
Introduction to Spring Batch
Spring Batch is a powerful module of the Spring framework that provides out-of-the-box implementation for batch processing tasks.
It is used in scenarios where data needs to be processed in multiple batches, for example, generating daily reports, periodic import of data into a database, or for any complex calculations and transformations of your data.
A typical batch-processing application involves the following steps:
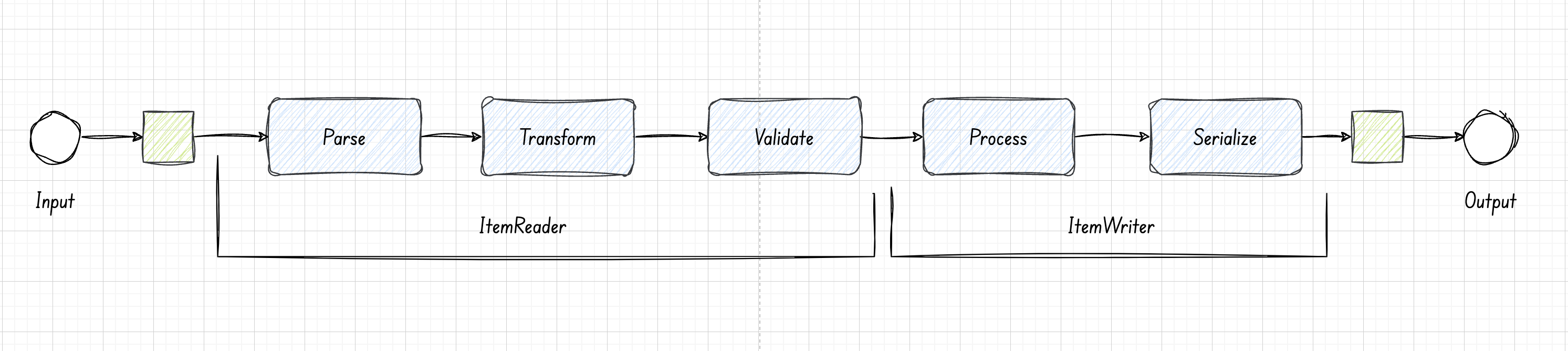
All the above steps can be achieved without using the spring batch. However, the spring batch provides the following benefits which makes a strong case for the framework.
-
You do not need to reinvent the wheel.
-
Seamless integration with the Spring ecosystem.
-
Chunk-based processing.
-
Includes I/O capabilities such as support for a wide range of data sources and targets, including databases, XML, JSON, and flat files.
-
Detailed monitoring and logging: Allows tracking of job and step execution, making it easier to understand the status and performance of batch jobs.
Spring Batch provides two different ways to implement a job. We can process data using Tasklets and Chunks.
- A Tasklet is a single task within a step. The
Taskletinterface defines a single methodexecute(), called once during the step execution.
- A Chunk-based approach is more suitable for processing large datasets where data can be read, processed, and written in smaller, manageable chunks. This is typically used for reading data from a database or a file and processing it record by record. The chunk model is built around three main components;
Reader,WriterandProcessor
Spring Boot Batch Chunk Processing
The key components of a Spring boot batch application include: - Job - Step - Readers, Writers, Processors - Job Repository - Job Launcher
The primary components of the Spring Batch and overall process flow are shown in the figure below.
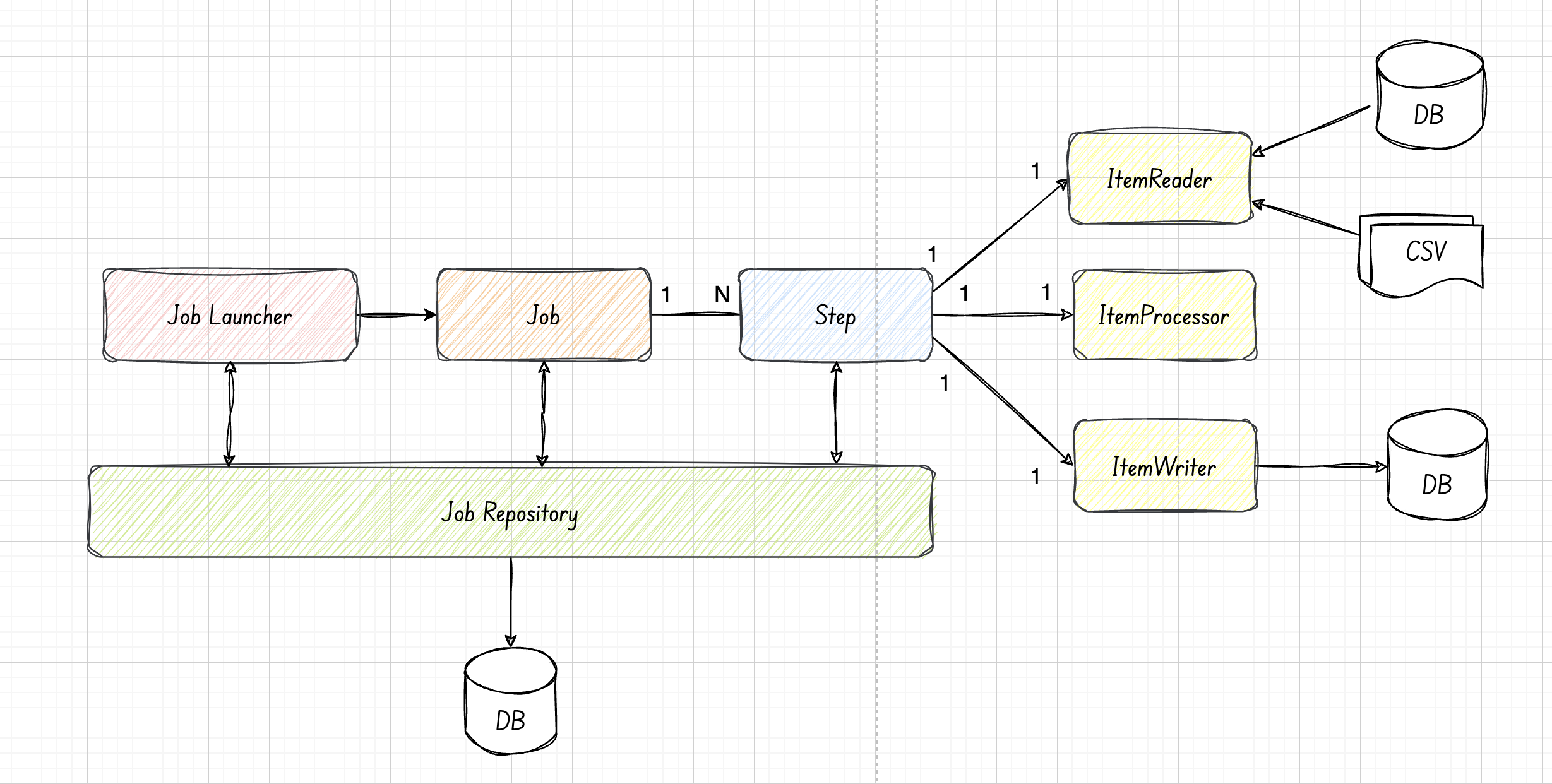
JobLauncher:
The JobLauncher is an interface that represents the component responsible for running the jobs. It takes care of receiving job parameters and launching a job with those parameters. It's typically used to start a job from different triggers such as an application event, a REST API call, or from scheduler.
Job:
A Job in Spring Batch is an entity that encapsulates an entire batch process and is defined by a series of steps.
Step: A single job may have one or more steps, where each step typically involves reading data, processing it, and writing the processed data to the output source.
ItemReader:
The ItemReader is responsible for reading data from different sources such as databases or files. The ItemReader has a read() method; every time this method is invoked, it will return one item. If there are no more items to read, it returns null to indicate the end of the data input.
The FlatFileItemReader can be used for reading data from flat files (like CSV), JdbcCursorItemReader for reading from databases using a JDBC cursor, and JpaPagingItemReader can be used for reading database records using JPA pagination.
ItemProcessor:
The ItemProcessor is completely optional. It is used to validate, transform, or filter the items before passing them to the ItemWriter.
ItemWriter:
The ItemWriter takes processed items and writes them to a database or a file. The FlatFileItemWriter can be used for writing data to flat files, JdbcBatchItemWriter for batching database operations through JDBC, and JpaItemWriter for handling database operations using JPA.
Job Repository:
The JobRepository does all the hard work such as recording the status of jobs in a database. It keeps track of which jobs are running, which have been completed, and if a job fails, what step it failed at. This is critical for jobs that need to be restarted after a failure, ensuring that the job can pick up where it left off.
Load CSV Data to Postgres SQL Using Spring Batch
This example uses chunk-based processing for reading CSV files, processing them, and then storing them in Postgres SQL. For managing the database migrations, we will use Flyway.
Learn more about Spring Batch in an in-depth video tutorial:
Dependencies
Use Spring Initializr to bootstrap a spring boot project by selecting the required dependencies. This example uses Java 17 and Spring Boot 3.2.4 and has the following dependencies.
- Spring Batch
- Spring Data JPA
- PostgreSQL Driver
- Lombok - completely optional for reducing boilerplate code.
- Flyway - Database migration
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-batch'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
runtimeOnly 'org.postgresql:postgresql'
implementation 'org.flywaydb:flyway-core:10.10.0'
runtimeOnly 'org.flywaydb:flyway-database-postgresql:10.10.0'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.batch:spring-batch-test'
}
Configuring Database Properties
Let us now configure the data source and batch configuration in the application.properties file.
spring.datasource.url=jdbc:postgresql://localhost:5432/spring_batch
spring.datasource.username=postgres
spring.datasource.password=Passw0rd
spring.datasource.driver-class-name=org.postgresql.Driver
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.jdbc.lob.non_contextual_creation=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
Define Your Domain Model
In this example, we will read the customer data from the CSV (customers.csv) file, and insert it into PostgreSQL. Each row in the customers.csv file has the following columns.
You can download the sample customers.csv file from here.
Index,Customer Id,First Name,Last Name,Company,City,Country,Phone
1,Phone 2,Email,Subscription Date,Website1,4962fdbE6Bfee6D,Pam,Sparks,Patel-Deleon,Blakemouth,British Indian Ocean Territory (Chagos Archipelago),267-243-9490x035,480-078-0535x889,[email protected],2020-11-29,https://nelson.com/
2,9b12Ae76fdBc9bE,Gina,Rocha,"Acosta, Paul and Barber",East Lynnchester,Costa Rica,027.142.0940,+1-752-593-4777x07171,[email protected],2021-01-03,https://pineda-rogers.biz/
3,39edFd2F60C85BC,Kristie,Greer,Ochoa PLC,West Pamela,Ecuador,+1-049-168-7497x5053,+1-311-216-7855,[email protected],2021-06-20,https://mckinney.com/
Let us now create an entity class with fields matching the CSV row. I have intentionally ignored the Index column as we do not want to import it into our database.
@Builder
@Data
@Entity
@Table(name = "customers")
@AllArgsConstructor
@NoArgsConstructor
public class Customer {
@Id
private String customerId;
private String firstName;
private String lastName;
private String company;
private String city;
private String country;
private String phone1;
private String phone2;
private String email;
private LocalDate subscriptionDate;
private String website;
Create a Repository
We will use Spring Data JPA to handle database operations. Let us now create a repository for the Customer entity. This JPA repository will be used by the writer to save data to Postgres DB.
@Repositorypublic interface CustomerRepository extends JpaRepository<Customer, Long> {
}
Flyway Migrations Scripts
Spring Batch uses a database backend to maintain the state of the job execution. It can resume the job execution from the point of failure.
The state is maintained in an SQL database. The list of supported database schemas can be found here.
For the database migration, we will use Flyway. For Flyway to work, we need to add the flyway dependency and the following configurations to the application.properties file.
spring.flyway.enabled=true
spring.flyway.locations=classpath:db/migration
Let us now create two migration scripts inside the resources/db/migration directory.
-
V1__added_spring_batch_tables.sql- Spring batch schemas for Postgres SQL can be found here. -
v2__added_customers_table.sql- Contains schema for customer table.
CREATE TABLE customers
(
subscription_date DATE,
city CHARACTER VARYING(255),
company CHARACTER VARYING(255),
country CHARACTER VARYING(255),
customer_id CHARACTER VARYING(255) NOT NULL,
email CHARACTER VARYING(255),
first_name CHARACTER VARYING(255),
last_name CHARACTER VARYING(255),
phone1 CHARACTER VARYING(255),
phone2 CHARACTER VARYING(255),
website CHARACTER VARYING(255),
PRIMARY KEY (customer_id)
);
Configure Spring Batch
Let us now define a SpringBatchConfig class to set up the Spring Batch job and annotate it with @Configuration and @EnableBatchProcessing annotation.
The @EnableBatchProcessing annotation enables Spring Batch features and provides a base configuration for setting up batch jobs in an @Configuration class.
This class will contain the configuration for the Step, Job, ItemReader, and ItemWriter.
@Configuration
@EnableBatchProcessing
public class SpringBatchConfig {
@Bean
public FlatFileItemReader<Customer> reader() {
//TODO
}
@Bean
public JpaItemWriter<Customer> writer() {
//TODO
}
@Bean
public Job csvImporterJob(Step customerStep, JobRepository jobRepository) {
return new JobBuilder("csvImporterJob", jobRepository)
.incrementer(new RunIdIncrementer())
.flow(customerStep)
.end()
.build();
}
@Bean
public Step csvImporterStep(
ItemReader<Customer> csvReader, ItemWriter<Customer> csvWriter,
JobRepository jobRepository, PlatformTransactionManager tx) {
return new StepBuilder("csvImporterStep", jobRepository)
.<Customer, Customer>chunk(50, tx)
.reader(csvReader)
.writer(csvWriter)
.allowStartIfComplete(true)
.build();
}
}
The flow() method defines the flow of the job, starting with customerStep, and the end() method marks the end of the job flow. If you have multiple steps for your batch job, you can specify using the next(step2) method.
We will use chunk-based processing and the chunk size to process at a single time is configured using the chunk() method on Step configuration.
ItemReader Configuration
The ItemReader bean is responsible for reading data from a CSV file and mapping the data to Java objects. In this case, it is of type Customer.
Spring batch provides FlatFileItemReader class to parse the customers.csv file from our classpath. Ensure the customers.csv file is present in your /src/main/resources directory.
@Bean
public FlatFileItemReader<Customer> reader() {
return new FlatFileItemReaderBuilder<Customer>()
.linesToSkip(1)
.name("csvItemReader")
.resource(new ClassPathResource("customers.csv"))
.delimited()
.delimiter(",")
.names("index", "customerId", "firstName", "lastName", "company", "city", "country", "phone1", "phone2",
"email", "subscriptionDate", "website")
.fieldSetMapper(fieldSet -> Customer.builder()
.customerId(fieldSet.readString("customerId"))
.firstName(fieldSet.readString("firstName"))
.lastName(fieldSet.readString("lastName"))
.company(fieldSet.readString("company"))
.city(fieldSet.readString("city"))
.country(fieldSet.readString("country"))
.phone1(fieldSet.readString("phone1"))
.phone2(fieldSet.readString("phone2"))
.email(fieldSet.readString("email"))
.subscriptionDate(DateUtils.parseDate(fieldSet.readString("subscriptionDate")))
.website(fieldSet.readString("website"))
.build()
).build();
}
- The
linesToSkip()method is used to skip a specified number of rows while reading the file. This is particularly used to skip the header row of the CSV file.
- The
delimiter()method specifies the delimiter used in the file to separate the fields.
- The
names()method specifies the column names in the CSV file. It is important to maintain the order of the column names as they appear in the source CSV file. These names map values from each column to fields in theCustomerobject.
- The
fieldSetMapper()defines how to map fields from the CSV to theCustomerobject.
In this example, we are manually mapping each field and setting the values to the Customer object. But if you want to parse all the fields from CSV, and if it maps exactly to the field names, you can use BeanWrapperFieldSetMapper to automatically map each column to a Java object.
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(Customer.class);
}})
ItemWriter Configuration
For saving the data into the database using JPA, we will create an instance of JpaItemWriter and set the EntityManagerFactory bean.
The EntityManagerFactory is configured automatically by Spring Boot when we add the Spring Data JPA to our classpath. Thanks to the Spring boot auto configuration.
@Bean
public JpaItemWriter<Customer> writer(EntityManagerFactory entityManagerFactory) {
JpaItemWriter<Customer> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
return writer;
}
With this, we are done with the job configurations.
Running a Job
The job can triggered from a command line runner, from a REST controller, using a Spring Scheduler cron job, or from application events.
We will use an application-ready event to trigger the job in this example. This will trigger the job immediately after the application starts.
@Component
@RequiredArgsConstructor
public class ApplicationStartEvent {
private final JobLauncher jobLauncher;
private final Job csvImporterJob;
@EventListener(ApplicationReadyEvent.class)
public void onReadyEvent() throws JobExecutionException {
jobLauncher.run(csvImporterJob, new JobParameters());
}
}
Now, build and run the application. Notice that the importer job will be triggered and CSV file content will be imported into the Postgres database.
Job Execution Listener
During the Job execution of a Job, it may be useful to be notified of various events in its lifecycle. For that, we can create a listener for the importer job by implementing the JobExecutionListener interface.
The JobExecutionListener interface has beforeJob() and afterJob() methods. As the name indicates, they are triggered accordingly based on the Job lifecycle. Note that the afterJob() method is called regardless of the success or failure of the Job.
For now, we are logging but you can add your custom business logic here.
@Slf4j
@Component
public class ImportJobListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
log.info("Job:{} execution started", jobExecution.getJobInstance().getJobName());
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("Job completed: {}", jobExecution.getJobInstance().getJobName());
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
log.error("Error while running job: {}", jobExecution.getJobInstance().getJobName());
}
}
}
The custom job listener can be added to the job by calling the listener() method on JobBuilder.
@Bean
public Job csvImporterJob(Step customerStep, JobRepository jobRepository,
ImportJobListener importJobListener) {
return new JobBuilder("csvImporterJob", jobRepository)
.incrementer(new RunIdIncrementer())
.listener(importJobListener)
.flow(customerStep)
.end()
.build();
}
Passing Job Parameters
While running a job, we can also pass the runtime parameters using JobParameters . The Spring batch can parse the job parameters while running the task, and you can use custom logic based on your use case.
For example, let us pass ignoreCountry parameter to our import job, and ignore the customers that are from 'India.'
@Component
@RequiredArgsConstructor
public class ApplicationStartEvent {
private final JobLauncher jobLauncher;
private final Job csvImporterJob;
@EventListener(ApplicationReadyEvent.class)
public void onReadyEvent() throws JobExecutionException {
JobParameters jobParameters = new JobParametersBuilder()
.addString("ignoreCountry", "India")
.toJobParameters();
jobLauncher.run(csvImporterJob, jobParameters);
}
}
You can read the parameters passed to the job using getCurrentJobParameters() method.
JobParameters jobParameters = jobLauncher.getCurrentJobParameters();
String ignoreCountry = jobParameters.getString("ignoreCountry");
To exclude customers based on the parameter, we will create a custom processor to filter the customers based on customer location.
To access the parameters from the processor, we need to obtain the JobExecution linked to the current execution context.
Since ItemProcessor does not have access to job parameters directly, you can use StepExecutionListener to inject these parameters before the step begins.
The @JobScope annotation can be used on the processor to bind the job lifecycle to execute a job. This allows us to inject job parameters directly into the processor using Spring Expression Language (SpEL).
@Slf4j
@StepScope
@Component
public class CustomerJobProcessor implements ItemProcessor<Customer, Customer> {
private final String ignoreCountry;
public CustomerJobProcessor(@Value("#{jobParameters['ignoreCountry']}") String ignoreCountry) {
this.ignoreCountry = ignoreCountry;
}
@Override
public Customer process(Customer customer) {
if (customer.getCountry().equalsIgnoreCase(ignoreCountry)) {
log.info("Ignoring customer {} {} belongs to country {}", customer.getFirstName(),
customer.getLastName(), customer.getCountry());
return null;
}
return customer;
}
}
We can optionally validate job parameters at runtime using JobParametersValidator and override the validate() method.
@Bean
public Job csvImporterJob(Step customerStep, JobRepository jobRepository,
ImportJobListener importJobListener) {
return new JobBuilder("csvImporterJob", jobRepository)
.incrementer(new RunIdIncrementer())
.validator(new JobParametersValidator() {
@Override
public void validate(JobParameters parameters) throws JobParametersInvalidException {
String ignoreCountry = parameters.getString("ignoreCountry");
if ("Costa Rica".equals(ignoreCountry)) {
throw new JobParametersInvalidException("Country ignored");
}
}
})
.listener(importJobListener)
.flow(customerStep)
.end()
.build();
}
That is all! Now, you have a fully functional CSV importer service.