
Table of Links
2 Architectural details and 2.1 Sparse Mixture of Experts
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
6 Conclusion, Acknowledgements, and References
3 Results
We compare Mixtral to Llama, and re-run all benchmarks with our own evaluation pipeline for fair comparison. We measure performance on a wide variety of tasks categorized as follow:
• Commonsense Reasoning (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• World Knowledge (5-shot): NaturalQuestions [20], TriviaQA [19]
• Reading Comprehension (0-shot): BoolQ [7], QuAC [5]
• Math: GSM8K [9] (8-shot) with maj@8 and MATH [17] (4-shot) with maj@4
• Code: Humaneval [4] (0-shot) and MBPP [1] (3-shot)
• Popular aggregated results: MMLU [16] (5-shot), BBH [29] (3-shot), and AGI Eval [34] (3-5-shot, English multiple-choice questions only)
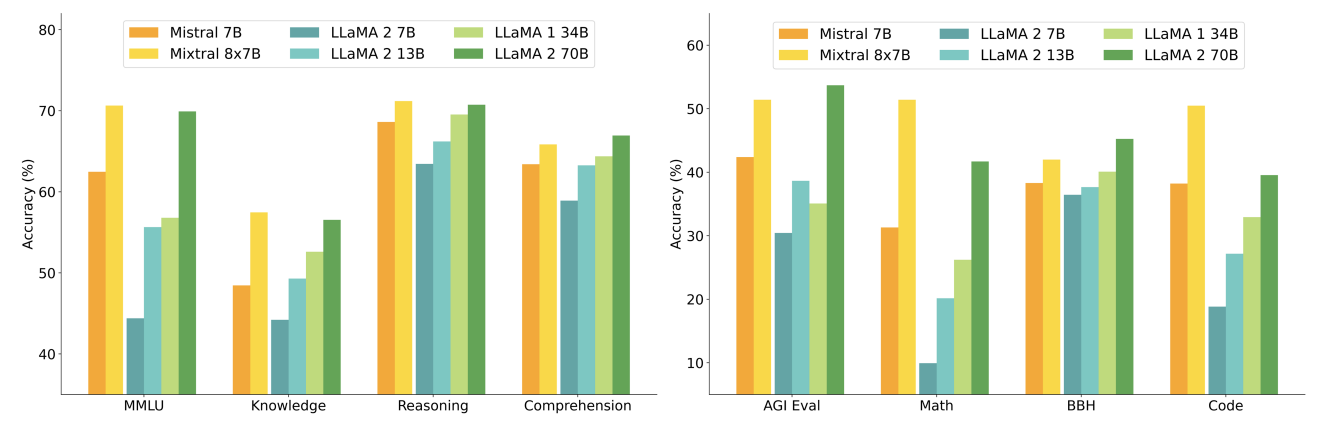
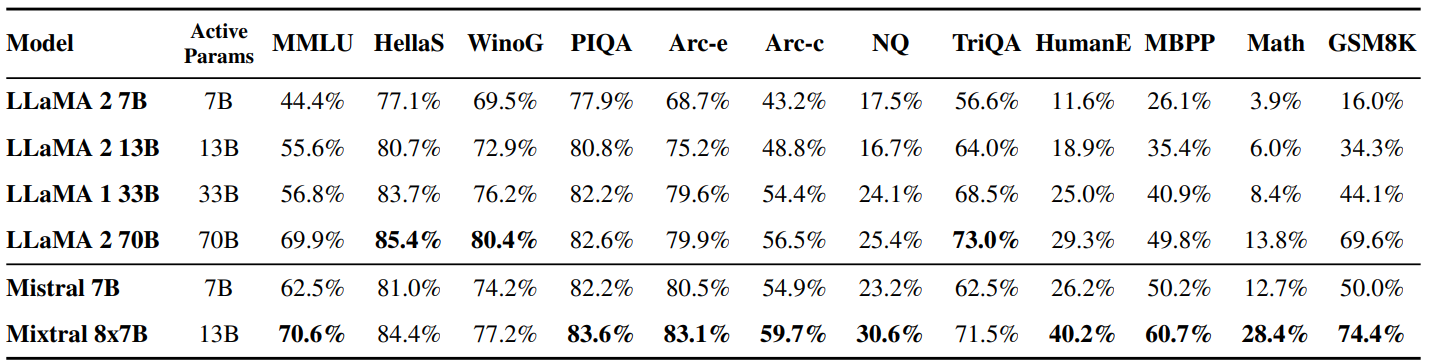
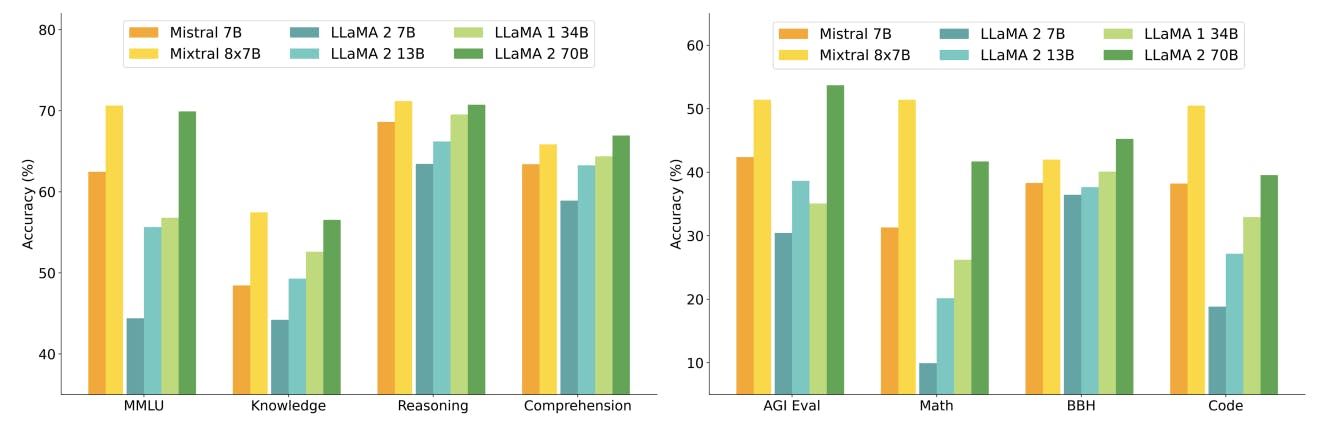
Detailed results for Mixtral, Mistral 7B and Llama 2 7B/13B/70B and Llama 1 34B[2] are reported in Table 2. Figure 2 compares the performance of Mixtral with the Llama models in different categories. Mixtral surpasses Llama 2 70B across most metrics. In particular, Mixtral displays a superior performance in code and mathematics benchmarks.
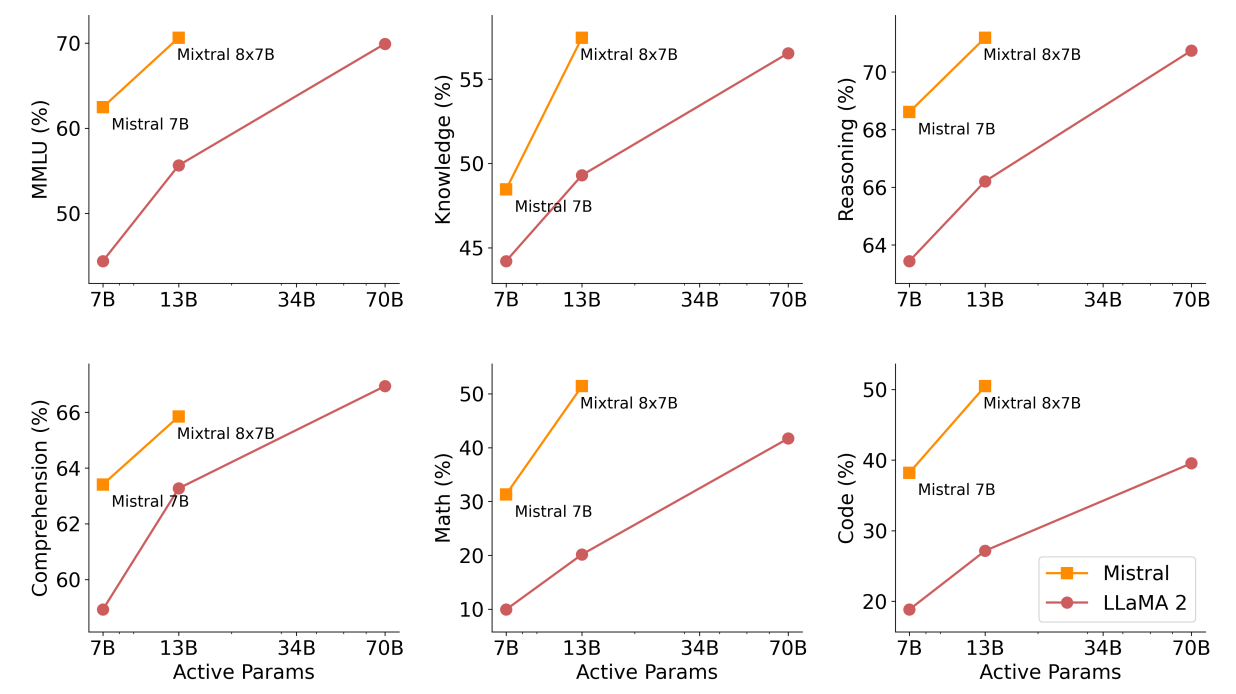
Size and Efficiency. We compare our performance to the Llama 2 family, aiming to understand Mixtral models’ efficiency in the cost-performance spectrum (see Figure 3). As a sparse Mixtureof-Experts model, Mixtral only uses 13B active parameters for each token. With 5x lower active parameters, Mixtral is able to outperform Llama 2 70B across most categories.
Note that this analysis focuses on the active parameter count (see Section 2.1), which is directly proportional to the inference compute cost, but does not consider the memory costs and hardware utilization. The memory costs for serving Mixtral are proportional to its sparse parameter count, 47B, which is still smaller than Llama 2 70B. As for device utilization, we note that the SMoEs layer introduces additional overhead due to the routing mechanism and due to the increased memory loads when running more than one expert per device. They are more suitable for batched workloads where one can reach a good degree of arithmetic intensity.
Comparison with Llama 2 70B and GPT-3.5. In Table 3, we report the performance of Mixtral 8x7B compared to Llama 2 70B and GPT-3.5. We observe that Mixtral performs similarly or above the two other models. On MMLU, Mixtral obtains a better performance, despite its significantly smaller capacity (47B tokens compared to 70B). For MT Bench, we report the performance of the latest GPT-3.5-Turbo model available, gpt-3.5-turbo-1106.
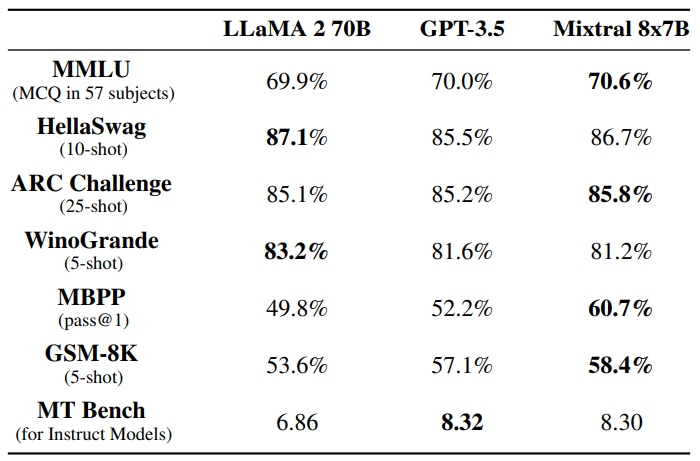
Evaluation Differences. On some benchmarks, there are some differences between our evaluation protocol and the one reported in the Llama 2 paper: 1) on MBPP, we use the hand-verified subset 2) on TriviaQA, we do not provide Wikipedia contexts.
This paper is available on arxiv under CC 4.0 license.
[2] Since Llama 2 34B was not open-sourced, we report results for Llama 1 34B.
Authors:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Antoine Roux;
(4) Arthur Mensch;
(5) Blanche Savary;
(6) Chris Bamford;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) Emma Bou Hanna;
(10) Florian Bressand;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Guillaume Lample;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) Marie-Anne Lachaux;
(17) Pierre Stock;
(18) Sandeep Subramanian;
(19) Sophia Yang;
(20) Szymon Antoniak;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) Thibaut Lavril;
(24) Thomas Wang;
(25) Timothée Lacroix;
(26) William El Sayed.