

Table of Links
6 Phi-3-Vision
A Example prompt for benchmarks
5 Weakness
In terms of LLM capabilities, while phi-3-mini model achieves similar level of language understanding and reasoning ability as much larger models, it is still fundamentally limited by its size for certain tasks.
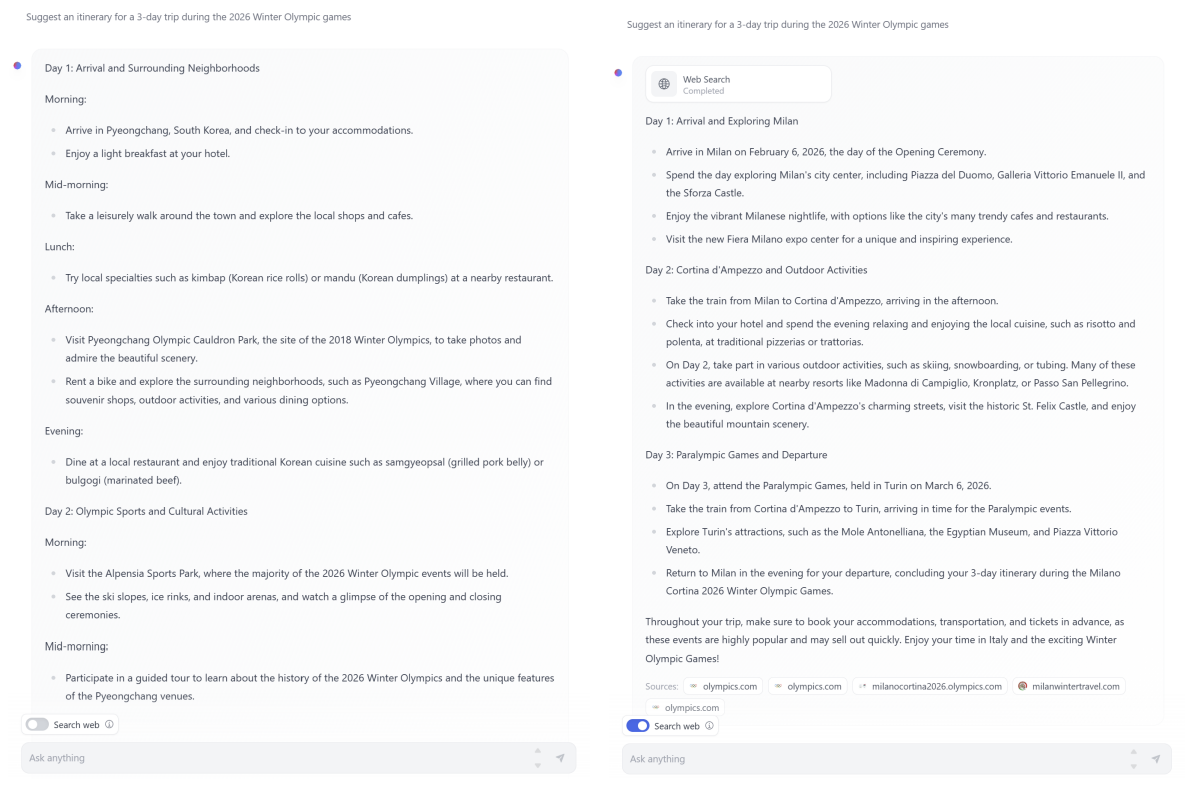
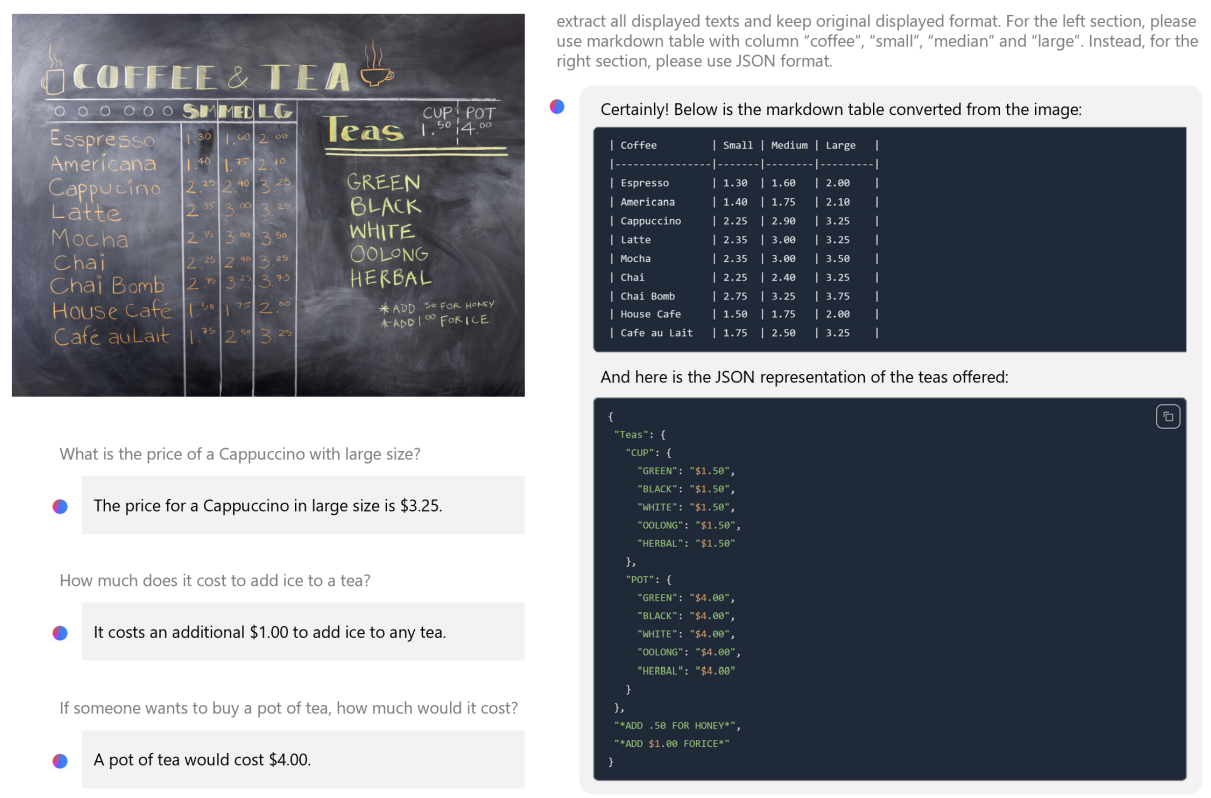
The model simply does not have the capacity to store too much “factual knowledge”, which can be seen for example with low performance on TriviaQA. However, we believe such weakness can be resolved by augmentation with a search engine. We show an example using the HuggingFace default Chat-UI with phi-3-mini in Figure 5. Another weakness related to model’s capacity is that we mostly restricted the language to English. Exploring multilingual capabilities for Small Language Models is an important next step, with some initial promising results on phi-3-small by including more multilingual data.
Despite our diligent RAI efforts, as with most LLMs, there remains challenges around factual inaccuracies (or hallucinations), reproduction or amplification of biases, inappropriate content generation, and safety issues. The use of carefully curated training data, and targeted post-training, and improvements from red-teaming insights significantly mitigates these issues across all dimensions. However, there is significant work ahead to fully address these challenges, and downstream use of the models should be evaluated for the specific use cases and safety considerations for that context.
Authors:
(1) Marah Abdin;
(2) Sam Ade Jacobs;
(3) Ammar Ahmad Awan;
(4) Jyoti Aneja;
(5) Ahmed Awadallah;
(6) Hany Awadalla;
(7) Nguyen Bach;
(8) Amit Bahree;
(9) Arash Bakhtiari;
(10) Jianmin Bao;
(11) Harkirat Behl;
(12) Alon Benhaim;
(13) Misha Bilenko;
(14) Johan Bjorck;
(15) Sébastien Bubeck;
(16) Qin Cai;
(17) Martin Cai;
(18) Caio César Teodoro Mendes;
(19) Weizhu Chen;
(20) Vishrav Chaudhary;
(21) Dong Chen;
(22) Dongdong Chen;
(23) Yen-Chun Chen;
(24) Yi-Ling Chen;
(25) Parul Chopra;
(26) Xiyang Dai;
(27) Allie Del Giorno;
(28) Gustavo de Rosa;
(29) Matthew Dixon;
(30) Ronen Eldan;
(31) Victor Fragoso;
(32) Dan Iter;
(33) Mei Gao;
(34) Min Gao;
(35) Jianfeng Gao;
(36) Amit Garg;
(37) Abhishek Goswami;
(38) Suriya Gunasekar;
(39) Emman Haider;
(40) Junheng Hao;
(41) Russell J. Hewett;
(42) Jamie Huynh;
(43) Mojan Javaheripi;
(44) Xin Jin;
(45) Piero Kauffmann;
(46) Nikos Karampatziakis;
(47) Dongwoo Kim;
(48) Mahoud Khademi;
(49) Lev Kurilenko;
(50) James R. Lee;
(51) Yin Tat Lee;
(52) Yuanzhi Li;
(53) Yunsheng Li;
(54) Chen Liang;
(55) Lars Liden;
(56) Ce Liu;
(57) Mengchen Liu;
(58) Weishung Liu;
(59) Eric Lin;
(60) Zeqi Lin;
(61) Chong Luo;
(62) Piyush Madan;
(63) Matt Mazzola;
(64) Arindam Mitra;
(65) Hardik Modi;
(66) Anh Nguyen;
(67) Brandon Norick;
(68) Barun Patra;
(69) Daniel Perez-Becker;
(70) Thomas Portet;
(71) Reid Pryzant;
(72) Heyang Qin;
(73) Marko Radmilac;
(74) Corby Rosset;
(75) Sambudha Roy;
(76) Olatunji Ruwase;
(77) Olli Saarikivi;
(78) Amin Saied;
(79) Adil Salim;
(80) Michael Santacroce;
(81) Shital Shah;
(82) Ning Shang;
(83) Hiteshi Sharma;
(84) Swadheen Shukla;
(85) Xia Song;
(86) Masahiro Tanaka;
(87) Andrea Tupini;
(88) Xin Wang;
(89) Lijuan Wang;
(90) Chunyu Wang;
(91) Yu Wang;
(92) Rachel Ward;
(93) Guanhua Wang;
(94) Philipp Witte;
(95) Haiping Wu;
(96) Michael Wyatt;
(97) Bin Xiao;
(98) Can Xu;
(99) Jiahang Xu;
(100) Weijian Xu;
(101) Sonali Yadav;
(102) Fan Yang;
(103) Jianwei Yang;
(104) Ziyi Yang;
(105) Yifan Yang;
(106) Donghan Yu;
(107) Lu Yuan;
(108) Chengruidong Zhang;
(109) Cyril Zhang;
(110) Jianwen Zhang;
(111) Li Lyna Zhang;
(112) Yi Zhang;
(113) Yue Zhang;
(114) Yunan Zhang;
(115) Xiren Zhou.
This paper is