

Authors:
(1) Han Jiang, HKUST and Equal contribution ([email protected]);
(2) Haosen Sun, HKUST and Equal contribution ([email protected]);
(3) Ruoxuan Li, HKUST and Equal contribution ([email protected]);
(4) Chi-Keung Tang, HKUST ([email protected]);
(5) Yu-Wing Tai, Dartmouth College, ([email protected]).
Table of Links
2. Related Work
2.1. NeRF Editing and 2.2. Inpainting Techniques
2.3. Text-Guided Visual Content Generation
3.1. Training View Pre-processing
4. Experiments and 4.1. Experimental Setups
5. Conclusion and 6. References
3.1. Training View Pre-processing
Text-guided visual content generation is inherently a highly underdetermined problem: for a given text prompt, there are infinitely many object appearances that are feasible matches. In our method, we generate content in NeRF by first performing inpainting on its training images and then backward propagating the modified pixels of the images into NeRF.
If we inpaint each view independently, the inpainted content will not be consistent across multiple views. Some prior 3D generation works, using techniques including score distillation sampling [21], have demonstrated the possibility of multiview convergence based on independently modified training views. Constraining the generation problem by enforcing the training views to be strongly related to each other will simplify convergence to a large extent. Therefore, we first inpaint a small number of seed images associated with a coarse set of cameras that covers sufficiently wide viewing angles. For the other views, the inpainted content are strongly conditioned on these seed images.

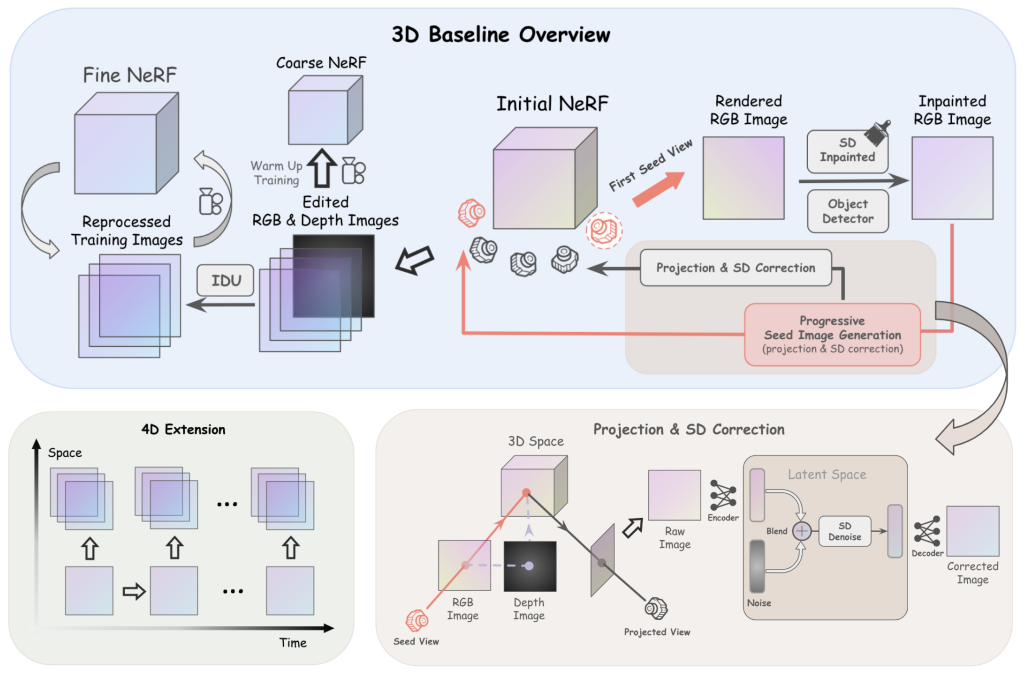

Stable diffusion correction. Since our planar depth estimation is not always accurate, while the raw projected results are plausible in general, the many small artifacts make the relevant images unqualified for training. To make them look more natural, we propose to cover the projection artifacts with stable diffusion hallucinated details. First, we blend the raw projection with random noise in stable diffusion’s latent space for t timesteps, where t is relatively small to the total number of stable diffusion timesteps. Then, starting from the last t steps, we denoise with stable diffusion to generate the hallucinated image. The resulting image is then regarded as the initial training image. With this step, the training image pre-processing stage is completed.
This paper is available on arxiv under CC 4.0 license.