
Table of Links
2 Architectural details and 2.1 Sparse Mixture of Experts
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
6 Conclusion, Acknowledgements, and References
4 Instruction Fine-tuning
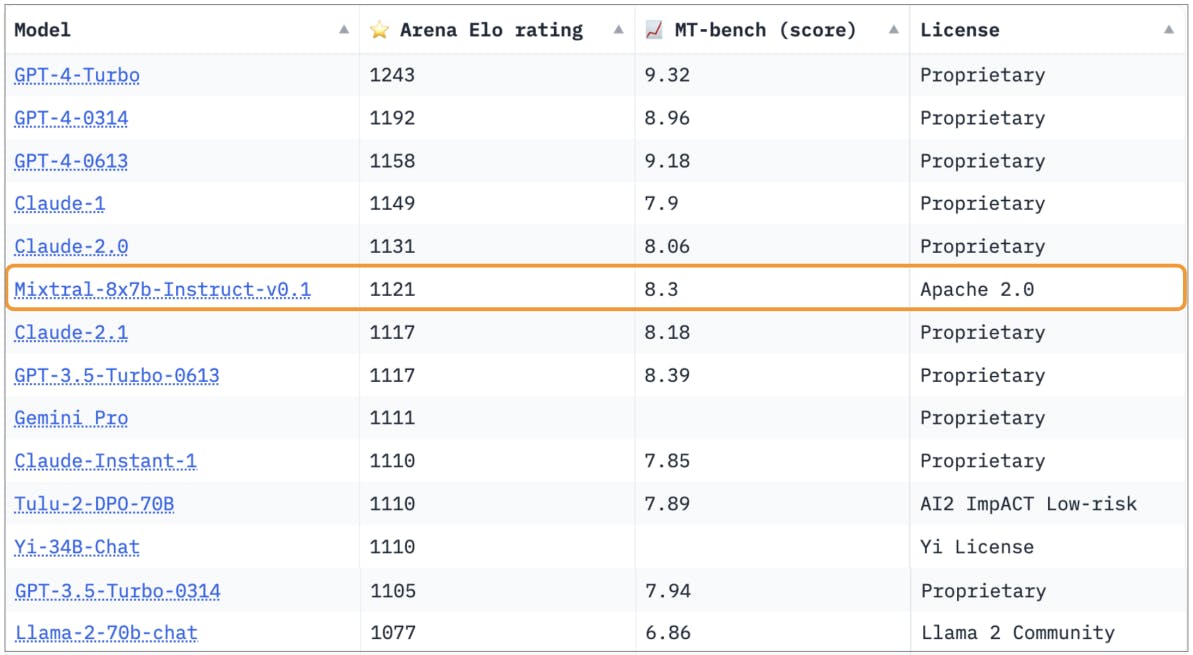
We train Mixtral – Instruct using supervised fine-tuning (SFT) on an instruction dataset followed by Direct Preference Optimization (DPO) [25] on a paired feedback dataset. Mixtral – Instruct reaches a score of 8.30 on MT-Bench [33] (see Table 2), making it the best open-weights model as of December 2023. Independent human evaluation conducted by LMSys is reported in Figure 6 [3] and shows that Mixtral – Instruct outperforms GPT-3.5-Turbo, Gemini Pro, Claude-2.1, and Llama 2 70B chat.
This paper is available on arxiv under CC 4.0 license.
[3] https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Authors:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Antoine Roux;
(4) Arthur Mensch;
(5) Blanche Savary;
(6) Chris Bamford;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) Emma Bou Hanna;
(10) Florian Bressand;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Guillaume Lample;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) Marie-Anne Lachaux;
(17) Pierre Stock;
(18) Sandeep Subramanian;
(19) Sophia Yang;
(20) Szymon Antoniak;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) Thibaut Lavril;
(24) Thomas Wang;
(25) Timothée Lacroix;
(26) William El Sayed.