

Table of Links
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
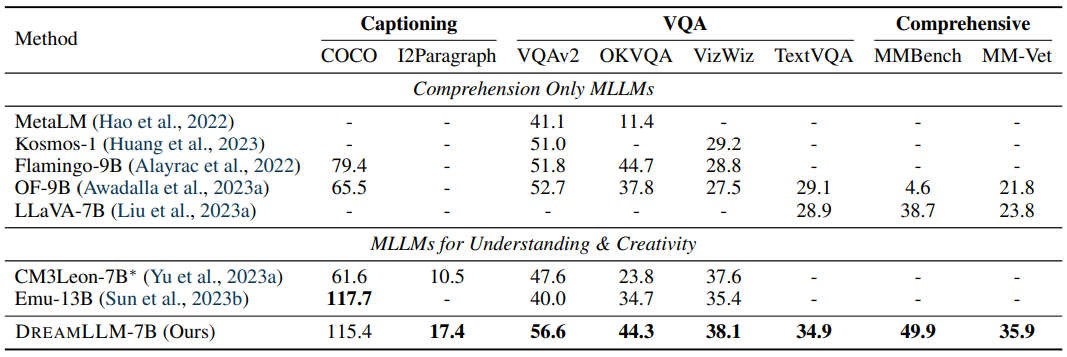
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
3.1 END-TO-END INTERLEAVED GENERATIVE PRETRAINING (I-GPT)
All natural documents can be regarded as carriers of text-image interleaved information. Text-only, images-only, and text-image pairs data, on the other hand, can be seen as special cases of interleaved corpora with different modality compositions. Thus, it is critical to empower the model with the capability to learn and generate free-form interleaved documents that form all possible distributions.
Interleaved Structure Learning To model the interleaved structure, the interleaved sequence is operated by extending a new special token before images. During training, DREAMLLM is trained to predict this token that indicates where an image emerges, and the conditional image synthesis is performed afterward, as introduced next. During inference, DREAMLLM will generate an image on its “free will” when this token is predicted.

This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.