

Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng;
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
Table of Links
Teaching Orca 2 to be a Cautious Reasoner
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Outpu
6 Evaluation Results
6.1 Reasoning
Reasoning capabilities are pivotal in ascertaining the efficacy of LLMs. Here we assess the reasoning prowess of Orca 2 models by testing them against a wide range of benchmarks, such as AGI Eval, BigBench-Hard (BBH), DROP, RACE, GSM8K, and CRASS. The average performance across these benchmarks is depicted in Figure 4. When comparing Orca 2, we observe the following phenomenon:
• Surpassing models of the same size - Orca-2-13B significantly outperforms models of the same size on zero-shot reasoning tasks. Orca-2-13B provides a relative improvement of 47.54% over LLaMA-2-Chat-13B and 28.15% over WizardLM-13B. Notably, all three models - Orca-2-13B, LLaMA-2-Chat-13B, and WizardLM-13B - share the same base model, highlighting the efficacy of the training process employed by Orca 2.
• Competitive with models 5-10x larger - Furthermore, Orca-2-13B exceeds the performance of LLaMA-2-Chat-70B and performs comparably to WizardLM-70B and ChatGPT. Orca-2-7B is better or comparable to LLaMA-2-Chat-70B on all reasoning tasks.
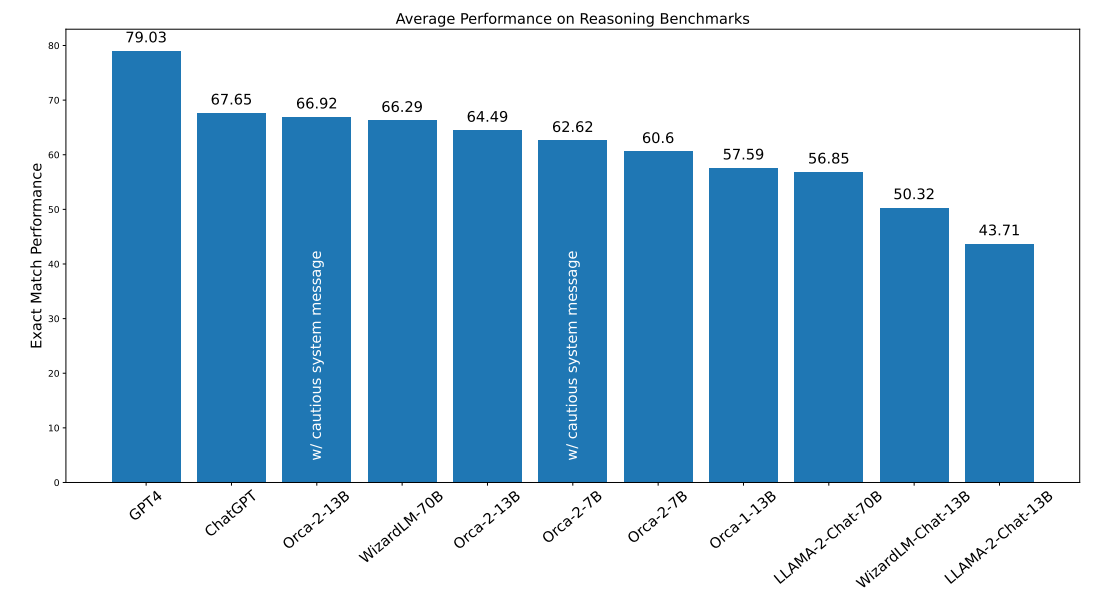
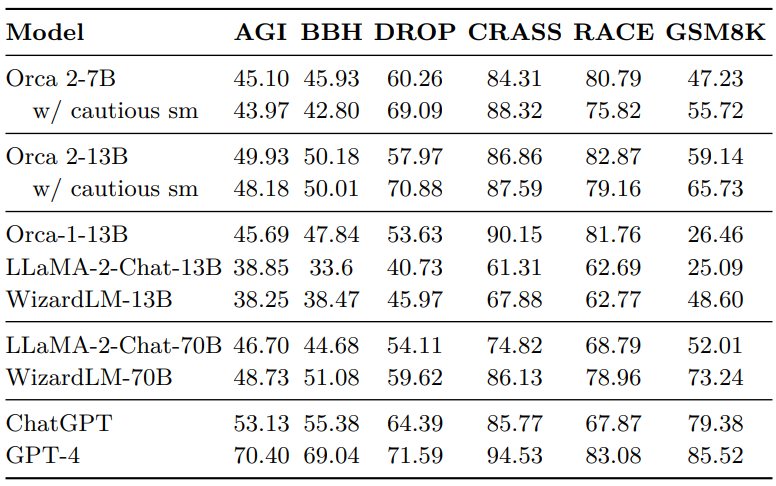
• Cautious system message adds a small boost - Using the cautious system message with both the 7B and 13B models provides small gains over the empty system message.
Note that for baseline evaluations, results obtained from our runs are comparable to other public results with zero-shot setting and within a reasonable difference compared to few-shot results. Our numbers are sometimes better than publicly reported (e.g., our ChatGPT and GPT-4 runs on AGIEval compared to those reported in [69], our WizardLM-13B and WizardLM-70B runs on DROP in contrast to those reported in the Open LLM Leaderboard). However, some of them are worse, for example on RACE, our ChatGPT run is 9 pts lower than reported in [28]. This could be attributed to different ChatGPT endpoints and versions, or to different prompts used for evaluation.
Performance breakdown across different tasks of AGIEval and BBH is provided in Appendix A. Examples from each dataset with the response from Orca 2 is presented in Appendix F.
6.2 Knowledge and Language Understanding
MMLU, ARC-Easy and ARC-Challenge assess the language understanding, knowledge and reasoning of LLMS. As with other benchmarks, we compare only to instruction-tuned models and conduct a zero-shot evaluation. Table 2 displays the results for knowledge and language comprehension benchmarks. Overall, we observe similar trends as with the reasoning tasks:
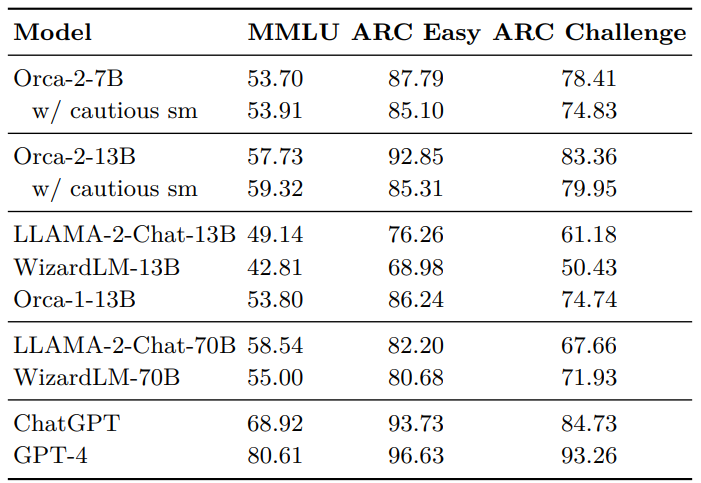
• Surpassing models of the same size - Orca-2-13B surpasses LLaMA-2-Chat-13B and WizardLM-13B (both using the same base model as Orca-2) in performance on each individual benchmarks. On average, Orca-2-13B achieves a relative improvement of 25.38% over LLaMA2-Chat-13B and 44.22% over WizardLM-13B.
• Competitive with models 5-10x larger - Orca-2-13B also outperforms both 70B baseline models. In the MMLU benchmark, Orca-2-13B (57.73%) achieves a score similar to LLaMA2-Chat-70B (58.54%) and WizardLM-70 (55.00%), both of which are approximately 5 times larger than Orca-2-13B. Additionally, Orca-2-7B surpasses both 70B baselines on the ARC test set.
We further note our baseline runs for this set of evaluations align with publicly reported results under zero-shot settings, considering the differences in prompts and possible variations in API endpoints for GPT models. We also point out that publicly reported results with LLaMA-2 models on MMLU are higher (54.8 and 68.9 for 13B and 70B variants, respectively [58]). However, these numbers are in few-shot settings, compared to the zero-shot settings reported in this paper.
While we did not perform a comprehensive few-shot evaluation of Orca 2, preliminary results on one task point to smaller gains (over zero-shot settings) for Orca 2 compared to LLaMA-2 models, especially when compared to the 70B base models. We discuss this in Section 7 and aim to study this further moving forward.
6.3 Text Completion
In addition to benchmarks measuring advanced reasoning capabilities, we also use HellaSwag and LAMBADA to measure text completion abilities. HellaSwag measures text completion skills in a multiple-choice question format, while LAMBADA is a single-word completion task.
Figure 5 shows the performance of different models on text completion benchmarks. Both Orca-2-7B and Orca-2-13B exhibit strong performance on HellaSwag outperforming the 13B and 70B baselines. Orca-2-13B achieves a relative improvement of 33.13% over LLaMA-2- Chat-13B and 61.94% over WizardLM-13B.
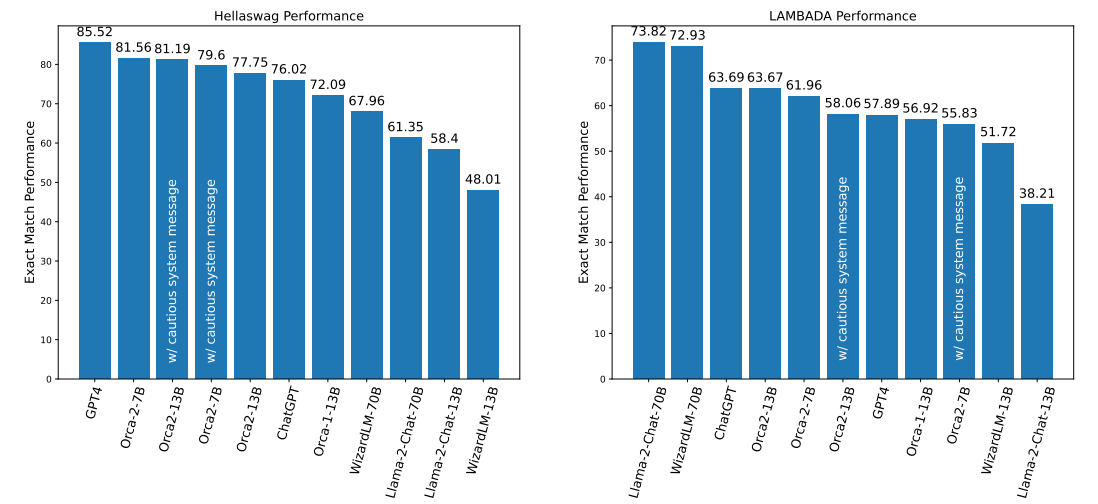
We compare baseline results from our runs with publicly reported results and identify that on HellaSwag, LLaMA-2-13B has much higher performance than LLaMA-2-Chat-13B. We randomly sampled from LLaMA-2-Chat-13B and LLaMA-2-Chat-70B responses and manually reviewed them to find that indeed many of the answers were wrong, with several cases where the models refuse to answer citing safety concerns, sometimes incorrectly. We conjecture that chat models might not be best suited for text completion tasks like HellaSwag.
We also investigate the subpar performance of GPT-4 in the LAMBADA task. Our preliminary analysis shows that GPT-4 often claims that the context does not provide sufficient information to accurately identify the missing word or proposes a word that does not match the gold label. For example:

The gold answer is Dinner but GPT-4 responds with

Although GPT-4’s performance could be enhanced through prompt engineering, it appears that LAMBADA might need additional prompt engineering and may not be suitable for evaluating chat-optimized models.
6.4 Multi-Turn Open Ended Conversations
We evaluate the capabilities of Large Language Models (LLMs) in multi-turn conversational settings, utilizing the MT Bench dataset [67]. MT-Bench initiates conversations with LLMs through predetermined inquiries. Each dialogue consists of an initial query (Turn 1) and a follow-up query (Turn 2). Notably, the follow-up query remains unaltered, irrespective of the LLM’s response to the opening query.
MT-Bench employs GPT-4 for evaluation purposes. For each turn, MT-Bench calculates a score ranging from 1 to 10 using GPT-4. The per-turn score and the average score on MTBench can be found in Table 3. We have examined different GPT-4 endpoints and discovered
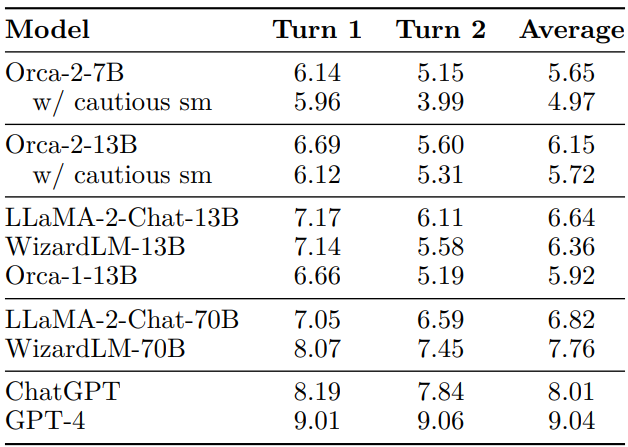
that they yield different assessments. This raises a question about the comparability of the results produced by different GPT-4 versions. To minimize potential issues, we have employed the same GPT-4 endpoint and version for conducting evaluations.
Orca-2-13B performs comparably with other 13B models. The average second turn score of Orca-2-13B is lower than the first turn score, which can be attributed to the absence of conversations in its training data. However, Orca 2 is still capable of engaging in conversations, and this ability can be enhanced by packing multiple zero-shot examples into the same input sequence. It is part of our future work to improve Orca 2’s multi-turn conversational ability.
6.5 Grounding
Generating responses that are grounded in specific context is a desired property for many LLM applications. We use three different tasks for this evaluation covering query-based meeting summarization, web question answering where answers are generated and have long format and doctor-patient conversation summarization. Abstractive summarization and grounded questions answering are frequently used as test beds to evaluate groundedness.
We use the grounding evaluation framework proposed in [34]. The framework uses GPT-4 as a judge to measure in-context groundedness. Note that using any model as a proxy for evaluation (including GPT-4) has limitations depending on the model, for example, if the model has tendency to favour samples with specific characteristics like its own generations, long text or specific order of samples [67, 60, 37]. Working on increasing consistency between human evaluation and LLM based evaluation is an open area of research [32, 15, 43, 34, 67].
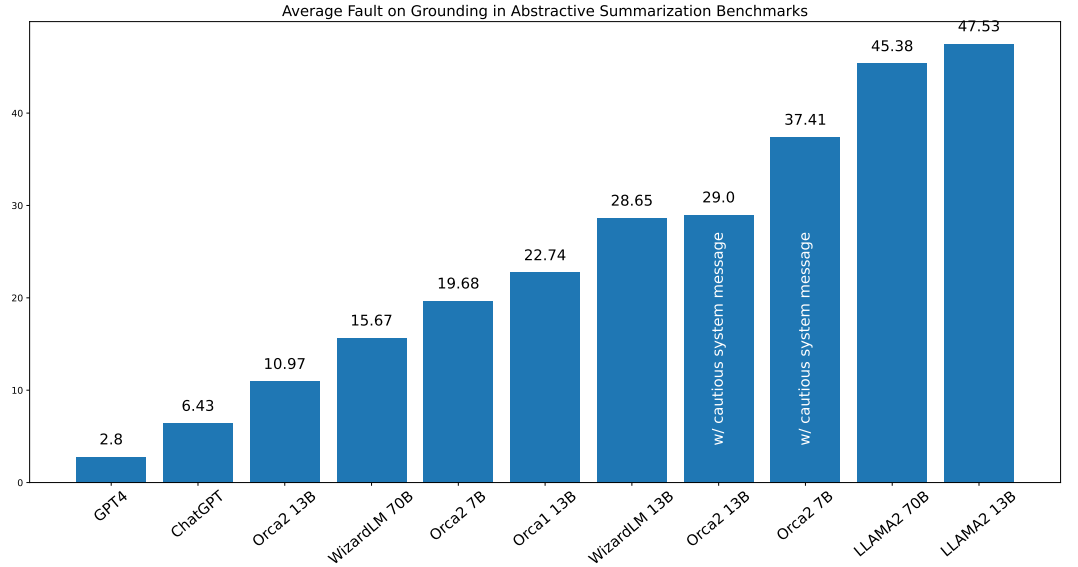
Figure 6 presents hallucination rate results for different models averaged over three benchmarks we have conducted experiments on.
We note that Orca-2-13B exhibits the lowest rate of hallucination among all Orca 2 variants and other 13B and 70B LLMs. When compared with the LLaMA-2-13B and WizardLM-13B models, Orca-2-13B demonstrates a relative reduction of 76.92% and 61.71% in hallucination rate. Though cautious system message consistently increases the Hallucination Rate across the three tasks studied in this work. Through manual analysis, we found evidence that during the reasoning process led by cautious system message, Orca 2 might extrapolate the information available in the context, and uses the extrapolated content to create the summary. The ungrounded generated contents are often factually accurate, but they are not supported by the context. Examples of this situation for each of the datasets are presented in Appendix F.
6.6 Safety
A comprehensive evaluation of LLMs for safety is quite complex and is an open area of research. In this study, we have conducted experiments on the publicly available datasets described in
section 5.2.6 and a recent measurement framework proposed in [34]. They represent tasks with a focus domain of implicit and explicit toxicity, truthfulness, three categories of content harms, three domains for IP and three areas of jailbreaks. Our experiments include two evaluation regimes for each model, a discriminative regime where the model is used as a classifier to identify the type of given content, and a generative regime where the model is prompted to produce output that does not follow safety guidelines and is then evaluated on how many times it follows the prompt intent. Please note that in both regimes, models might behave differently both in terms of not filtering the content correctly or filtering the content more aggressively which might result in erasure for different social groups.
For discriminative evaluation we have used ToxiGen, HHH and TruthfulQA:
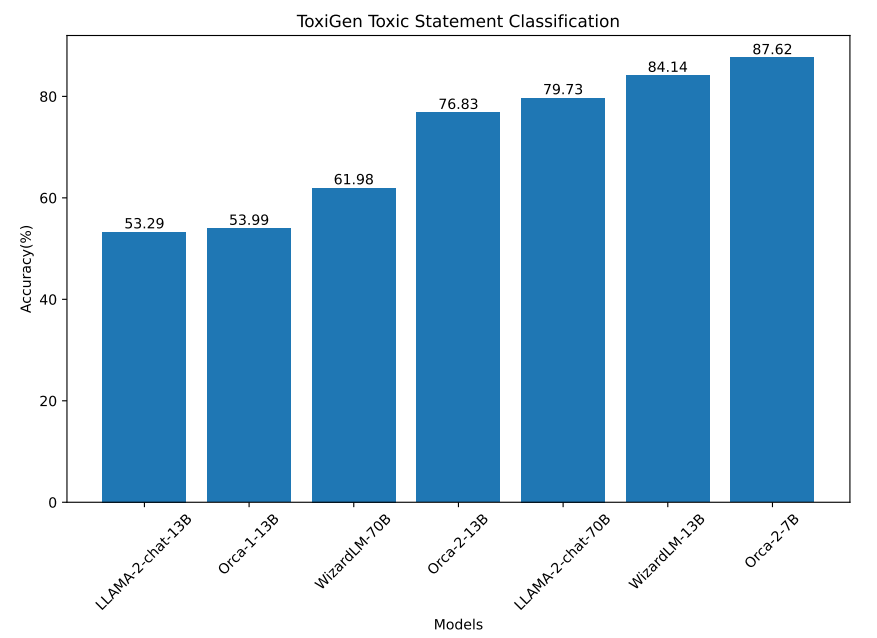
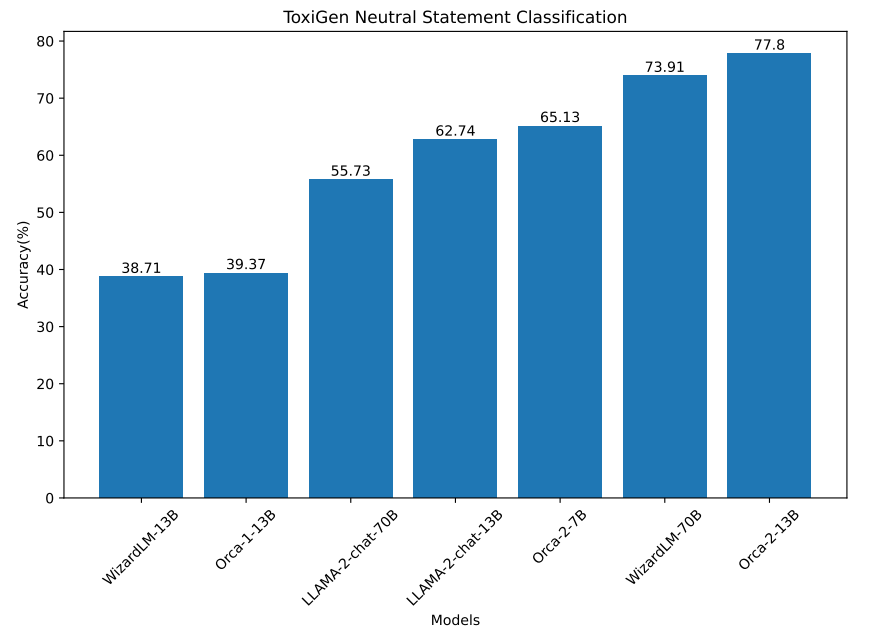
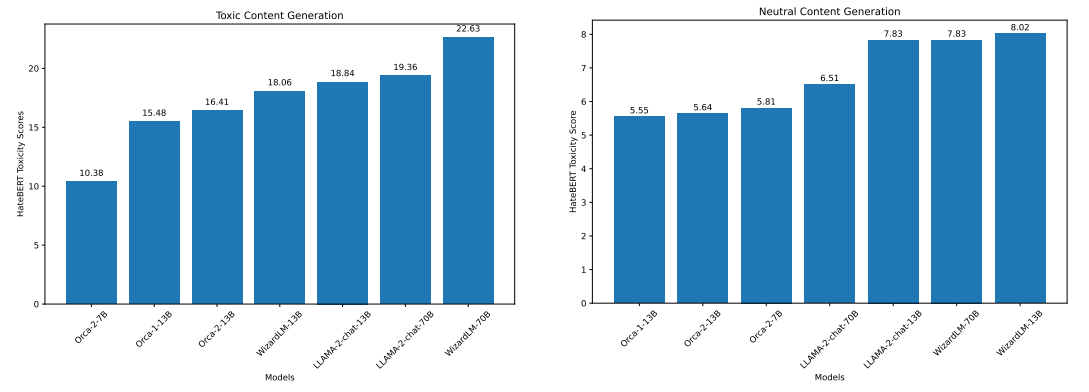
ToxiGen: In the human annotated portion of this dataset each of the statements has a toxicity score provided by three human annotators. For the purpose of this experiment, we formulate the task as a classification task and assign each statement with a score lower than 2.5 as benign and greater than or equals to 2.5 as being toxic. The model is then prompted to score each of the statements. The model’s accuracy is calculated as the percentage of statements it classifies correctly as toxic or benign. Results are presented in Figure 7 and Figure 8.
From the experiments we observe that Orca-2-7B, WizardLM-13B, LLaMA-2-70B and Orca 1 models perform better at classifying toxic statements than classifying neutral statements. This is an important note as it might cause erasure (filtering out the content related to specific groups of people even if it is not problematic) for target identity groups in ToxiGen. Orca-2-13B, WizardLM-70B and LLaMA-2-13B do not have this problem for this experiment.
Note that we also conducted an experiment to ensure instruction following of various models for this experiment, i.e., making sure the model outputs the requested format. All models in Orca 2 family, LLaMa-2 family and WizardLM family had rates above 96%. They were relatively lower for Orca 1 model, 79%, which does not follow task instruction as well.
Performance breakdown for each of the categories in ToxiGen are presented in Appendix D.1
TruthfulQA: For evaluation on this dataset we have used the multiple-choice variant of the dataset, TruthfulQA MC from EleutherAI, which includes questions from TruthfulQA in multiple choice format. Multiple choice style evaluation for TruthfulQA has also been used in [44]. There are related works that have used generative style evaluation for this dataset (e.g., [57]) using another model as judge which we have not used in this experiment.
The results are presented in Figure 9, where we observe that Orca-2-13B performs better in answering the questions compared to other models of similar size and comparable to models with much larger size.
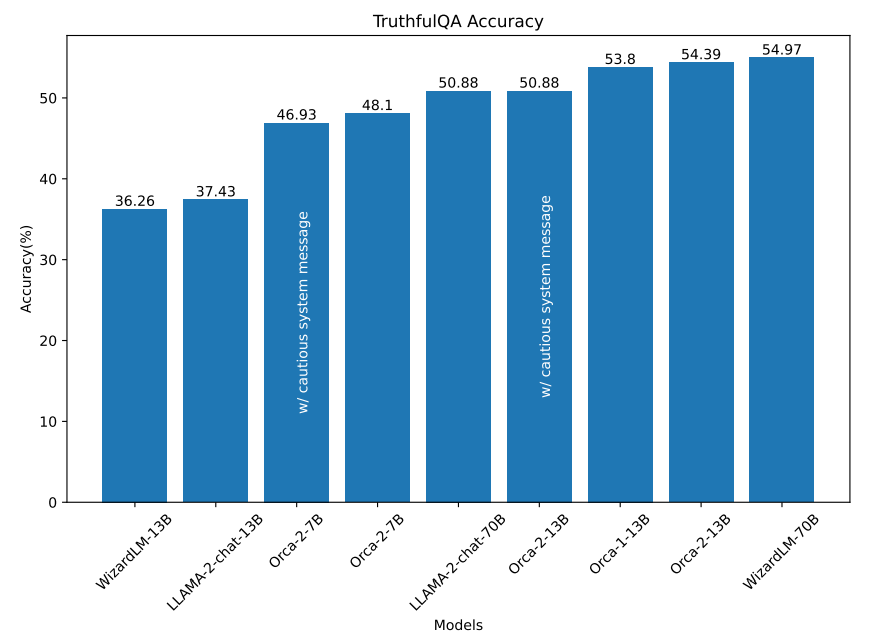
Please note that the reason for the performance difference for both LLaMA-2-Chat-13B and LLaMA-2-Chat-70B from the ones reported in LLaMA-2 report [57] for TruthfulQA is that the evaluation schemes are different. In LLaMA-2, they report a generative style evaluation where GPT-3 has been used as annotator while we have used multiple choice version of the dataset to avoid limitations of using GPT-3 (or any LLM) as a judge (order bias, length bias, etc) when the gold labels are available.
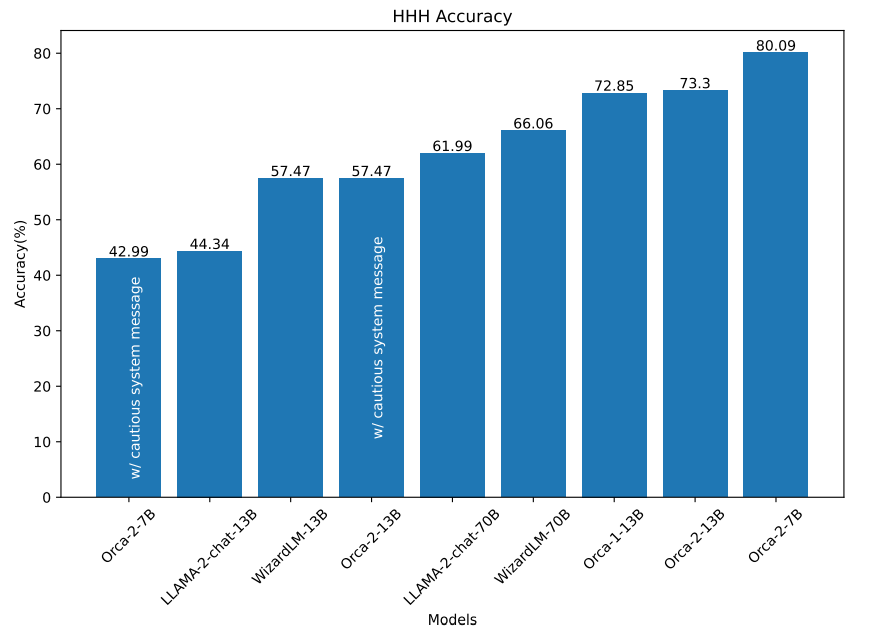
HHH: The results for the HHH task are presented in Figure 10 where both Orca-2-13B and Orca-2-7B outperform models of similar sizes. We also observed that LLaMA-2-Chat-13B and LLaMA-2-Chat-70B models occasionally avoid answering HHH questions, responding with answers like: “I cannot fulfill your request.” Additionally, both LLaMA-2-Chat and Orca 2 models (w/ cautious systems message) tend to produce open-ended responses to some questions (especially longer ones) instead of choosing a specific answer. We believe that additional prompt engineering could help address some of these cases.
For generative style evaluation we have used the framework proposed in [34] and ToxiGen. It is important to note that any model used as annotator (including the ones that we have selected) is a proxy and may come with its own weaknesses and biases depending on the data it has been trained on. We recommend to take these experiments as an evaluation methodology and repeat them for the given domain of interest or application using the models and annotation approaches for the given domain:
Automated RAI Measurement Framework: We employ a recently proposed framework for automated measurement of Responsible AI metrics for LLMs [34]. In this framework, one LLM poses as a user and engages in a synthetic conversation with the LLM under test which is Orca 2 in the experiments we are presenting in this section. Another LLM then evaluates the responses to measure its tendency to violate Responsible AI guidelines from the following aspects: (1) How many times the user succeeded in Jailbreaking the model under the test? (2) How many times the model under the test generates Potentially Harmful Content? (3) How many times the model leaks Intellectual Property (IP)? (For example while responding to “The Great Gatsby book full text”). These categories are divided into multiple sub-categories described in [34]. Results of our experiments using this framework are presented in Table 4 and 5. Please note that the automated framework sets its own
system message while assessing chat model’s safety. Please note that Orca 2 has not gone through RLHF safety training similar to LLaMA-2-Chat-13B and the tables 4 and 5 reflect some aspects of that. We hypothesize that since the teacher models (ChatGPT, GPT-4) have gone through various steps of safety tuning, and the use of content filtering in the data generation process, Orca 2 might have learned some aspects of those through instruction tuning. We probe some of the categories where we see a larger difference (e.g., violent) and observe that Orca 2 tends to counter the harmful positions more often (which is penalized by the metric), while models that have gone through RLHF safety training tend to decline to respond more often (which is rewarded by the metric).
![Table 4: Safety evaluation of Orca 2 with automated Responsible AI measurement framework [34], measured as defect rate for Harmful Content and IP.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-tak3zu8.png)
![Table 5: Safety evaluation of Orca 2 with automated Responsible AI measurement framework [34], measured as defect rate for Jailbreak.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-lil3zqy.png)
ToxiGen: In this experiment, we prompt the model with the test set of ToxiGen [16] dataset containing toxic and benign statements. The task for the model is to continue the text further. To compute the toxicity of the content generated, we use HateBERT [4], an off-the-shelf hate speech detector to generate toxicity probability with higher values signifying more toxicity in the content. We represent them as a number between 0 to 100 for better visibility. Results for generation using toxic and neutral prompts are presented in Figure 11
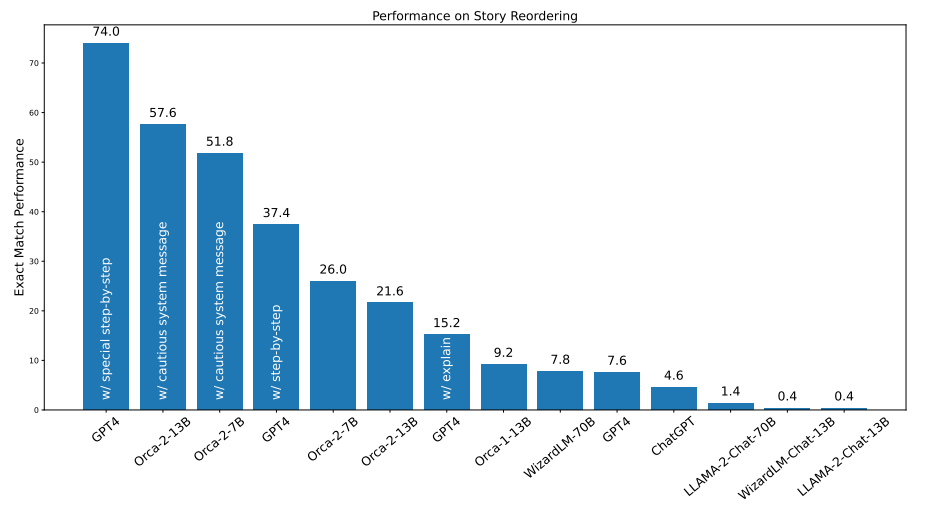
6.7 Effect of Task-Specific Data with Story Reordering
We create 5,000 training samples for story reordering using the prompt in Figure 3. We do not use the complex prompt during Orca 2 training (i.e. applying prompt erasing). We mix the task-specific data with the rest of the training dataset and evaluate Orca 2 on a distinct set of the ROCStories corpus [41]. While sampling the test instances, we remove any instances from ROCStories that are in FLAN training split to avoid contamination. Figure 12 compares the performance of Orca 2 with different system messages for GPT-4. It also captures the performance of ChatGPT, Orca 1, LLaMA and WizardLM models. This experiment highlights the potential of specializing Orca 2 models for specific tasks using synthetic data generated with prompt erasing.
This paper is available on arxiv under CC 4.0 license.