

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(2) Chunyang Chen, Monash University, Melbourne, Australia;
(3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author;
(4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author.
Table of Links
Motivational Study and Background
Discussion and Threats to Validity
5 RESULTS AND ANALYSIS
5.1 Bugs Detection Performance (RQ1)
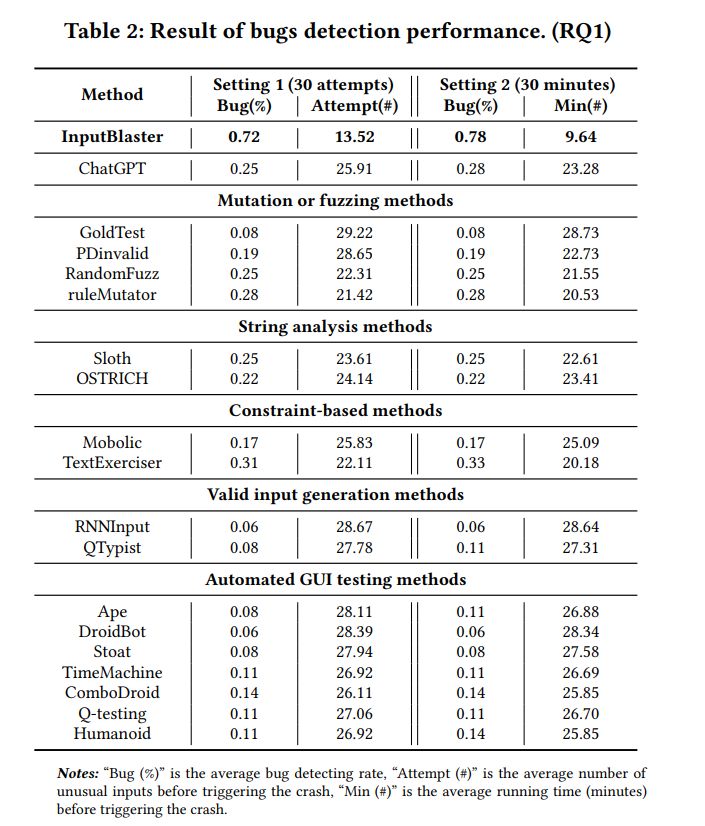
Table 2 presents the bug detection performance of InputBlaster. With the unusual inputs generated by InputBlaster, the bug detection rate is 0.78 (within 30 minutes), indicating 78 (28/36) of the bugs can be detected. In addition, the bugs can be detected with an average of 13.52 attempts, and the average bug detection time is 9.64 minutes, which is acceptable. This indicates the effectiveness of our approach in generating unusual inputs for testing the app, and facilitating the uncovering of bugs related to input widgets.
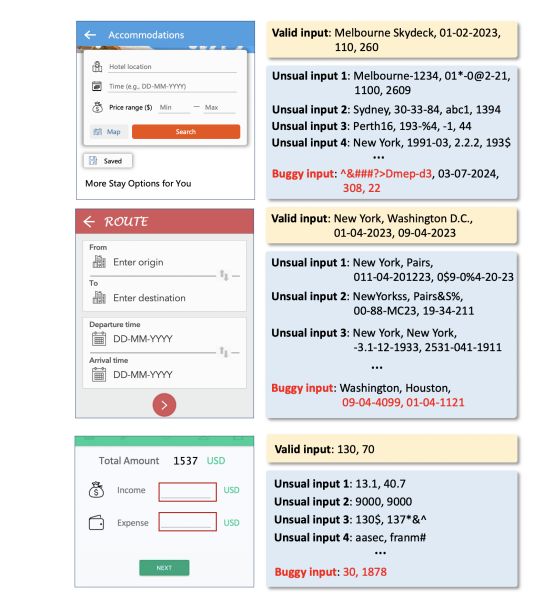
Figure 5 demonstrates examples of InputBlaster’s generated unusual inputs and the inputs that truly trigger the crash. We can see that our proposed approach can generate quite diversified inputs which mutate the valid input from different aspects, e.g., for the price in the first example which should be a non-negative value, the generated unusual inputs range from negative values and decimals to various kinds of character strings. Furthermore, it is good at capturing the contextual semantic information of the input widgets and their associated constraints, and generating the violations accordingly. For example, for the minimum and maximum price in the first example, it generates the unusual inputs with the minimum larger than the maximum, and successfully triggers the crash.
We further analyze the bugs that could not be detected by our approach. A common feature is that they need to be triggered under specific settings, e.g., only under the user-defined setting, the input can trigger the crash, in the environment we tested, it may not have been possible to trigger a crash due to the lack of user-defined settings in advance. We have manually compared the unusual inputs generated by our approach with the ones in the issue reports. We find in all cases, InputBlaster can generate the satisfied buggy inputs within 30 attempts and 30 minutes, which further indicates its effectiveness.
Performance comparison with baselines. Table 2 also shows the performance comparison with the baselines. We can see that our proposed InputBlaster is much better than the baselines, i.e., 136% (0.78 vs. 0.33) higher in bug detection rate (within 30 minutes) compared with the best baseline Text Exerciser. This further indicates the advantages of our approach. Nevertheless, the Text Exerciser can only utilize the dynamic hints in input generation which covers a small portion of all situations, i.e., a large number of input widgets do not involve such feedback.
Without our elaborate design, the raw ChatGPT demonstrates poor performance, which further indicates the necessity of our approach. In addition, the string analysis methods, which are designed specifically for string constraints, would fail to work for mobile apps. In addition, since the input widgets of mobile apps are more diversified (as shown in Section 2.1.2) compared with the string, the heuristic analysis or finite-state automata techniques in the string analysis methods might be ineffective for our task. The baselines for automated GUI testing or valid text input generation are even worse, since their main focus is to increase the coverage through generating valid inputs. This further implies the value of our approach for targeting this unexplored task.
5.2 Ablation Study (RQ2)
5.2.1 Contribution of Modules. Table 3 shows the performance of InputBlaster and its 2 variants respectively removing the first and third module. In detail, for InputBlaster w/o valid Input (i.e., without Module 1), we provide the information related to the input widgets (as Table 1 P1) to the LLM in Module 2 and set other information from Module 1 as “null”. For InputBlaster w/o enrich Examples (i.e., without Module 3), we set the examples from Module 3 as “null” when querying the LLM. Note that, since Module 2 is for generating the unusual inputs which is indispensable for this task, hence we do not experiment with this variant.

We can see that InputBlaster’s bug detection performance is much higher than all other variants, indicating the necessity of the designed modules and the advantage of our approach.
Compared with InputBlaster, InputBlaster w/o validInput results in the largest performance decline, i.e., 50% drop (0.39 vs. 0.78) in bug detection rate within 30 minutes. This further indicates that the generated valid inputs and inferred constraints in Module 1 can help LLM understand what the correct input looks like and generate the violated ones.
InputBlaster w/o enrichExamples also undergoes a big performance decrease, i.e., 32% (0.53 vs. 0.78) in bug detection rate within 30 minutes, and the average testing time increases by 109% (9.64 vs. 20.15). This might be because without the examples, the LLM would spend more time understanding user intention and criteria for what kinds of answers are wanted.
5.2.2 Contribution of Sub-modules. Table 4 further demonstrates the performance of InputBlaster and its 5 variants. We remove each sub-module of the InputBlaster in Figure 3 separately,
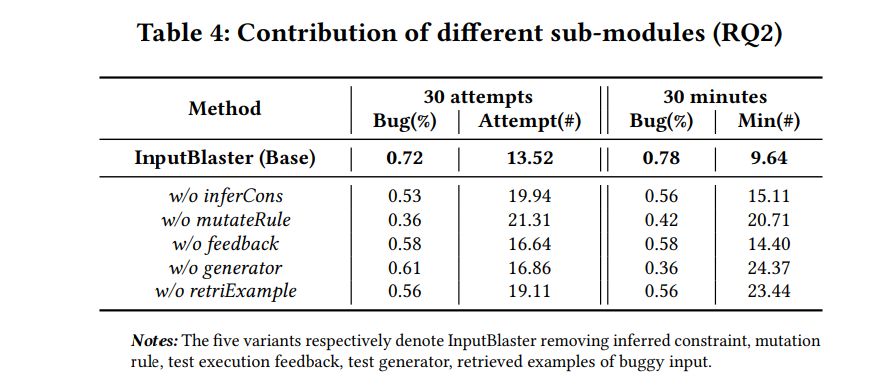
i.e., inferred constraint, mutation rule, text execution feedback, test generator and retrieved examples of buggy input. For removing the test generator, we directly let the LLM generate the unusual inputs, and for removing retrieved examples, we use the random selection method. For other variants, we set the removed content as “null”.
The experimental results demonstrate that removing any of the sub-modules would result in a noticeable performance decline, indicating the necessity and effectiveness of the designed sub modules.
Removing the mutation rules (InputBlaster w/o-mutateRule) have the greatest impact on the performance, reducing the bug detection rate by 50% (0.36 vs. 0.72 within 30 attempts). Remember that, InputBlaster first lets the LLM to generate the mutation rules (how to mutate the valid inputs), then asks it to produce the test generator following the mutation rule. With the generated mutation rules serving as the reasoning chain, the unusual input generation can be more effective, which further proves the usefulness of our design.
We also notice that, when removing the test generator (InputBlaster w/o-generator), the bug detection rate does not drop much (0.72 vs. 0.61) when considering 30 attempts, yet it declines a lot (0.78 vs. 0.36) when considering 30 minutes of testing time. This is because our proposed approach lets the LLM produce the test generator which can yield a batch of unusual inputs. This means interacting with the LLM once can generate multiple outcomes. However, if asking the LLM to directly generates unusual inputs (i.e., InputBlaster w/o-generator), it requires interacting with LLM frequently, and could be quite inefficient. This further demonstrates we formulate the problem as producing the test generator task is efficient and valuable.
In addition, randomly selecting the examples (InputBlaster w/oretriExample) would also largely influence the performance, and decrease the bug detection rate by 22% (0.56 vs. 0.72 within 30 attempts). This indicates that by providing similar examples, the LLM can quickly think out what should the unusual inputs look like. Nevertheless, we can see that, compared with the variant without enriched examples in prompt (Table 3), the randomly selected examples do take effect (0.47 vs 0.56 in bug detection rate within 30 attempts), which further indicates the demonstration can facilitate the LLM in producing the required output.
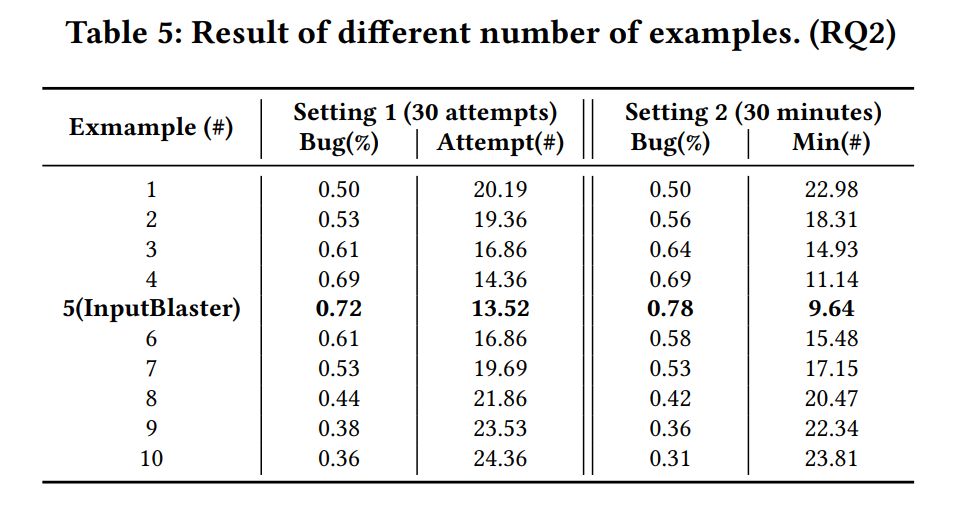
5.2.3 Influence of Different Number of Examples. Table 5 demonstrates the performance under the different number of examples provided in the prompt.
We can see that the number of detected bugs increases with more examples, reaching the highest bug detection rate with 5 examples. And after that, the performance would gradually decrease even increasing the examples. This indicates that too few or too many examples would both damage the performance, because of the tiny information or the noise in the provided examples.
5.3 Usefulness Evaluation (RQ3)
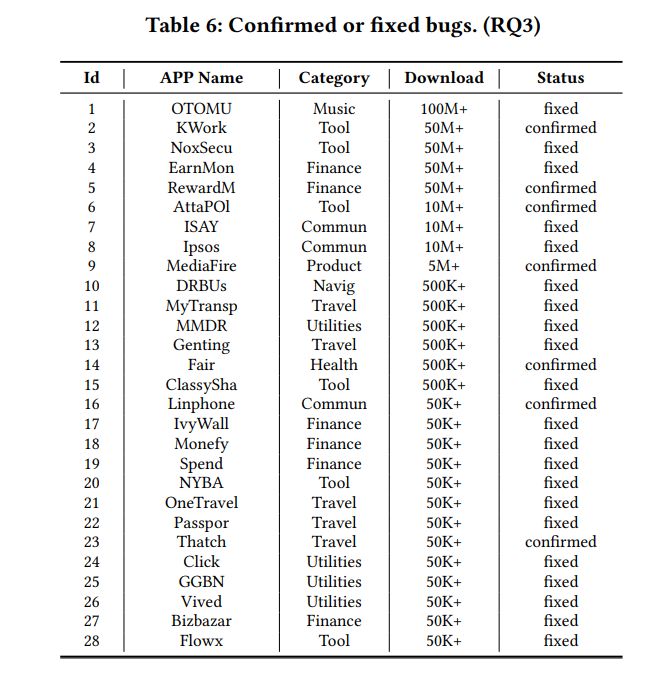
Table 6 shows all bugs spotted by Ape integrated with our InputBlaster, and more detailed information on detected bugs can be seen in our website. For the 131 apps, InputBlaster detects 43 bugs in 32 apps, of which 37 are newly-detected bugs. Furthermore, these new bugs are not detected by the Ape without InputBlaster.
We submit these 37 bugs to the development team, and 28 of them have been fixed/confirmed so far (21 fixed and 7 confirmed), while the remaining are still pending (none of them is rejected). This further indicates the effectiveness and usefulness of our proposed InputBlaster in bug detection.
When confirming and fixing the bugs, some Android app developers express thanks such as “Very nice! You find an invalid input we thought was too insignificant to cause crashes.”(i.e., Ipsos). Furthermore, some developers also express their thought about the buggy text input “Handling different inputs can be tricky, and I admit we couldn’t test for every possible scenario. It has given me a fresh appreciation for the complexity of user inputs and the potential bugs they can introduce. ”(i.e., DRBUs). Some developers also present valuable suggestions to facilitate the further improvement of InputBlaster. For example, some of them hope that we can find the patterns of these bugs and design repair methods.