Microservices architectures have become increasingly popular due to their multitude of benefits, such as modularity, scalability, fault isolation, and the ability to deploy services independently. However, this architectural style isn't without its challenges. One of the most crucial concerns is maintaining backward and forward compatibility when evolving services.
In a microservices ecosystem, services often need to interact with different versions of other services. As your application grows and evolves, maintaining compatibility across different versions can become a complex issue. In this article, we'll explore strategies and best practices for ensuring both backward and forward compatibility, allowing for seamless interaction and smooth, downtime-free deployments.
Understanding Backward and Forward Compatibility
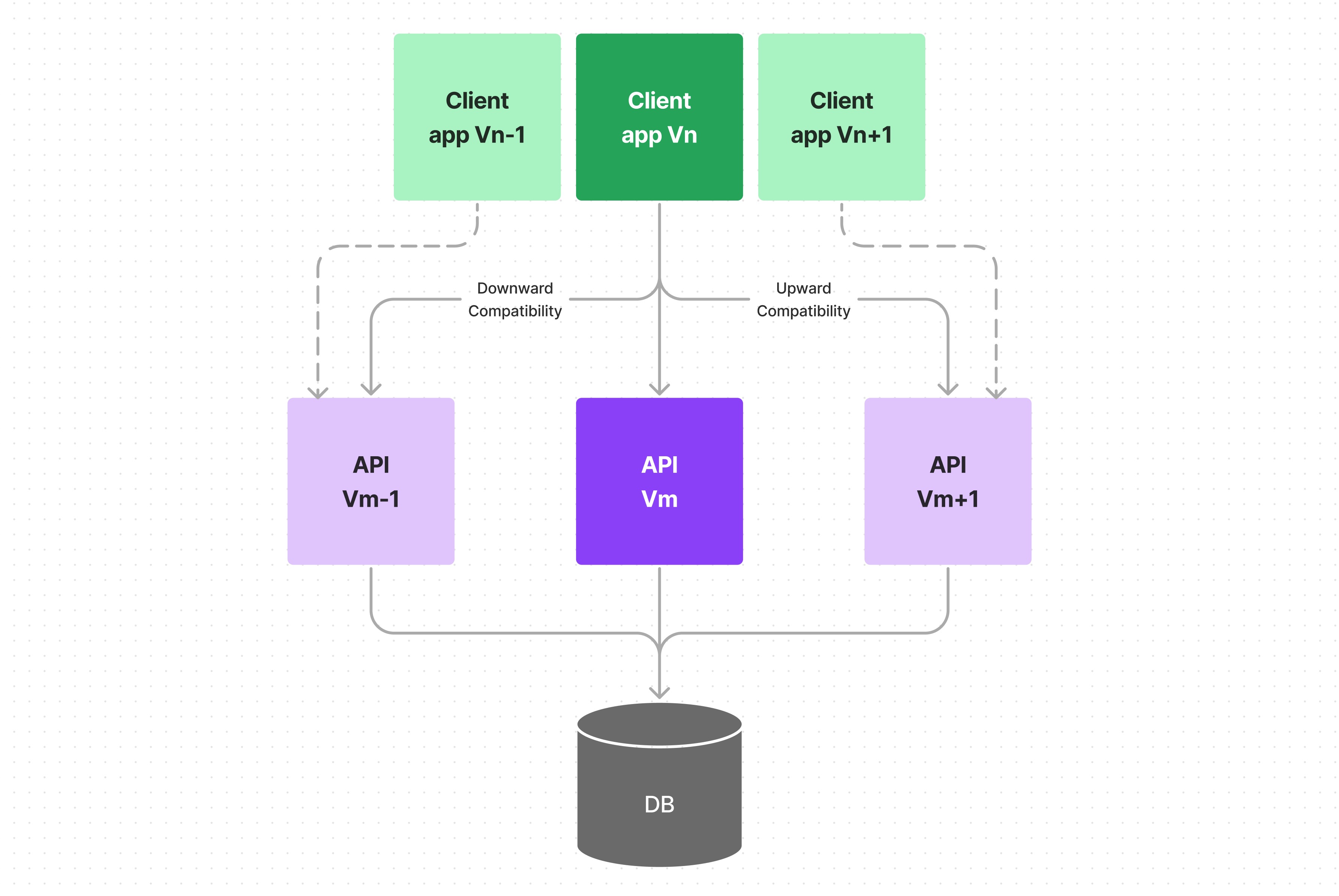
Backward compatibility ensures that newer service versions can still communicate with older versions. It is a design that is compatible with previous versions of itself. In a backward-compatible system, clients built to work with the older version will still function correctly when interacting with the newer version.
Forward compatibility, on the other hand, implies that a system can handle input intended for a future version of itself. It means an older service can still interact effectively with a newer one.
Maintaining these compatibilities is critical in a microservices environment. Different teams working at different speeds may deploy their services independently, leading to a mix of service versions active at any given time.
Examples
Many widely adopted technologies have been designed with a high emphasis on backward compatibility or forward compatibility. Here are a few examples:
-
HTML: HTML is a prime example of a technology that prioritizes backward compatibility. New versions of HTML, like HTML5, introduced new tags and features that do not break older browsers. Browsers that do not understand a certain HTML tag simply ignore it and move on to the next tag, ensuring that the webpage is still rendered.
-
SQL: SQL, the language for communicating with databases, has remained largely backward compatible over its many versions. This means you can run a SQL query written 30 years ago, and it should still work on modern SQL databases. However, each database management system (DBMS) may have its specific SQL dialect with additional features.
-
JavaScript/ECMAScript: The ECMAScript specification, which JavaScript implements, has seen many updates over the years, adding features like arrow functions, promises, async/await, and more. These changes are designed to be backward compatible to not break the web. Old JavaScript code can run in modern browsers, and new features are often ignored or treated as regular objects in older browsers that don't support them.
-
Docker: Docker, the popular containerization platform, ensures backward compatibility with its Docker Compose tool. New versions of Docker Compose are compatible with previous versions of the Docker Compose file format, allowing older files to work without changes.
-
RESTful APIs: RESTful APIs, if designed according to best practices, often emphasize backward compatibility. Changes and enhancements to the API are made in such a way that older clients can still function correctly.
Forward compatibility is more challenging to achieve due to the inherent unknowns about future versions. However, formats like XML and JSON are inherently forward-compatible to an extent. You can add new fields to an XML or JSON message, and as long as applications that read the message ignore unrecognized fields, they can handle the new version of the message gracefully.
In the world of hardware, USB is another example. For instance, USB 3.0 ports were designed to accept USB 2.0 devices, and USB 2.0 ports can connect to USB 3.0 devices, although they'll operate at the 2.0 speed.
Microservices and Compatibility Challenges
Microservices communicate with each other through well-defined APIs, store data in various databases, and may interact asynchronously via events. Maintaining compatibility across these interfaces and formats can be challenging, especially considering the pace at which these services can evolve in an agile development environment.
Compatibility needs to be considered for each aspect of a service: its public API, its database schema, and the format of the events it produces or consumes. Changes to any of these can potentially break compatibility, impacting other services and the overall health of the application.
Strategies for Achieving Compatibility
API Versioning
API versioning is a strategy employed to maintain compatibility when changes are made to a service's API. Changes to APIs can come in various forms, including adding new endpoints, modifying existing ones, or deleting deprecated ones. Not every change is backward-compatible, so maintaining different API versions helps manage these changes without disrupting service interaction.
There are different ways to version APIs, such as using the URL (path or parameter), headers, or the content itself. Regardless of the method you choose, the goal is to have multiple versions of your APIs active at the same time. Older services can continue using the older API versions, while newer services use the updated versions.
app.get('/v1/users', (req: Request, res: Response) => {
res.json({
message: "Welcome to version 1 of the users API!",
users: [{ id: 1, name: 'John Doe' }]
});
});
app.get('/v2/users', (req: Request, res: Response) => {
res.json({
message: "Welcome to version 2 of the users API!",
users: [{ id: 1, name: 'John Doe', email: 'john.doe@example.com' }]
});
});
In this example, we have two versions of the "users" endpoint. The first version (/v1/users) returns a list of users with their id and name. Later, we decided to include the users' emails in the response, so we created a new version (/v2/users).
Clients that were built to work with version 1 of the API can continue to interact with /v1/users, while new clients can take advantage of the additional data provided by version 2 by interacting with /v2/users.
This way, we're able to evolve our API without breaking existing clients. That's the essence of backward compatibility and the goal of API versioning.
Database Evolution
Just as your APIs evolve, so will your database schemas. However, direct changes to schemas can disrupt your service operations. One approach to evolve your database schema while maintaining compatibility is the expand/contract pattern.
In the expand phase, you make backward-compatible changes. For example, you might add a new column to a table, but your existing service code does not yet use this column. After testing and ensuring everything works as expected, you then update your services to start using the new column, marking the end of the expand phase.
In the contract phase, you remove deprecated database schema elements that your services no longer use. Again, this is done in a backward-compatible manner, ensuring no disruption to the service operations.
For example, consider an application that has a users table with the following fields:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL
);
Suppose that your application needs to start tracking the date each user account was created. You could add a created_at field to the users table using an ALTER TABLE statement:
ALTER TABLE users
ADD COLUMN created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP;
By using a default value of CURRENT_TIMESTAMP, existing rows in the table will have the created_at field set to the time the ALTER TABLE statement was run. This allows you to maintain backward compatibility with existing data while evolving your database schema to support new features.
However, directly applying changes to your production database is risky. A safer approach is to use a database migration tool to manage your database schema changes. This allows you to version your database schema, roll changes back if something goes wrong, and apply changes in a controlled manner.
Below is an example of how you might write this migration using a tool like Knex.js, which is a SQL query builder that supports schema migrations:
import * as Knex from 'knex';
exports.up = function(knex: Knex): Promise<void> {
return knex.schema.table('users', table => {
table.timestamp('created_at').defaultTo(knex.fn.now());
});
};
exports.down = function(knex: Knex): Promise<void> {
return knex.schema.table('users', table => {
table.dropColumn('created_at');
});
};
The up function adds the created_at field to the users table, while the down function removes it. This allows you to roll the migration back if necessary.
Message Formats in Event-Driven Systems
In an event-driven architecture, services communicate asynchronously via events. Just as with APIs and database schemas, the format of these events needs to evolve while maintaining compatibility.
One approach is to version your events and include the version number in the event's metadata. When a service receives an event, it checks the version number and handles the event accordingly. This method requires your services to be capable of handling multiple versions of events, similar to how they would handle multiple versions of APIs.
Let’s consider following example with a hypothetical messaging library. We will show a basic event payload structure and how it can evolve over time without breaking existing consumers.
Let's start with a simple UserCreated event:
interface UserCreatedV1 {
type: 'UserCreatedV1';
payload: {
id: string;
name: string;
email: string;
};
}
The UserCreatedV1 event contains the basic information about the user. Let's say we now want to include the createdAt field in the event payload. Here's how we could do this in a backward-compatible way:
interface UserCreatedV2 {
type: 'UserCreatedV2';
payload: {
id: string;
name: string;
email: string;
createdAt: string; // New field
};
}
By creating a new version of the event, UserCreatedV2, we're able to add new data without affecting consumers that are only expecting UserCreatedV1 events.
Now, let's consider how we could handle these events in our consumers:
function handleEvent(event: UserCreatedV1 | UserCreatedV2) {
switch (event.type) {
case 'UserCreatedV1':
handleUserCreatedV1(event.payload);
break;
case 'UserCreatedV2':
handleUserCreatedV2(event.payload);
break;
}
}
function handleUserCreatedV1(payload: UserCreatedV1['payload']) {
// Handle version 1 of the event
}
function handleUserCreatedV2(payload: UserCreatedV2['payload']) {
// Handle version 2 of the event
}
Consumers that know how to handle UserCreatedV2 events can take advantage of the additional createdAt field, while consumers that only know how to handle UserCreatedV1 events can continue to function as before.
Best Practices and Techniques
Contract Testing
As your system grows and evolves, keeping track of the interactions between all your services can become quite complex. Contract testing is a method that can help manage this complexity. In contract testing, you define a contract that specifies how your service's API should behave, and then test that your service adheres to this contract.
The contract can define things like the endpoints your service exposes, the input they accept, and the output they produce. By regularly running these tests, you can ensure that your service's API continues to behave as expected, even as you make changes to your service.
Example of a contract test with the Pact framework
describe('User API', () => {
beforeAll(() => provider.setup());
afterAll(() => provider.finalize());
describe('get /users/:id', () => {
beforeAll(() => {
return provider.addInteraction({
state: 'a user exists',
uponReceiving: 'a request for a user',
withRequest: {
method: 'GET',
path: '/users/1',
},
willRespondWith: {
status: 200,
body: {
id: 1,
name: 'John Doe',
email: 'john.doe@example.com',
},
},
});
});
it('sends a request according to the contract', async () => {
const res = await axios.get('http://localhost:1234/users/1');
expect(res.status).toBe(200);
expect(res.data).toEqual({
id: 1,
name: 'John Doe',
email: 'john.doe@example.com',
});
});
});
// Verify that the provider has met all the contract requirements
afterAll(() => provider.verify());
});
If the provider changes and doesn't meet the contract requirements, this test will fail, alerting us to the incompatibility before it causes issues in a live environment.
Consumer-Driven Contracts
Consumer-driven contracts (CDC) are a pattern where the contract is written from the perspective of the consumer service. It defines how the consumer service uses the provider service's API. These contracts are shared with the provider, who can use them to ensure they don't introduce changes that would break their consumers.
In CDC, each consumer specifies what they expect from the provider, which allows multiple consumers to define their contracts with the same provider. As the provider service evolves, it checks its changes against these contracts to ensure it doesn't break any existing consumers.
Feature Toggles
Feature toggles, also known as feature flags, provide a way to modify a system's behavior without changing its codebase. They separate code deployment from feature release, allowing developers to deploy code to production while keeping new features hidden until they're ready for release.
This can be particularly useful in a microservices environment where different services may be at different stages of feature readiness. Feature toggles allow you to roll out features gradually, test them in production with a small set of users, and quickly roll them back if issues are found.
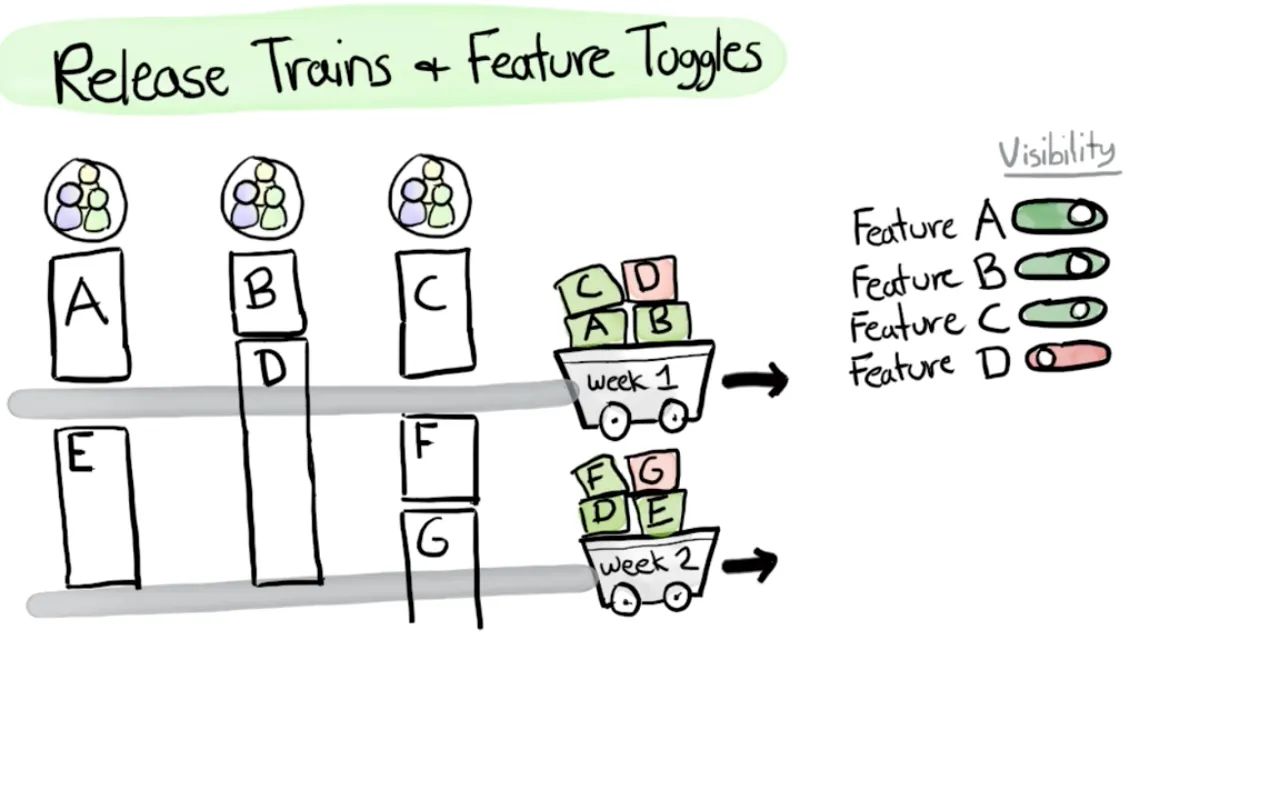
On the image above, you see multiple teams developing A,B,C,D features in parallel and having a weekly deployment process. Releases are decoupled from deployments and happen with enabling the feature flags.
Graceful Degradation and Fallback
Designing your services to degrade gracefully in the event of certain features or dependencies being unavailable can improve your system's resilience. This can be achieved by implementing fallback strategies in your services.
For instance, if a service depends on another service that is currently down, instead of failing outright, it could fall back to a cached version of the data, or it could return a default value, or an error message that does not disrupt the user experience.
Example - let's say you have a microservice "OrderService" which fetches the user's details from "UserService" in order to process an order. If the "UserService" is unavailable, the "OrderService" could degrade gracefully by processing the order without the user's details.
Here's how you might implement this in TypeScript using Axios and the circuit breaker pattern with the opossum library:
import axios from 'axios';
import CircuitBreaker from 'opossum';
// Define a function to fetch user details
const fetchUserDetails = async (userId: string) => {
const response = await axios.get(`http://user-service/users/${userId}`);
return response.data;
};
// Create a circuit breaker for the fetchUserDetails function
const options = {
timeout: 3000, // If our function takes longer than 3 seconds, trigger a failure
errorThresholdPercentage: 50, // When 50% of requests fail, trip the circuit
resetTimeout: 10000, // After 10 seconds, try again
};
const breaker = new CircuitBreaker(fetchUserDetails, options);
// Define a fallback function to use when the breaker is open
breaker.fallback(() => ({
message: 'User service is currently unavailable. Processing order without user details.',
}));
// Use the circuit breaker to fetch user details
const userId = '123';
breaker.fire(userId)
.then(userDetails => console.log(userDetails))
.catch(error => console.error(error));
In this example, if more than 50% of the requests to fetch user details fail, the circuit breaker will "trip" and start returning the fallback response instead. This allows the "OrderService" to continue processing orders even when the "UserService" is unavailable, degrading gracefully in the face of errors.
It's also worth noting that the circuit breaker will automatically reset after a certain period of time (10 seconds in this case), at which point it will try to call the fetchUserDetails function again. If the function is successful, the circuit breaker will close and start calling the function directly again. If the function fails, the circuit breaker will trip again and continue returning the fallback response.
Service Mesh
In a microservices architecture, a service mesh can provide crucial capabilities to ensure compatibility and smooth releases. A service mesh is a dedicated infrastructure layer that controls service-to-service communication over a network.
It can provide capabilities such as traffic shifting (for blue-green deployments or canary releases), fault injection (for chaos engineering and testing), and circuit breaking (to prevent failures from cascading through your system).
Conclusion
Ensuring backward and forward compatibility in a microservices environment requires careful planning and design, but the benefits of a robust, resilient system far outweigh the effort. The strategies and techniques covered here, from API versioning and database evolution to contract testing and graceful degradation, can help manage the complexity and keep your services interacting seamlessly through each release cycle.
The key to success lies in understanding that every change is an opportunity for improvement, not just a potential source of breakage. By following these strategies and best practices, you can guide the evolution of your microservices and enable your teams to deliver better, more reliable software, faster.
Remember that specific practices will vary based on your application's unique requirements and constraints. There is no one-size-fits-all solution, and the best approach is the one that works best for your team and your application.