process [142]. Ye et al. investigated the impact of ChatGPT on trust in a human-robot collaboration process [143].
4.6.4. Challenges and Limitations.
While many companies are interested in the potential prospect of automation and the resulting productivity and financial gains, many existing papers highlight the need for human oversight in utilizing GenAI in SE processes due to the potential errors GenAI tools make (e.g., programming [144]). In this regard, Moradi et al. [78] argue that tools such as GitHub Copilot can be assets for senior developers as supporting tools but may prove challenging to more novice developers who may struggle to evaluate the correctness of the code produced by the AI. Becoming overconfident in GenAI tools may result in a lack of criticism towards the code produced [79]. Overall, good practices in utilizing GenAI in the SE process are still missing, and only a number of early studies have begun to inspect the practical applications of GenAI in the SE process. Though the promise of code generation with GenAI is now largely acknowledged and, to a large extent, demonstrated in practice as far as market viability is concerned by the explosive growth of the GitHub Copilot service, the utilization of GenAI for other SE processes is far less explored, and even the impact of GenAI on code generation remains poorly understood (e.g., productivity in different contexts).
4.6.5. Future Prospects.
GenAI tools, alongside AI in general, have the potential to transform SE processes as we know them today. It is argued that, in the near future, the work of developers will shift from writing code to reviewing code written by AI assistants [102]. Carleton et al. [9] argue that the key is ”shifting the attention of humans to the conceptual tasks that computers are not good at (such as deciding what we want to use an aircraft for) and eliminating human error from tasks where computers can help (such as understanding the interactions among the aircraft’s many systems)”. Such larger, fundamental shifts in organizing SE processes are arguably at the center of the future prospects for the SE process research area. For example, while the changing role of developers is acknowledged, with AI tools making it possible for developers to automate menial tasks in order to focus on tasks that require more expertise, what exactly these tasks might be in the future remains an open question.
4.7. GenAI in Engineering Management
4.7.1. Historical Context
- Engineering management is the SE branch that deals with managing principles and practices concerning the engineering field. The critical aspects of this field include project management [145], human resources [146], team, leadership [147], technical expertise, budgeting, resource allocation, risk management [148], communication, quality assurance, continuous improvement, ethics, and professionalism [149]. A project undertaken under engineering management ensures that it is completed successfully, on time, within budget, and with high-quality standards [150]. Crucial is to manage the project under several laid out regulations [149]. Tambe et al., in Human resource management and AI, identified four types of challenges. First, complex phenomena surround the human resource. Second, the chain that bounds the small data sets, i.e., the people working in an organization, is minor in comparison to the purchases made by the customer. Third, ethical obligations are involved with legal constraints. Fourth, the response or behaviors of employees towards the management [146]. Wang et al. proposed a systematic roadmap to navigate the next step of AI in product life cycle management. The study further mentions the advantages and challenges of applying AI in product cycle management. [151].
4.7.2. Key RQs
- We consider the following RQs that present some open challenges in managing software development projects:
1. What are the implications for team sizes and dynamics of the use of GenAI in software development?
2. Can a trained AI tool speed up the enrolment process of a new employee?
3. To what extent should experience developers be retrained to adapt to GenAI use in their work?
4. How can organizations foster a culture that promotes the symbiotic collaboration between software developers and GenAI systems, creating an environment that encourages trust, learning, and innovation?
5. What could be an efficient human-ai collaboration workflow?
6. Do different SE roles feel a stigma about using AI assistants to help them with their jobs?
7. What is the economic impact of incorporating GenAI in software development processes, considering factors such as cost savings, productivity gains, and overall return on investment?
4.7.3. State-of-the-art
For project management in general, Holzmann et al. conducted a Delphi study on 52 project managers to portray the future AI applications in project management [152]. The author presented the list of most and least important project management areas where GenAI can be adopted. Prifti et al. identified the pain points or problems in project management. Then, the paper proposes how AI can play a role and help optimize weak points. AI’s assistance helps project managers become more productive and skilled in organizations [153].
In software project management, AI-based approaches can be useful for various project estimation and allocation tasks. Dam et al. explored the effort estimation problems in an Agile context [154]. Elmousalami analyzed and compared the 20 AI techniques for a project cost prediction [155]. Fu et al. proposed a GPT-based Agile Story Point Estimation approach, highlighting a practical need for explanation-based estimation models [156]. Alhamed evaluated the Random Forest and BERT model in software ask effort estimation. [157]. The authors suggested that BERT shows marginally improved performance than other approaches.
To contribute to the discussion about GenAI in an industrial context, Chu explored the impact of ChatGPT on organizational performance (productivity), reporting various use contexts but no notable productivity increases [158], although without a specific focus on SE-related work. Ebert & Louridas [159] reported industrial, empirical results from a case study, discussing the overall promise of GenAI for software practitioners and the current state of the field, and highlighting potential application contexts in SE (media content creation and improvement, generative design, code generation, test case generation from requirements, re-establishing traceability, explaining code, refactoring of legacy code, software maintenance with augmented guidance, and improving existing code, among others).
![Table 3: A list of relevant and important PM tasks can be supported by AI tools [152]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-4qe3rxg.jpeg)
4.7.4. Challenges and Limitations
In this SE area, the lack of industrial studies, and especially the lack of studies with an organizational focus, presents as one of the notable gaps. Pan et al. presented a critical review of AI-generated future trends in construction engineering and management. The study outlines six crucial concerns regarding AI in construction engineering, which are (1) knowledge representation (2), information fusion, (3) computer vision, (4) natural language processing, (5) process mining, and (6) intelligence optimization [160]. Another study described the future challenges of adopting AI in the construction industry [161], presenting several challenges. They are the cultural issues and explainable AI, the security concerns, the talent shortage of AI engineers, the high cost in the construction industry, ethics, governance, and finally, the computing power and internet connectivity that lead to construction activities. There are several challenges concerning software project management, too, such as needing more understanding concerning the software development team and awareness of the project. The project context could be complex, with limited knowledge available that might create developers in the group with biased decisions. In other words, biased data created could lead to subjective decisions that result in less effective software projects [162].
4.7.5. Future Prospects
AI is regarded as an originator, coordinator, and promoter of innovation management. At the company level, AI applications can be used for opportunities like searching for information, generating ideas, and value creation. In terms of organization design, AI could be beneficial in looking into the structure of the firm, customer engagement, and human decision-making processes. AI can be useful for generating information to data access that could help at the startup and SME levels [163]. In software project management, AI can be very handful in assisting the organization of resources and allotting, managing the risks involved in the projects, automation of the task allocation, estimating the cost of the project and its related requirements and planning the agile sprints [154]. Monitoring the performance, capturing the problems inside the project, providing support suggestions, and documenting the project could make some prospects replaceable by AI [164].
4.8. GenAI in Professional Competencies
4.8.1. Historical context.
There are skill shortages and talent gaps [165, 166, 167] in the software industry: this situation has been going on for a while and companies struggle to find qualified employees [168, 169]. On top of that, there is a gender gap in technology-related study fields [168, 170] and a soft skills gap [171, 165] that make it even harder to find professionals and have balanced teams able to detect and correct unfair biases, e.g., caused by the selection of data sources [172]. The question then is how to offload repetitive tasks from existing developers by smoothly integrating GenAI into their workspace. On the one hand, as happened with previous technologies empowering developers, integrating GenAI into the workspace and ensuring that developers smoothly work alongside GenAI tools will probably require training [167]. However, as seen in previous research, some users might already have an intuition on how to work with them, maybe depending on their seniority level or background [166, 167]. On the other hand, GenAI could also be part of the training of software developers of the future, partially addressing the aforementioned skill shortages, as discussed in Section 4.9.
4.8.2. Key RQs.
Not only academic research teams are studying how to effectively integrate GenAI within Agile teams to increase their productivity, also companies are actively exploring how these technologies will affect the work dynamics of their employees and, more specifically, of developers. Future research should explore the integration of GenAI tools in professional practices, covering productivity impacts, necessary skills and training, addressing skill shortages, GenAI as an advisor, and perceptions of integration strategies in Agile software development. These high-level concerns are addressed by the five suggested RQs listed below:
1. How can GenAI address the skill shortages and talent gaps in the software industry, and how would different strategies affect the desired profile for future software developers?
2. How would various strategies for GenAI integration within Agile software development, such as in up-skilling and re-skilling professionals, offloading repetitive tasks, or human resource management, be perceived?
3. What is the impact of GenAI tools on productivity across various software development tasks, with respect to developer seniority and at the organizational level at which the GenAI interventions take place (i.e., team or team member)?
4. How can GenAI be effectively used as an advisor to enhance the productivity and skills of software professionals, and what are the key challenges and opportunities in designing training programs for this?
5. What skills and training are necessary for software engineers to generate quality outputs using GenAI and effectively work alongside GenAI systems? Does the level of SE training correlate with these goals?
These RQs reflect the main lines of research from industry and academia in understanding how GenAI tools could mitigate the current issue of finding software professionals and either offload or up-skill existing developers to strengthen their teams.
4.8.3. State-of-the-art
As previously stated, both academic and industrial researchers are actively exploring how GenAI technologies will affect the work processes and dynamics. An increasingly adopted tool for such explorations is GitHub Copilot [77]. Copilot generates pieces of code given prompts in the form of comments or function signatures thanks to its training with open-source projects hosted by the GitHub platform. Other platforms include local versions of GPT-models [173] or BARD [174], both based in LLMs. For these tools, however, it is unclear whether their usage violates the licenses and internal best security practices. As a result, informed human oversight will still be needed to ensure the trustworthiness of the generations [175].
4.8.4. Challenges and limitations.
Software development companies are often cautious about granting external access to their systems due to strict policies safeguarding proprietary information and sensitive data. Convincing companies to participate in research on GenAI interactions can be challenging, even though demonstrating the mutual benefits of testing the integration of GenAI tools in their unique working environment can increase their willingness to collaborate. As in any other research endeavour involving human participants, obtaining informed consent and maintaining confidentiality and anonymity are crucial. However, in this case, research results may offer insights into the different productivity or work dynamics of teams and team members. Therefore, researchers must ensure that their findings are put into context and that the validity of their conclusions is clearly stated. This precautionary approach is essential to prevent companies from making drastic decisions based on potential misinterpretations of the research results.
4.8.5. Future prospects.
In conclusion, addressing these RQs and carefully applying the results to various work environments and domains can serve as a valuable guide for the sensible integration of GenAI tools within Agile software development. This integration should consider the progressive adaptation of work dynamics and their adoption by the different stakeholders. The answers to these questions will, on the one hand, prepare companies and industrial players for the new technological setup where software developers can be offloaded of repetitive tasks. On the other hand, this knowledge will play a crucial role in shaping the integration of GenAI into educational and re-skilling activities for future software developers, as discussed in Section 4.9, indirectly contributing to mitigate the present talent gap [165, 167].
4.9. GenAI in Software Engineering Education
4.9.1. Historical Context.
The development of engineering education has been inextricably linked to the technological development of the era. Technological adoption for better education is always an important topic in higher education. SE research has extensively looked at the use of chatbots to support students outside the classroom. These chatbots can provide automated assistance to students, helping them with coding and problem-solving tasks [7], providing explanations and examples, as well as helping students identify errors in their solutions [176, 177, 178, 179, 180].
Another popular SE education paradigm is an automated assessment of exercises. Automated assessment techniques can help provide students with immediate feedback on their work, allowing them to quickly identify and correct errors [181]. This approach can also facilitate self-assessment and selfexamination among students, enabling them to explore various solutions and identify areas where they require further improvement [182]. Another active research area that is gaining attention is how learning can be individualized. Current AI approaches focus on finding questions of similar difficulty to a given question [183].
4.9.2. Key RQs
GenAI has the potential to revolutionize the existing education landscape by advancing the three above trends. For future research actions, there are several interesting themes that can be framed as RQs, as listed below:
1. How can GenAI be effectively integrated into SE education curricula to enhance student learning outcomes and develop future-ready skills?
2. In a classroom environment with a “virtual” assistant with the capacity of i.e. ChatGPT, how can it be set up to effectively achieve the learning objectives?
3. How can GenAI be used to personalize and adapt SE education to cater to diverse student needs, learning styles, and skill levels?
4. How does the integration of GenAI in SE education foster critical thinking, problem-solving skills, and computational creativity among students?
5. What assessment methods and tools can be developed to evaluate students’ understanding, competency, and proficiency in GenAI concepts and applications?
6. What are the long-term impacts of including GenAI in SE education, such as its influence on students’ career paths, job prospects, and contributions to the technology industry?
7. In what activities the use of AI can harm the learning outcome that the participants have?
8. What are the ethical considerations and implications of teaching GenAI in SE education, and how can educators promote responsible AI usage and ethical decision-making among students?
9. What are the challenges and opportunities in training IT educators to effectively incorporate GenAI concepts and tools into their teaching practices?
4.9.3. State-of-the-art
We found a large number of studies discussing the potential of GenAI in education in general and in SE education, in particular, [184, 185, 186, 187, 188, 189]. Bull et al. interviewed industry professionals to understand current practices, implying a visionary future of software development education [185]. Jalil et al. explored opportunities for (and issues with) ChatGPT in
software testing education [188].
There also emerges empirical evaluation of GenAI in different teaching and learning activities. Savelka et al. analyzed the effectiveness of three models in answering multiple-choice questions from introductory and intermediate programming courses at the post-secondary level [190]. A large number of existing papers discuss the potential challenges GenAI presents for educators and institutions, which is also a recurring topic in these SE papers. However, these papers also discuss the potential benefits of GenAI for SE education. Yilmaz et al. conducted experiments with their students and found that ChatGPT could enhance student programming self-efficacy and motivation, however, it is important to provide students with prompt writing skills [191]. Philbin explored the implications of GenAI tools for computing education, with a particular emphasis on novice text-based programmers and their ability to learn conceptual knowledge in computer science. The author presented many positive angles on GenAI adoption and suggested the integration of basic AI literacy in curriculum content to better prepare young people for work [192]
4.9.4. Challenges and Limitations
While GenAI tools like ChatGPT offer a revolutionary approach to facilitating SE education, they are not without limitations. A recent paper presented the perceived weaknesses of ChatGPT in nine SE courses. The authors presented the weaknesses in three categories: theory courses, programming courses, and project-based courses.
In a theory course, a common challenge of ChatGPT is that its responses are limited to the information provided in the question. This means that if a question is poorly formulated or lacks relevant details, the response from ChatGPT may not be satisfactory. To use ChatGPT effectively, students need to be prepared with critical and innovative thinking, which does not yet exist in any college’s curriculums. The problem of the non-deterministic nature of AI is particularly significant in an educational context, as different answers can be generated for the same question, which could lead to confusion for students. Besides, ChatGPT has limited domain knowledge, so questions that require a lot of context or background information may not receive meaningful answers without sufficient input from the user.
Regarding programming courses, while GenAI tools can provide information and guidance on programming concepts, students cannot develop their practical skills solely by using ChatGPT. This applies to complex programming concepts, intricated problems, especially those related to integrating libraries or, specific system configurations, or large software systems. AI tools sometimes offer deprecated solutions or code snippets, meaning they are outdated or no longer recommended for use. Using deprecated solutions can lead to inefficiencies or conflicts in modern coding environments. Moreover, with lectures with a lot of visual representations, ChatGPT relies on natural language processing and may struggle to interpret visual information. For example, in a lecture about 3D modeling, ChatGPT may not be able to explain a particular aspect of the modeling process that is best understood through visual demonstration. While ChatGPT can provide information on general programming concepts, it may not be able to provide insight into specific practices used in a particular industry. For example, a student studying game development may need to learn about specific optimization techniques used in the gaming industry, which ChatGPT may not be familiar with. Furthermore, as technology and programming languages evolve rapidly, AI’s knowledge might lag behind the most recent advancements or best practices. Some students pointed out that e.g. ChatGPT lacked information about the latest developments, affecting its ability to provide the best or most relevant answers. Furthermore, AI models don’t possess an inherent understanding of context. There were situations where the tool couldn’t recognize missing methods in a Repository class or provide solutions based on a broader project context, which a human tutor might be able to grasp.
Regarding project-based learning, where project contexts can change frequently, it is necessary to update the context information for the tool to catch up with project progress. For example, if a project in a software engineering class changes its requirements, students may need to make changes to their code. ChatGPT may not be able to keep up with these changes and may not be able to provide relevant advice to students. This is also because realworld settings can not be fully described as input for the tool. ChatGPT is based on pre-existing data and may not be able to provide practical advice for unique situations that occur in real-world settings.
4.9.5. Future Prospects
In conclusion, GenAI tools, like ChatGPT, have shown significant promise in SE education. In the future, We foresee a comprehensive integration of GenAI tools at different levels for both educators and learners. Future research will address today’s gap to visualize this scenario:
• The integration of GenAI into SE teaching content and approaches. There is a pressing need for educational institutions to adapt their curriculum and teaching methodologies to incorporate GenAI concepts, tools, and practices. Concerning curriculum development, it becomes essential to determine which GenAI-related knowledge, such as prompt engineering, AIOps, and AI-human interaction, should be integrated into existing lectures on core SE topics like requirements engineering, software design, software testing, and quality assurance. On the teaching approach, how should such integration be done? GenAI tools like CoPilot, and ChatGPT also present a great potential to assist both educators and learners. There is a need to develop methodologies that help educators and AI developers work collaboratively to ensure that AI recommendations and adaptations align with established learning outcomes and instructional strategies. Besides, while AI can leverage large volumes of data to personalize learning experiences, there is a lack of standardized methodologies for collecting, processing and utilizing educational data ethically and effectively.
• A new assessment approach for student-GenAI collaboration A significant knowledge gap exists concerning the development and implementation of a novel assessment approach tailored to evaluate the efficacy and outcomes of student-GenAI collaboration in educational settings. We can not assess the student project delivery without considering the level of CoPilot involved in their project. Research is needed to create fair and reliable assessment techniques that differentiate between student-generated and AI-generated work. Project requirements and learning objectives might need to be updated as well to ensure that evaluations accurately reflect students’ abilities and knowledge
• An evaluation of the impact of AI-enabled curriculum and teaching approaches on learning outcome and student engagement It is necessary to delve into empirical studies to measure and evaluate the impact of GenAI-related content and teaching approaches on student learning outcomes and engagement. Research in this area can involve conducting controlled experiments and collecting data to quantify the effectiveness of AI-assisted approaches compared to traditional methods. Assessment needs an ethical guideline focusing on how GenAI is used in SE courses.
4.10. GenAI in Macro aspects
4.10.1. Historical context
The use of GenAI for SE brings implications and opportunities to other spheres beyond the technical aspects, such as market, business, organizations and society. This phenomenon can be observed with other technologies. For example, the advent of cloud computing, in which computing resources are hired on demand without the need for large upfront investments in infrastructure, allowed the cheap experimentation of new digital products [193], paving the way for methodologies for the development of startups focused on quick feedback from customers, such as Customer Development [194] and Lean Startup [195]. A more recent example is the emergence of more powerful AI algorithms and their reliance on data, leading to a growing research interest in the ethical aspects of this use [196], i.e., AI ethics.
4.10.2. Key RQs
We present the key RQs identified regarding macro aspects as listed below:
1. How can GenAI be employed to support novel and innovative softwareintensive business models?
2. How can the adoption of GenAI in software development affect the competitiveness and market positioning of software-intensive companies, and what strategies can be employed to leverage AI for business growth?
3. What are the potential barriers and challenges to the adoption of GenAI in software-intensive businesses?
4. How does the integration of GenAI in software-intensive businesses affect software licensing models, and intellectual property rights?
5. How can software businesses effectively navigate the ethical considerations and societal impacts of using GenAI?
6. How does the adoption of GenAI impact the sustainability of software businesses?
The first aspect included in this section regards the business of software. Any new technology brings several economic opportunities usually exploited by new companies. The application of GenAI to software development could bring several innovation opportunities for the players involved. A better understanding of this process, including a clear view of its associated challenges, would help software startups and established companies create and capture value for their customers by developing novel or adapting existing business models effectively. Still, regarding economic aspects, it remains unclear how the fact of AI creating intellectual property (IP) could change the management of this IP, including protection, use, and monetization. The second aspect regards the implications of the use of GenAI in software development to the environment and society. For example, GenAI adoption might reduce the need for human software developers, leading to a large contingent of job losses and the consequent need for retraining these people. Another issue might be the environmental impact of GenAI given, for example, the amount of resources needed to train the models.
4.10.3. State-of-the-art
Moradini conducted a narrative review to analyze research and practice on the impact of AI on human skills in organizations [197]. The authors suggested the identification of needed skills for the adoption of AI and provided training and development opportunities to ensure their workers are prepared for the changing labor market. Kanbach et al. [198] performed a business model innovation (BMI) analysis on the implication of GenAI for businesses. The authors identified some propositions based on the impact on innovation activities, work environment, and information infrastructure. In particular, they discussed the SE context identifying possibilities for value creation innovation, e.g., automatic code generation, new proposition innovations, e.g., AI-powered software development platforms, and value capture innovations, such as improving operational efficiency by, for example, task automatization. On the other hand, there have been some calls for action regarding the regulation of GenAI, for example, in the healthcare sector [199].
4.10.4. Challenges and Limitations
As essentially interdisciplinary aspects, the research on these topics will have to converge to other fields, such as economics, psychology, philosophy, sociology, and anthropology. For example, concerns regarding intellectual property involve not only economic but also more fundamental aspects, such as what a person is, that are the study field of philosophers. These aspects are also associated with national and supranational politics and economics. Different countries might decide to create specific legislation or public policies depending on their political and economic tradition.
4.10.5. Future Prospects
GenAI is an emerging technology that will develop even further in the following years. As it becomes increasingly capable of performing SE-related tasks, its implications on the macro aspects discussed above will grow. GenAI will be increasingly employed as part of software intensive business models or even to suggest modifications to these business models. This process will represent a challenge for consolidated companies but also an opportunity for new incumbents. Current market leaders will need novel strategies to cope with these challenges and innovate, and novel software-intensive business models will emerge. In the following decades, we will probably see the downfall of current juggernauts and the emergence of new ones. Not only companies but also individuals will be affected, increasingly being replaced by AI. In this regard, we will probably watch a change in labour force, including professions related to software development, towards new careers, many of these initiated by GenAI, in a similar movement that developed countries experienced after the deindustrialization and the transfer of labour force to the services segment. Finally, we will probably see in the following years the emergence of new legislation regulating the use of GenAI and the products created by it. This phenomenon could lead to tensions among different actors in society, such as the strike of writers in Hollywood that paralyzed the production of several movies and TV series, motivated, among other things, the use of GenAI for script generation. Similarly, it could lead to international tensions regarding different legislation in different countries or regions or the influence of one country that detains the technology over others consuming it.
4.11. Fundamental concerns of GenAI
GenAI models, particularly those based on deep learning architectures such as the GPT series, have shown remarkable capabilities in various SE tasks ranging from code generation to bug detection. However, their application in SE also brings a set of fundamental concerns. We summarized the concerns in the following RQs and elaborated on them further in this section:
1. How all previous RQs can be addressed in an industry-level evaluation?
2. How reliability and correctness of GenAI can be ensured for professional uses?
3. How can GenAI output be explained and systematically integrated into current decision-making mechanisms?
4. How sustainability concerns can be addressed for the application of GenAI?
Industry-level evaluation of GenAI. LLMs are seldom effective when used in a small task but can be highly effective as part of an overall software engineering process. The industry-level evaluation of GenAI technologies would be the next step to bridge the gap between small-sized empirical studies and real-world applications, ensuring that the promises made in research labs align with practical industry needs and challenges. Industry evaluations might reveal the tangible impacts, such as feasibility, usability, scalability, and cost-value tradeoff of adopting GenAI. Scalability is a critical factor for industry evaluation. Can the AI system perform well at scale, handling large volumes of data and complex tasks? Usability, user satisfaction, and user engagement are key aspects of evaluation. Moreover, research is desirable for understanding workflows, processes, and coordination paradigms so that GenAI can safely, efficiently and effectively reside. Moreover, in applications where AI interacts with users, the user experience is vital.
Reliability and correctness concern The reliability and correctness of the generated code are pivotal. Unlike creative content generation, where occasional mistakes might be acceptable, in SE, even minor errors can have catastrophic consequences [200]. However, there are challenges when rolling out improvements: improving a model’s performance on certain tasks can unexpectedly affect its behavior in other tasks (e.g., fine-tuning additional data might enhance performance in one area but degrade it in another). The problem of hallucination has already been widely studied [8, 201, 202, 203, 204]. It will continue to be a topic of great interest, both within the software engineering community and in the wider computer science community. Moreover, the performance and behavior of both GPT-3.5 and GPT-4 vary greatly over time [205]. For instance, GPT-4’s March 2023 version had a better performance at identifying prime numbers compared to its June 2023 version, a relatively short period. This emphasizes the importance of continuous evaluation, especially given the lack of transparency regarding how models like ChatGPT are updated.
Data availability AI model relies heavily on a large amount of data for training and fine-tuning, posing challenges for private companies to adapt existing AI models to their work. The quality, diversity, and quantity of data directly affect the performance and generalizability of the models. Domainspecific data required for fine-tuning can be a bottleneck. Moreover, privacy and security are major concerns for companies and organizations adopting GenAI. Company data might be confidential, sensitive and personal. Concerning the adoption of GenAI in private companies can include concerns about data breaches, unauthorized access to confidential data, and the use of data without permission [206, 207, 203]. Regular audits of the data privacy and security measures will need to be in place to identify and address any potential vulnerabilities or areas for improvement.
Explainability concern. The “black-box” nature of these models poses interpretability challenges, making it difficult to reason about their decisionmaking process or to debug when things go awry [208, 209]. Transparency in decision-making is crucial in SE, where understanding the rationale behind every line of code is often necessary. Other ethical concerns also arise when discussing integrating GenAI tools in real-world environments. For instance, the dependence on training data means that these models can inadvertently introduce or perpetuate biases in the datasets they are trained on, leading to unfair or discriminatory software applications [172]. These biases can be perpetuated if appropriate human oversight mechanisms, which require transparency, are not set in place. For instance, mechanisms to avoid automation bias are largely needed, especially for LLMs that usually make confident statements about their decisions. This could lead, in the future, as stated by the participants in the survey conducted by Cabrero-Daniel et al., to a potential loss of human expertise as tasks become automated and GenAI tools become common-use [210], leading to a diminished ability to address or understand complex software challenges in the future manually.
Sustainability concerns. As a general concern in sustainable software engineering [211, 212, 213], the appearance of lots of LLMs daily raise a concern about their environmental impact, i.e. energy consumption [214, 215, 216]. Chiet et al. showed that ChatGPT-like services, inference dominates emissions, in one year producing 25 times the CO2 emissions of training GPT3 [215]. LLM capabilities have been associated with their size [217], resulting in the rapid growth of model size [218]. While it has been suggested that the model performance depends not only on model size but also on the volume of training data [74], the question of a triple-bottom-line model size that at the same time achieves performance, environmental and organizational objectives, remains unclear.