
Introduction
With its encryption superpowers, Fully Homomorphic Encryption (FHE) enables computations to be performed on encrypted data without the need to decrypt it first. Homomorphic computing produces results that, when decrypted, are equivalent to performing the same operations on the plaintext data.
It opens up a new land of opportunities in the data-driven economy, where remote services operating on sensitive user data are replaced by homomorphic applications handling user-encrypted data, end-to-end, with the same quality of service. What FHE promises is nothing short of a revolution in data privacy.
FHE is changing the game, and we're all invited to play.
For FHE to deliver this promise to the tech world, it must come along with a new generation of industrial-strength tools for development, compilation, and runtime execution that anyone can use to build homomorphic apps easily.
At present time though, a lot of experts and companies in the FHE space still invest most of their time and efforts into improving the cryptography behind FHE, instead of focusing on building great dev tools for non-experts. Hear me well here: enhancing core FHE functionalities and performance is always going to be good news.
But in the great scheme of things, these incremental improvements promote global adoption marginally at best. They will have an impact on adoption at some point, but not in the present.
From where I stand, it is obvious that the world needs powerful, developer-friendly FHE toolchains today, so as to start unlocking FHE-powered success stories and move FHE from a tech trend to an actual paradigm shift in the digital security business. I believe that the current state of knowledge about FHE - both scientifically and technologically - is already sufficient to build such tools in the present and make them available to the tech-savvy masses without further delay.
The continuous integration of new features will unfold naturally over time; it always does.
But here is the thing: FHE comes in many flavors. Depending on which cryptographic scheme you're using - or which particular use you make of it, a different way of representing computation and running homomorphic programs arises. Imagine FHE schemes as different animals altogether, one giving you Turing machines and another lambda calculus: biodiversity is always good in tech or otherwise, but it also means that you need to nail down a viable strategy when instrumenting FHE in practice.
For example, my company focuses on one particular FHE scheme which is TFHE. TFHE achieves homomorphic data processing with very specific assets: super-fast bootstrapping and computations expressed as networks of table lookups. We have come to acquire a deep understanding of how these peculiarities - which used to make TFHE some kind of an underdog in the FHE space - can be translated into homomorphic libraries, compilations, virtual machines, or hardware acceleration.
Other prominent FHE contenders like CKKS, BGV, or BFV involve very different concepts in their practical instrumentation: bootstrapping is too slow to be an option, so processing is limited in depth, however, data can be vectorized with massive batching, computations expressed as polynomial circuits and - in the case of CKKS - results are approximate. So the translation of BGV/BFV and CKKS into compilers and runtimes requires a totally different mindset from tool builders.
Developers, though, are unlikely to care much about which particular scheme is powering their FHE toolchain and runtime environments, as long as they are easily operated and performance requirements are met in deployed homomorphic applications. They are creative builders themselves, and their focus should be on the new experiences they can offer to their users.
So the endgame for FHE technology enablers is to conceive and deliver tools that are not only ready for their prime time in the dev multiverse but strong enough to set a new industry standard. To achieve that, they have to take a chance on which FHE scheme is more likely to get them there.
Now, let's play a game.
Take a developer who knows nothing of the intricacies of FHE but wants to build a homomorphic application. You are the tool builder here, you are facing that developer, from whom you can expect some familiarity with common dev practices and the basics of computer science but everything else - advanced math and the like, is off-limits. How can you successfully make them produce the FHE app on their own?
This article explores various strategies to win that game by betting on TFHE.
Depending on the nature of the application - custom data crunching, neural networks, smart contracts, or general-purpose programming, TFHE-enabled winning paths will be explored. This exploration will take us on an easy road, a tough road, and a few others in between, with different levels of technological readiness in their practical realization.
What Are TFHE Programs?
TFHE stands for Torus FHE. Also referred to as CGGI after its discoverers' names, TFHE occupies a unique position within the FHE landscape: it is the best-known mechanism to enable programmable bootstrapping (PBS).
In a nutshell, a PBS is a homomorphic table lookup. It returns an encryption of T[x] where T is a tabulated function of your choosing, given an encryption of an index x. Its running speed does not depend on the entries of T but only on the number of entries, and is in the range of milliseconds. Plus, a PBS resets the encryption noise embedded in its output ciphertext, so you can compose PBSs in sequence indefinitely, knowing that your homomorphic application will always handle clean ciphertexts.
TFHE Networks
The computational model that TFHE advocates for is quintessential.
The elementary processing unit in TFHE programs looks exactly like a neuron and composes 2 basic homomorphic operations:
-
A linear combination of inputs that returns
E(x)wherex = w_1 x_1 + … + w_n x_n modulo m, given the encrypted inputsE(x_1), …, E(x_n)and a set of plaintext weightsw_1, …, w_n. -
A PBS that computes
E(T[x])fromE(x)whereTis some plaintext table of sizem.
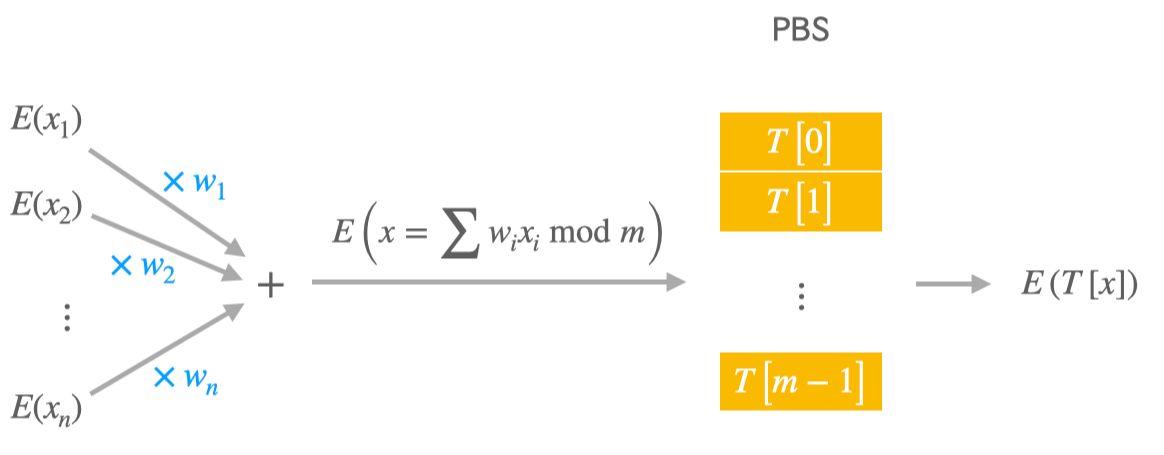
In the "TFHE neuron", m, x_i, w_i, as well as the entries T[0], …, T[m-1] are all integers, and one can freely choose the "parameters" m, w_1, …, w_n and T. Given that the linear combination has nearly zero cost, the efficiency bottleneck is the PBS whose running time solely depends on the modulus m: speed decreases as m increases.
This invites us to use small values - odd or even, but at least 2 - for moduli in TFHE neurons, although a trade-off must be found to avoid a too drastic reduction of their computational expressiveness.
Now, the same way neurons are assembled into layers in neural networks to benefit from parallelism and HPC tricks, TFHE networks pile up layers of TFHE neurons. Each layer features a weight matrix modulo a common modulus m and a vector of lookup tables of size m. However, the modulus is free to differ in the previous or the next layer, just like the layer’s shape.
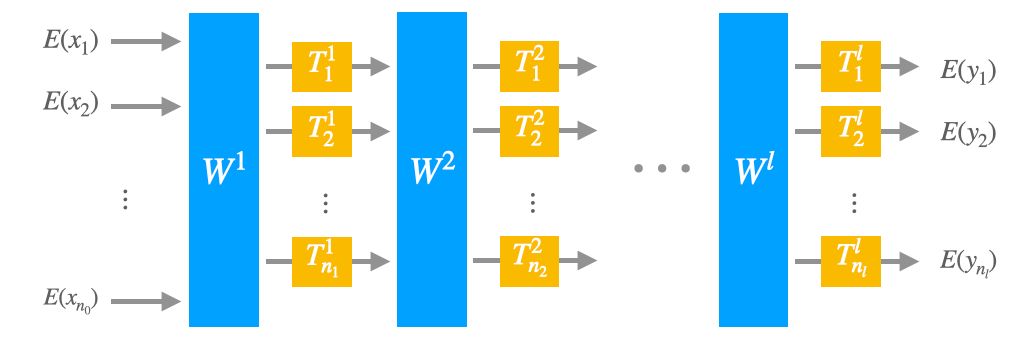
And that wraps up TFHE! There you go; we just need to systematically express functions as lookup networks. We now have our homomorphic computational model.
In actual reality, TFHE supports multiple extensions of that model (arbitrary graphs of operators of the lower level, ciphertexts of various types, multi-output table lookups, multiple ways of packing variables, etc.). But we can ignore these enhancements for now because the lookup network vision is already powerful enough to allow us to convert a plain program into a homomorphic equivalent and run it. So we can focus on how to do just that, at least for the first iteration of the tech.
Making TFHE Networks Executable
As such, a TFHE network is only a blueprint and is not ready yet for proper execution within a homomorphic app. Even though moduli, weight matrices, and lookup tables are fully specified for all of its layers, it still misses a crucial ingredient which is cryptographic parametrization.
Crypto parameters dictate every possible metric about what will happen within the network at runtime: concrete ciphertext sizes, the actual tensor dimensions of key-switching and bootstrapping keys internal to PBSs, various algorithmic options within low-level homomorphic operators, how plaintext precisions and noise levels evolve across the network and ultimately, the specifics of how to encrypt and decrypt. They also predict memory use and performance.
Finding out which set of parameters optimizes the execution of a TFHE network can be cumbersome, and in any case, excruciatingly hard - even for experts - to do pen-and-paper style like in the early days of FHE, as everything depends on everything. Also, several optimal sets may coexist simultaneously, thus requiring an arbitrage between the public key size, critical-path latency, or maximal throughput.
Fortunately, the problem of automating this task has been cracked over the last years and powerful optimization tools now exist to quickly determine the best cryptographic instantiation of a given TFHE network.
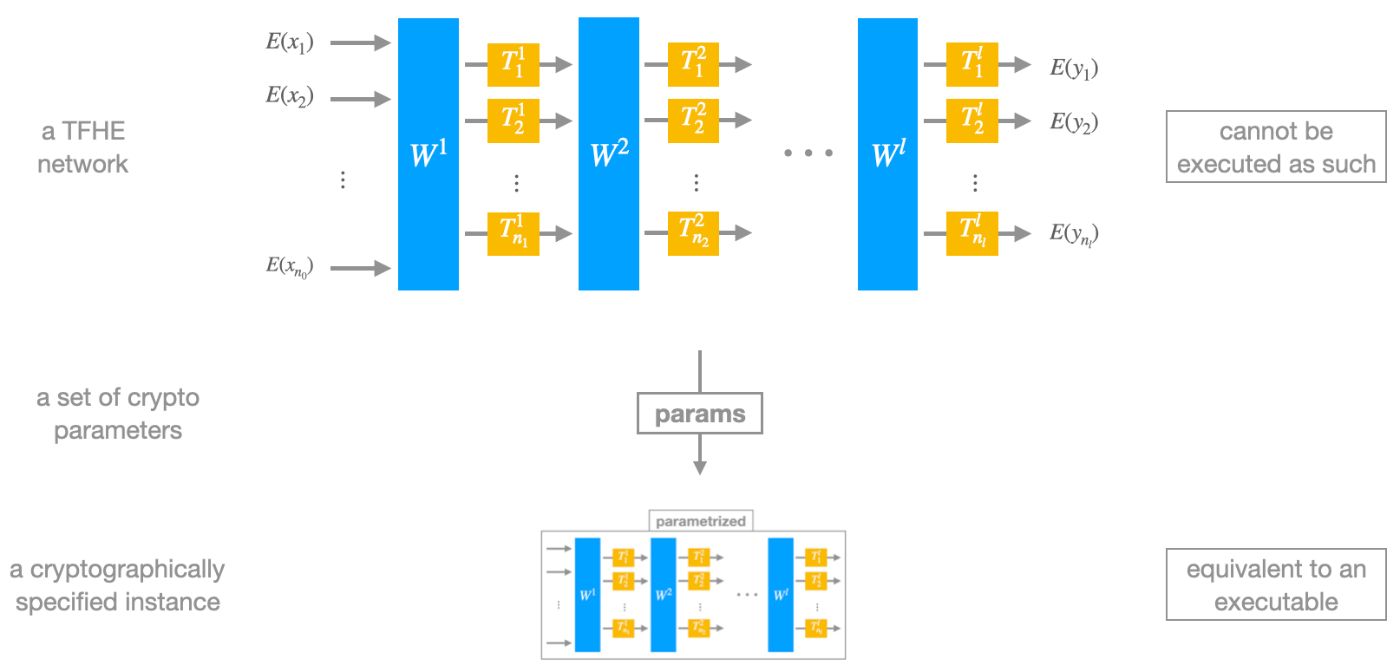
Once instantiated with cryptographic parameters, a TFHE network becomes truly executable, or more exactly, is amenable to a true executable through an appropriate pass of compilation.
TFHE Programs
A TFHE program is a collection of parametrized TFHE networks glued together by "plain logic".
Plain logic is made of
- instructions operating over plaintext variables (meaning normal, non-encrypted variables),
- branching, either unconditional or conditioned to plaintext predicates,
- memory reading and writing at plaintext addresses, pointer arithmetic,
- calls to subroutines/functions.
Basically, plain logic contains whatever programming logic is supported by the language, at the exclusion of one single case: modifying encrypted program variables, which is the prerogative of the TFHE parts of the program. The only thing plain logic is allowed to do with ciphertexts - and TFHE public keys alike - is to move them around without change and feed them to the TFHE parts, as if those were running inside their own separate coprocessor or container.
For all intents and purposes, a program complying with this definition is complete and ready to become a full-fledged homomorphic application, whatever the programming language. Custom compilation will provide this final mapping, and the resulting object can then be run on top of a TFHE-enabled runtime or as a stand-alone, self-contained executable.
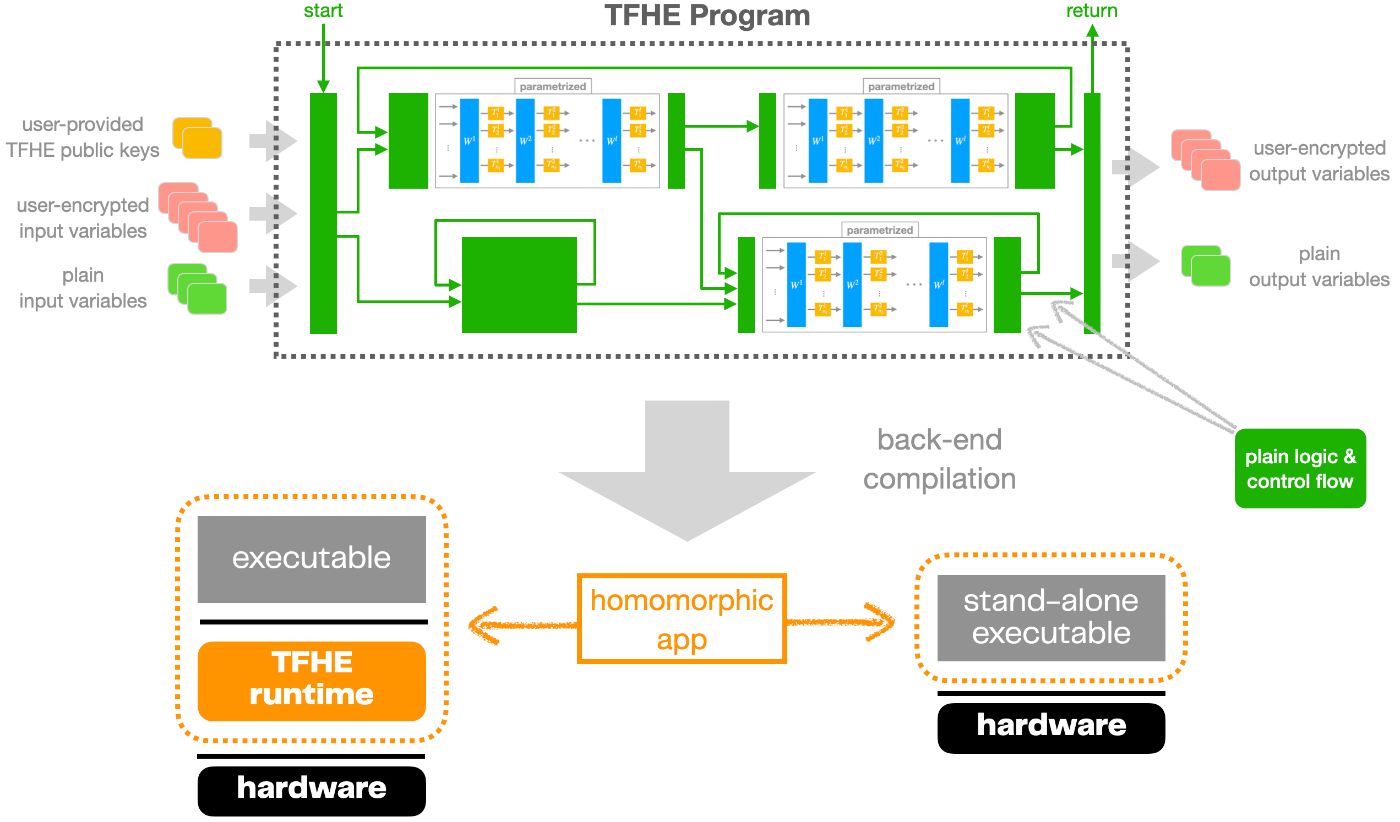
A dedicated language can be used to unify the representation of TFHE programs - like some DSL, or better, an MLIR dialect - so that the compilation can be performed with the same back-end compiler.
The precise nature of the runtime (shared/dynamic library, VM or otherwise) is just a modality here. Either option will lead to an operational TFHE-powered homomorphic app that can be deployed and exposed to users.
Now, let's get back to the game at play for a minute.
We are facing a developer who knows nothing of TFHE or the above but wants to build a homomorphic application. Assume we have released the compiler discussed above and the TFHE-enabled runtime, if any.
Our goal is settled; we just need a TFHE program to arrive at an executable. But... how are we going to make the developer self-produce something as specific as a TFHE program in the first place?
The Easy Road: Release an FHE lib, and Let the Dev Do Their Thing
Here comes the easy winning path: you encapsulate all the complexity into a black-box FHE API.
Plain Programs
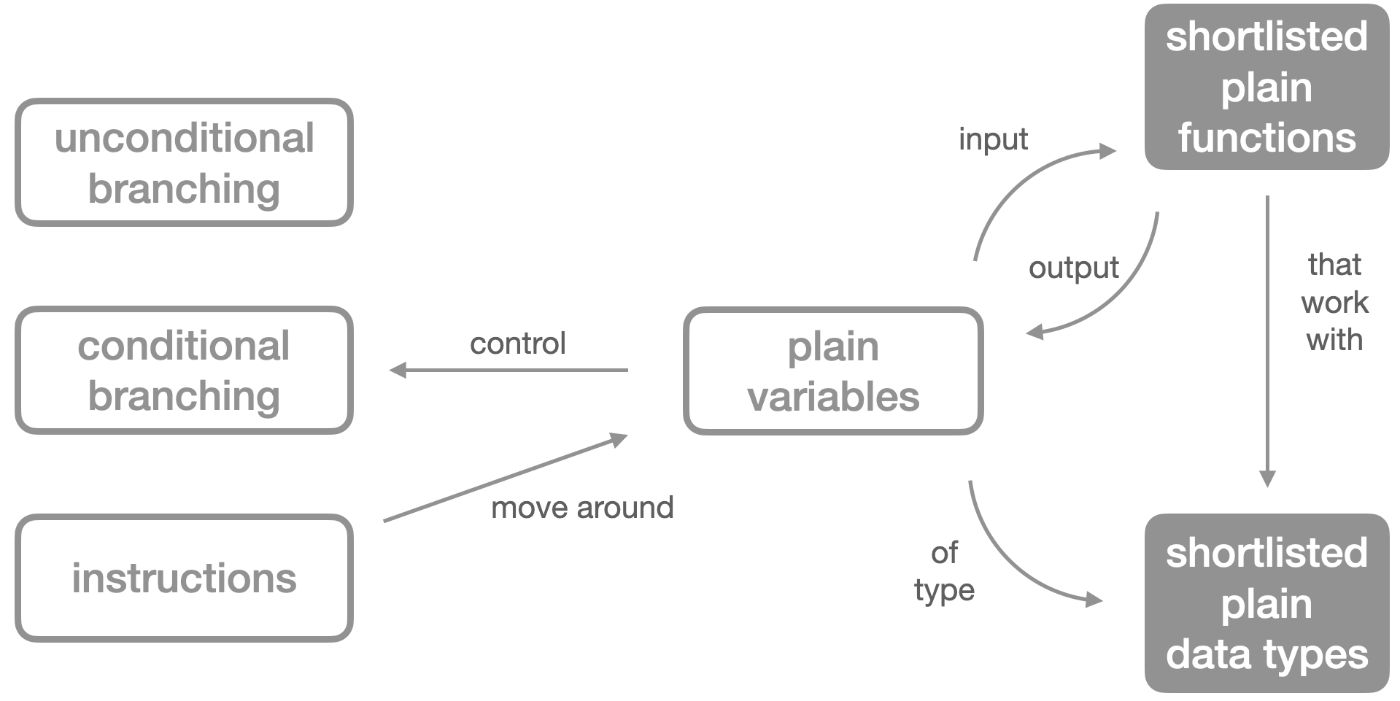
In any programming language, a (plain) program can be viewed as essentially a combination of 3 ingredients:
- the programmatic logic, made of language-native instructions and scoping constructs,
- variables and a selection of data types that the program assigns to them, chosen among all possible data types,
- calls to a selection of external functions, selected among all available external functions, that the program uses to operate on its variables.
Data types have their own sub-language, a mixture of native types and typing constructs to extend these native types and combine them into higher-level structured types. The type system is meant to provide enough expressiveness to cover virtually any data structure the program may require.
External functions are the ones provided by libraries, standard or otherwise, but they may also be invoked implicitly by language-native instructions (think operators for modular arithmetic or division).
So, plain programs are in fact "simple":
Hear me well here. I'm not saying that all high-level programming concepts such as polymorphism, objects with their members and attributes, classes and hierarchical inheritance, templates, macros, traits, threads, recursion, syntactic sugar, annotations, and all the other imaginable zero-cost abstractions provided by the language are necessary simple for the developer to handle, although they've been invented to simplify their work.
I'm just saying that for our purpose, they're just innocuous decorations that vanish at compile time because a lowered yet equivalent, normal-form version of the program is inferred from the source. That version of the program, expressed in whatever intermediate representation (IR), is made of straight-line basic blocks - sequences of instructions that are elementary in that IR - connected by some control flow graph.
Now, it is this program in normal form that is "simple." I mean, simple enough to be augmented with homomorphic capabilities.
Throw FHE in the Picture
You win the game by releasing a language-native FHE library and letting the developer deal with how to best use it.
The library will expose new data types - encrypted ones, to complement the plain ones - and a collection of homomorphic functions that mimic (more or less) the plain functions the developer is familiar with, only they work with encrypted data types. In short, you are extending the type system and the library ecosystem and letting the developer's intelligence figure out how to use these extensions to craft their homomorphic app.
This is not particularly tied to TFHE, any FHE scheme will do. That's what the providers of the various FHE libraries out there focus on: improving the usability and user-friendliness of FHE by exposing high-level homomorphic functions that look and feel as close as possible to the plain coding experience. All the cryptographic complexity is abstracted away into black boxes that the program will make Oracle calls to.
That may work well for the developer of course. Well... if you pull off your side of the bargain as the library provider that is.
They will figure out a homomorphic program that now looks something like this.
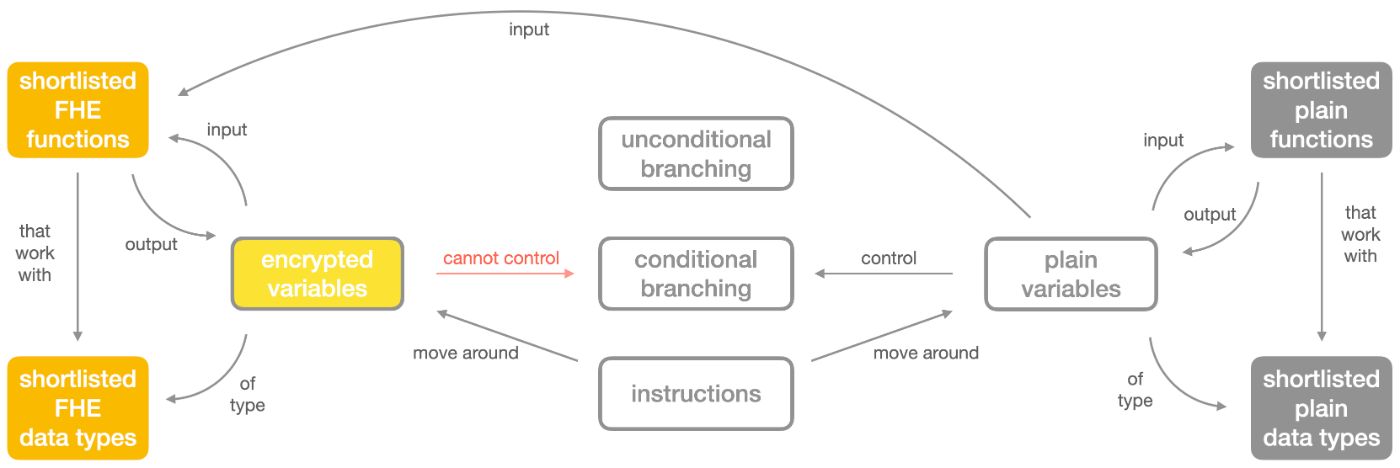
There are now coexisting plain and encrypted variables and the program has to maintain a strict divide between these 2 object types. That is because there is this FHE golden rule that tells that when you apply a function to a mixture of plain and encrypted arguments, the result is necessarily encrypted, e.g., fhe_add(E(x), y) returns E(x+y) and so on. So plain variables can enter some FHE functions but can never come out of them. Homomorphic encryption "contaminates" everything it touches through computation.
So, see... how do you branch conditionally to an encrypted variable then?
Well, you can't. But it's not a big issue at all.
The One Hiccup: Conditional Branching
In an FHE application, conditional branching can only act on plain booleans, not on encrypted ones. How would you know where to jump based on an encrypted bit? You don't have the user's private key to decrypt that bit.
Fortunately, FHE also gives you simple tricks to remedy this.
How to Regularize an if
Suppose the developer initially wanted to do something like:
if (x == 0) then y = 3 else z = 7
but realizes that, by that point, the variable x will actually be encrypted. How do you adapt that piece of code?
The first thing to do is to rework the plain if statement to get an equivalent piece of straight-line code that uses multiplexing:
bit = (x == 0) // bit = 1 if x == 0 otherwise 0
y = 3 * bit + y * (1 - bit) // y = 3 if bit == 1 otherwise no change
z = z * bit + 7 * (1 - bit) // z = 7 if bit == 0 otherwise no change
In a second pass, the dev has to propagate the fact that x is of encrypted type across the subsequent lines:
bit = fhe_is_equal(x, 0) // bit, y_new and z_new are encrypted
y_new = fhe_add(fhe_mul(3, bit), fhe_mul(y, fhe_sub(1, bit)))
z_new = fhe_add(fhe_mul(z, bit), fhe_mul(7, fhe_sub(1, bit)))
One can check that this is functionally equivalent to the dev's initial intent, and that's it.
If the programming language allows native operators to be overloaded, the FHE API can even make the explicit FHE functions of the second snippet superfluous, so that the first rewriting is the only thing the dev needs to do.
To give an extra dose of syntactic sugar to the dev, you can even expose an overloaded ternary operator a? b : c wherein any argument can be encrypted or not. The piece of code becomes even simpler:
bit = (x == 0) // bit = 1 if x == 0 otherwise 0
y_new = bit? 3: y // y = 3 if bit == 1 otherwise no change
z_new = bit? z: 7 // z = 7 if bit == 0 otherwise no change
This easily generalizes to arbitrary if/switch statements: every time there is an encrypted condition to check, the dev just has to use multiplexing to fuse the multiple bodies of the statement into one single block of equivalent straight-line code.
How to Regularize a For/While Loop
Now, loop constructs involving encrypted conditions can be regularized in the same spirit.
Take for instance
for (i = 0; i < x; i++) do <body> // i is plain, x is encrypted
where x is to be of encrypted type.
First, decompose that into a plain for statement and an irregular if statement:
for (i = 0; i < known_max_value_of_x; i++) do
if (i < x) then <body> // i is plain, x is encrypted
and then regularize the if statement as before:
for (i = 0; i < known_max_value_of_x; i++) do
bit = (i < x) // i is plain, x and bit are encrypted
<new_body> // new body regularized using bit? _ : _
Observe that this requires an immediate value known_max_value_of_x. The max value supported by the encrypted type of x can be used by default, but in many cases, the dev knows a much better upper bound on x which allows to reduce the total loop count to a strict minimum.
At the end of the day, the above transformations are easily generalized into a systematic method to regularize irregular control flow, which is easy for coders to assimilate and add to their coding habits.
Example: Confidential Smart Contracts on the EVM
Zama's fhEVM is a full-fledged open-source framework for the development and deployment of confidential smart contracts on the Ethereum Virtual Machine (EVM). fhEVM contracts are simple Solidity contracts that are built using traditional Solidity toolchains. The familiar dev experience is FHE-augmented by the library TFHE.sol which provides encrypted data types and FHE replacements for standard functions.
The supported encrypted data types are currently
ebool, euint4, euint8, euint16, euint32, euint64, eaddress
and encrypted signed integers are soon to be included as well. Encrypted variables are created from raw input ciphertexts using dedicated constructors:
function mint(bytes calldata encryptedAmount) public onlyContractOwner {
euint64 amount = TFHE.asEuint64(encryptedAmount);
balances[contractOwner] = balances[contractOwner] + amount;
totalSupply = totalSupply + amount;
}
Solidity's native operators +, -, *, &, |, ^, etc are overloaded for the dev's convenience, and the provided comparison operators eq, ne, gt, lt, ge, le return an encrypted boolean ebool.
The homomorphic ternary operator _? _ : _ is called select:
function bid(bytes calldata encryptedBid) internal {
euint32 bid = TFHE.asEuint32(encryptedBid);
ebool isAbove = TFHE.le(bid, highestBid);
// Replace highest bid
highestBid = TFHE.select(isAbove, bid, highestBid);
}
On the runtime side, fhEVM provides a TFHE-enabled EVM where homomorphic functions are exposed as precompiled contracts, which results from the integration of the open-source TFHE-rs Rust library. See the fhEVM white paper for more on this.
What Does It Take to Build an FHE API With TFHE?
Remember how executable TFHE programs look like, parametrized TFHE networks assembled by plain logic? Well, you just need a way to map the dev's software logic to that.
The first requirement is to make sure that the program logic is "plain." That's exactly what we taught the developer to produce by themselves by regularizing their control flow statements. So, we're actually good on that now.
The second requirement is that all the homomorphic functions called by the program must be mapped to pre-established parametrized TFHE networks. This is more intricate than it looks for several reasons.
1. You Need to Create TFHE Networks for Your API Functions
Pre-establishing a parametrized TFHE network that implements a given function is not necessarily trivial. Just building a homomorphic addition of 2 encrypted 64-bit unsigned integers leads you to many technical options: how do you represent the 64-bit inputs as vectors of modular integers? With what modulus (or multiple moduli) exactly? And then how do you realize a 64-bit addition circuit with layers of table lookups?
Many choices there. But you will eventually make up your mind through good engineering and by conducting plenty of experiments.
2. You Need to Normalize Encrypted Data Types
Assuming you implemented TFHE networks for all the functions of the API, you want to make sure that they can be composed at will like Lego blocks.
This is not necessarily guaranteed because the best way to represent the same encrypted data type may differ from one function to another. So you need to adopt a common arithmetic format to represent each encrypted data type, without incurring too much degradation on the efficiency of your TFHE networks.
Again, many options there, and you will need to arbitrage between them.
3. You Need to Ensure Actual Composability
Assuming all TFHE networks are now fully compatible in their input/output formats, composability may not be ensured still.
This is because the cryptographic parameters that instantiate one TFHE network may not be compatible with the ones used to instantiate another. Most particularly, the level of encryption noise within input and output ciphertexts must be adjusted to ascertain actual composability.
That's similar to impedance in electronic circuits; there's no way you can connect one circuit to another if there's a mismatch in impedance. You need to align their impedance levels first, and it's the same thing here. The easiest way to do that is to use fixed sets of parameters - even maybe just one unique set - that are tuned to ensure alignment across all the API functions. Subsequently, the format of user public keys will be fixed, as well as the parameters used in user encryption and decryption, whatever the developer codes.
If you find a way to satisfy these 3 requirements when crafting your TFHE networks and parametrizing them, and still achieve good overall performance, then congratulations! You pulled it off.
So Why Wouldn't FHE Libs Be Good Enough?
They are good enough for general-purpose programming, assuming again that the FHE API is comprehensive enough to provide homomorphic replacements for all the standard functions the developer expects, with full composability.
But they may not be good enough for programs that specialize in
- large, compute-intensive functions as in machine learning,
- custom, non-standard functions.
That's when homomorphic compilation comes in.
The Tough Road: Release a Homomorphic Compiler
The tough road starts here: to win the game outside of general-purpose programming, you will now deliver a TFHE compiler.
The compiler will take care of what the developer has no idea how to do by themselves. It will be fed by the developer's input - whatever that may be, your call - and will have to complete the missing parts to arrive at a TFHE program.
Let's look at typical examples of non-standard applications.
Confidential Inference With Deep Neural Networks
By turning a plain neural network into a homomorphic equivalent, the developer will build and deploy a homomorphic inference service wherein user inputs and outputs are end-to-end encrypted.
What the Dev Provides as Input
The developer is supposed to know their way around machine learning well enough to produce a trained quantized model or to already possess one.
The specifics of how quantization is done truly matter here, as your compiler will require the model to basically be a TFHE network - or to be easily amenable to one through a simple rewriting. Available open-source techniques are known to support that form of quantization, either by post-quantizing a pre-trained model, or preferably by performing Quantization-Aware Training (QAT), which achieves state-of-the-art levels of accuracy compared to non-quantized models trained on the same dataset.
Essentially, the moduli used across the TFHE network layers are variable powers of 2, so that the precision of activation signals is measured in bits. Weights are signed integers, and activation functions are themselves quantized and instantiated as table lookups. When activations tabulate a shifted hard sign function with a learned offset, this definition encompasses model types like BNNs, TNNs, and their multi-bit generalizations.
But in principle, one is free to use arbitrary lookup tables in activation functions, and therefore those could even be learned during training to reach better accuracies.
What the developer does not know how to do though, is to convert their TFHE network into a homomorphic executable. So, the only missing ingredient here is just a cryptographic parametrization of that network, and this is all your compiler will have to do before proceeding to the back-end compilation stage.
What Does It Take to Parametrize a TFHE Network?
Remember that the parametrization of a TFHE network provides a cryptographic instantiation that can be executed. It also controls all the metrics pertaining to that execution, like the total size of user public keys and the total running time. Therefore, parametrization is of critical importance here, as the developer is seeking to reduce the latency of inference to an absolute minimum.
There are far too many degrees of freedom in the cryptographic parameters of a TFHE network to brute-force them all. Also, the metrics to optimize depend on 2 components that are totally external to the network and depend on the algorithms that the runtime makes use of to perform low-level TFHE operations:
- A collection of noise formulas. A noise formula relates the input and output distributions of encryption noise at the endpoints of an operator, using the operator's parameters as unknown variables. Establishing them requires human scientific analysis and experimental validation.
- A collection of cost metrics. Cost metrics predict the multi-dimensional efficiency (memory use, running time, etc.) of an operator as a function of its parameters. They are typically inferred from benchmark measurements through a best-fit analysis.
Any change in the runtime's implementation must be reflected in these 2 modules, as they are both strongly algorithm-dependent and hardware-dependent.
The runtime's noise formulas and cost model, together with the given TFHE network, formulate a specific instance of a whole class of optimization problems, and this instance is handed over to a dedicated optimizer. We're talking mixed integer nonlinear programming with multiple objectives here, so finding out a Pareto front of optimal sets of parameters requires solving that non-trivial class of optimization problems.
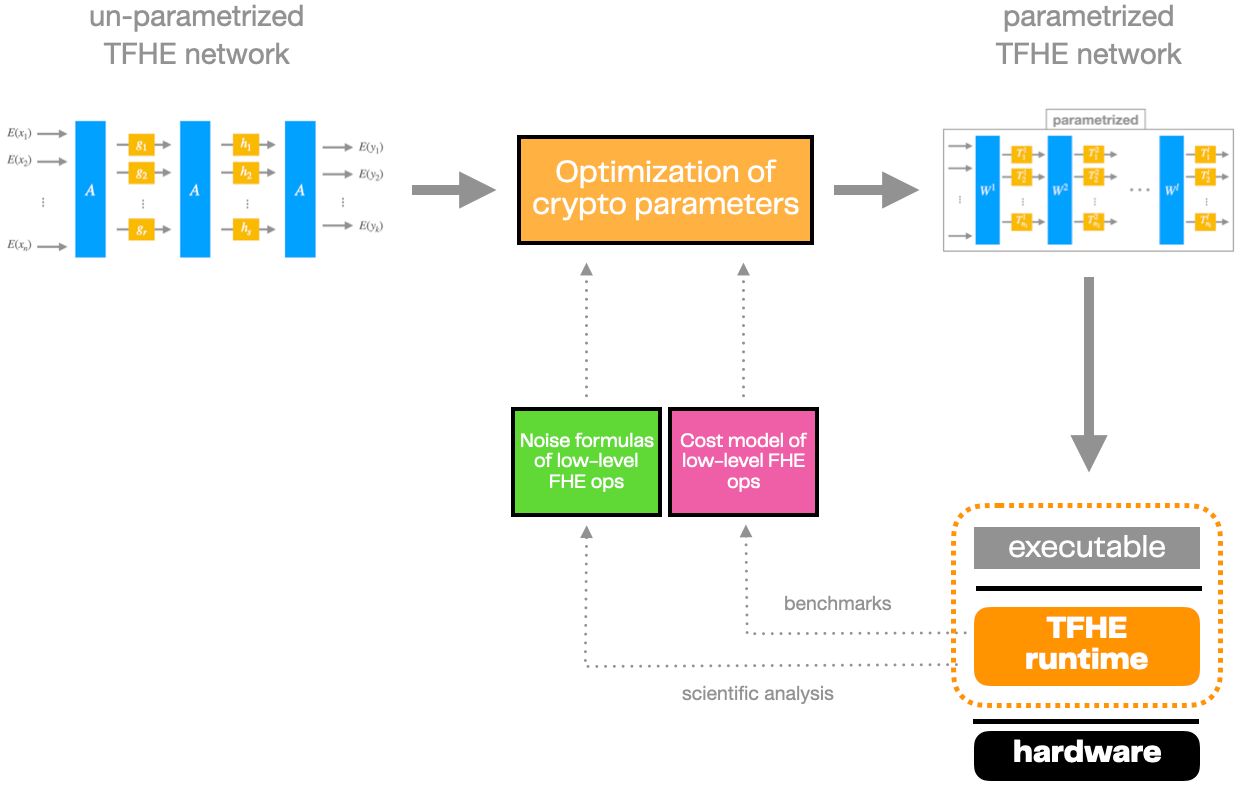
Technological Readiness
Good science and engineering have led to the resolution of this type of optimization problem in a matter of seconds, and TFHE compilers such as Concrete already feature an efficient TFHE parameter optimizer as an internal module.
Various improvements can make TFHE optimizers even speedier in the future, but even without those, one may consider the parametrization of TFHE networks as - pretty much - a done deal.
High-Speed Custom Data Crunching
What the Dev Provides as Input
These applications are of a different kind entirely. The developer holds the mathematical specification of a custom function to implement, together with a precision constraint. Take for instance
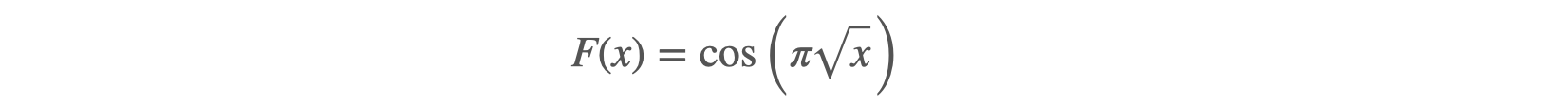 where
where x is a real number between 0 and 1, and using an approximation G of F is acceptable as long as
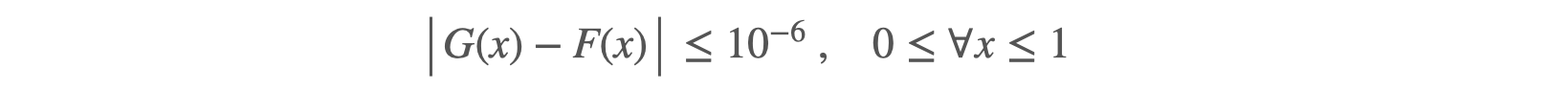 The developer knows that implementing
The developer knows that implementing G on the back of an envelope by composing standard API functions is likely going to be way too suboptimal.
What your compiler will do is to manufacture - on the fly - a fresh TFHE network specifically designed to satisfy the specification of G. It will then parametrize it and proceed with back-end compilation to produce the homomorphic app.
What Does It Take to Synthesize a TFHE Network?
Well, that's where the road suddenly becomes much bumpier.
At present time, there is a lack of scientific knowledge about how TFHE networks, with the exact definition I've stated earlier, can be synthesized automatically. Even research on the synthesis of adjacent types of circuits that also rely on integer-valued modular arithmetic is scarce at best. Not to mention any preexisting synthesizer capable of carrying out this task from A to Z.
Taking Advantage of Boolean Synthesis
One way to solve the issue is to exploit a fraction of the computational power of TFHE networks by lowering them to boolean circuits. For instance, a TFHE neuron can be forced to act as the ternary boolean gate
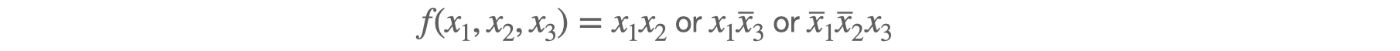 by
by
- setting its number of inputs to 3 and imposing
x_1, x_2, x_3to be 0/1 values, - setting its modulus to
m = 4and its weights to(w_1, w_2, w_3) = (2, -1, 1), - setting its lookup table to
[0, 1, 1, 0].
Brute-forcing all the possible weights and tables with the same modulus, one can then constitute a dictionary of TFHE neurons that can serve to compute ternary gates. The next step consists in
- using a boolean synthesis tool to generate a boolean circuit from the developer's specification (many open-source tools are available to do this),
- cutting (a.k.a. 3-way LUT partitioning) the circuit into ternary gates belonging to the dictionary,
- substituting these ternary gates with equivalent neurons,
- reshaping the circuit into a layered network of minimal depth.
This is just one illustrative strategy among many because methods that rely on boolean circuits are plentiful. You may also just consider the usual binary gates and implement them with constrained TFHE neurons. CEA's Cingulata and - later on - Google's FHE transpiler have precisely pioneered that road with TFHE.
Technological Readiness
Boolean synthesis makes use of aggressive circuit optimization techniques and is overall a solved technical issue - or pretty much so, making that approach sound and practical for the one who builds the compiler.
However, once a TFHE network is generated that way, its width and depth may end up being abnormally high, leading to poor overall performance. So, there is a widespread suspicion that by relaxing the - totally artificial - boolean conditioning of TFHE neurons, one can leverage their full expressiveness and get much smaller, much shallower networks.
But again, more research is needed to identify clearly how to do that. It is possible that entirely different approaches, like learning the TFHE network with some appropriate training method borrowed from machine learning, will end up providing superior results. Time will tell.
The Quest for An All-Inclusive TFHE Compiler
Assuming that our synthesis problem is solved and yields efficient custom TFHE networks, you would find yourself ready to put all the moving pieces together and design a compiler that does the whole shebang:
-
It would take as input a plain program, where sensitive variables are simply annotated as being encrypted.
-
It would accept pre-trained neural networks or other machine learning models and reinterpret them as TFHE networks.
-
It would accept function mock-ups just made of a mathematical specification and would perform on-the-fly synthesis to generate custom TFHE networks.
-
It would turn all non-parametrized TFHE networks left hanging in the compilation unit into executable instances using an optimizer module whenever required.
-
It would perform the back-end stage of the compilation for a variety of target TFHE runtimes and/or hardware architectures.
-
It would systematically take advantage of specific hardware accelerators (through their cost model) to enable the synthesis and parametrization of hardware-specific, faster TFHE networks.
Hell, you might as well throw in there some support for an automated regularization of control flow, so that the developer does not even have to care about it anymore.
That would offer FHE app builders the ultimate development experience.
Summary
In the context of general-purpose FHE programming, a TFHE library can provide modularity and a fully autonomous development experience with preexisting toolchains.
TFHE pioneers specific compilation techniques that can satisfy the developer's needs beyond that point, most particularly for encrypted machine learning inference and, in the upcoming years, for high-speed encrypted data crunching and other custom FHE applications.
Overall, TFHE provides a clear technology path to create more integrated and adaptive FHE toolchains that can make it big in the software development world, and birth a new wave of privacy-first solutions anyone can build and run with unprecedented ease.
By focusing solely on TFHE lookup networks, I have just used one computational model among several that TFHE can support. As research progressively uncovers more of its capabilities, there is no doubt that new ways of instrumenting TFHE will reach the surface.
Which ones and when is another story. But behind that story lurk a whole host of other exciting and potentially enlightening questions regarding the future of confidential computing.

Still need more information or crave a further dive? Check out FHE.org for comprehensive resources on FHE.