

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Ghazaleh H. Torbati, Max Planck Institute for Informatics Saarbrucken, Germany & [email protected];
(2) Andrew Yates, University of Amsterdam Amsterdam, Netherlands & [email protected];
(3) Anna Tigunova, Max Planck Institute for Informatics Saarbrucken, Germany & [email protected];
(4) Gerhard Weikum, Max Planck Institute for Informatics Saarbrucken, Germany & [email protected].
Table of Links
- Abstract and Introduction
- Related Work
- Methodology
- Experimental Design
- Experimental Results
- Conclusion
- Ethics Statement and References
V. EXPERIMENTAL RESULTS
A. Comparison of CUP against Baselines

• LLM-Rec also performs poorly. Solely relying on the LLM’s latent knowledge about books is not sufficient when coping with long-tail items that appear sparsely in the LLM’s training data. Popularity and position bias [31] further aggravate this adverse effect. Thus, to address RQ1 (see Section I-B), merely and fully resorting to LLMs alone is not a viable solution.
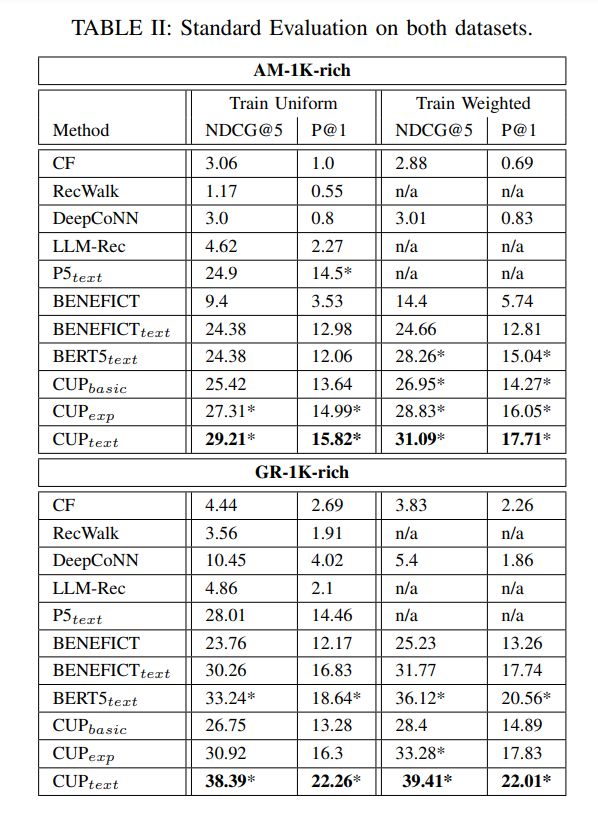


We also ran extended CUP configurations where precomputed CF vectors were incorporated (see Section III-B). These achieved only very minor gains in some of the settings, and there was even a detrimental effect on some cases. We omit these hybrid methods here. We will revisit them in Subsection V-C for sensitivity studies on data density. Another observation is that the weighted training almost always improves performance. Therefore, the following subsections focus on results with weighted training samples.
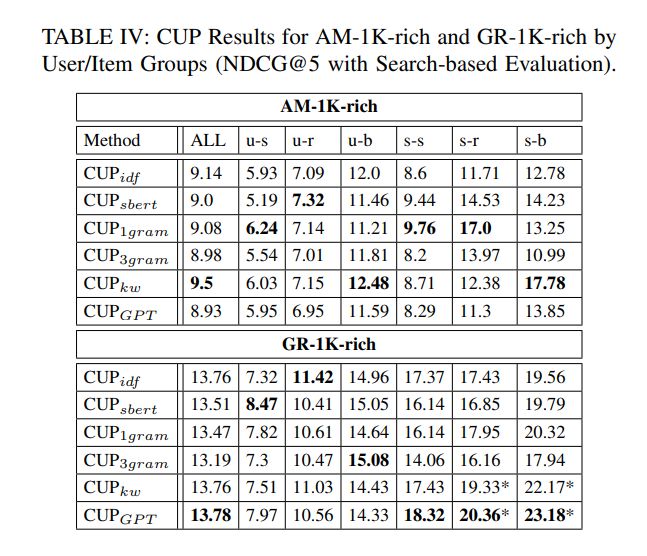
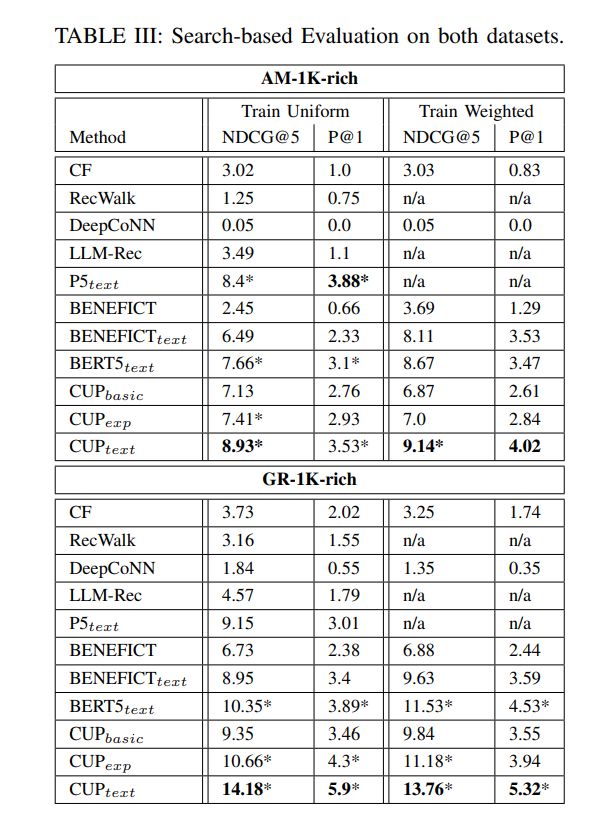
B. Comparison of CUP Configurations

• On the GR-1K-rich data, the overall performance is higher than for AM across all configurations. This can be attributed to the fact that GR has longer reviews, and these texts tend to be more informative than the ones in the AM data (which sometimes refer to packaging, shipment and other non-content aspects).
C. Influence of Interaction Density
The slices AM-1K-rich and GR-1K-rich are constructed with a text-centric stress-test in mind. Both are extremely sparse in terms of user-item interactions. To study the influence of sparseness in isolation, we created two larger samples of both datasets, one still sparse by design and the other denser in terms of users sharing items. We refer to these as AM-10Ksparse and AM-10K-dense, and analogously for GR. All these samples cover 10K users: 10x more users than our previous text-rich slices, to allow more potential for learning from interactions. Table I in Section IV-B shows statistics.
The datasets are constructed as follows. To ensure connectivity in the interaction graphs, we first select 500 users and sample 2000 books connected to these users, both uniformly at random. This is the seed for constructing two variants of data, based on the cumulative item degrees of users, that is, the sum of the #users per book for all books that the user has in her collection:
• 10K-dense: We randomly select 10K (minus the initial 500) users from all users in proportion to the users’ cumulative item degrees. This favors users with many or popular books.
• 10K-sparse: We select users inversely proportional to their cumulative item degrees, thus favoring sparse users.
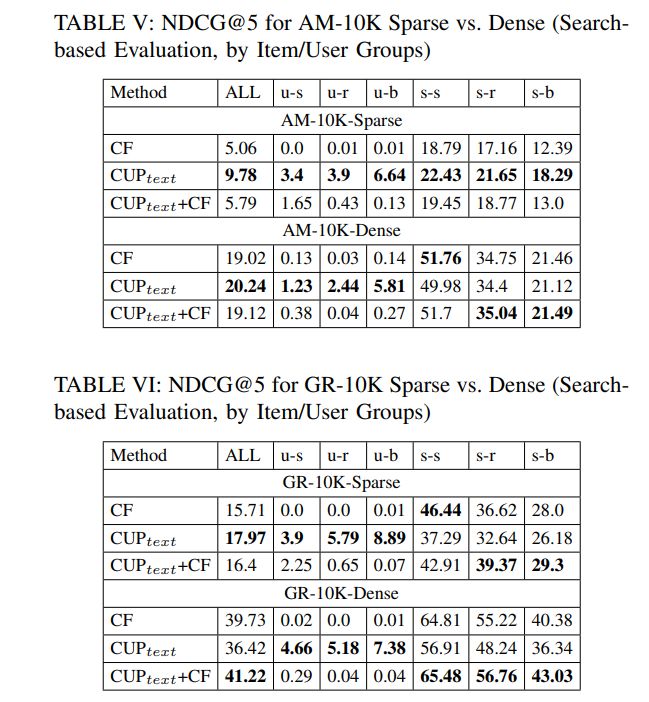
In this sensitivity study, we focus on comparing CF (based on matrix factorization) against our default CUPtext configuration (with idf-selected sentences) and the hybrid combination CUPtext +CF. Tables V and VI show the results for the AM10K data and GR-10K data, comparing the sparse vs. the dense variants with search-based evaluation (corresponding results with standard evaluation are on the project web page). Key insights are:
• As the 10K-sparse data is already much denser than the stress-test 1K-rich slices, CF can achieve decent results on the sparse data. Especially in search-based mode, CF is almost on par with CUP. Note that these gains come from the seen items alone, as CF is bound to fail on unseen items.
• CUPtext is still the clear winner on the sparse variant. The hybrid configuration, with text and CF vectors combined, is inferior to learning from text alone.
• For the 10K-dense data, CF alone performs well, as this is the traditional regime for which CF has been invented. An interesting point arises for the search-based mode and with dense data. Here, the negative test points are closer to the positive sample (after the BM25 search), and pose higher difficulty for text cues alone to discriminate them. Thus, CF becomes more competitive. On GR, hybrid CUP+CF performs best.
D. Efficiency of CUP
Two architectural choices make CUP efficient:
• input length restricted to 128 tokens, and
• fine-tuning only the last layer of BERT and the FFN layers.
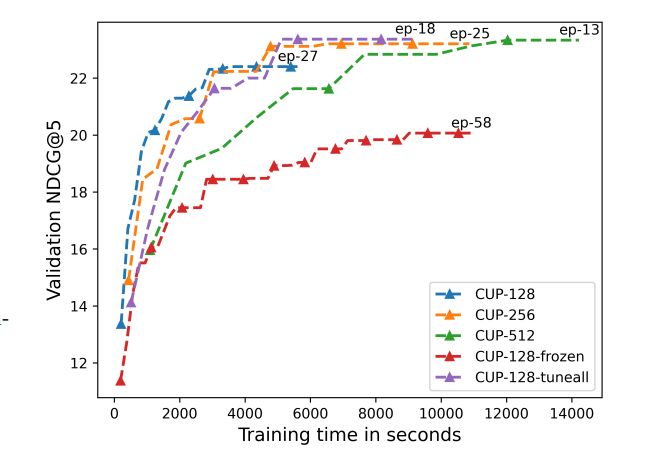
For more analysis, we measured the training time and resulting NDCG on the GR-1K-rich data, comparing different input size budgets and choices of which parameters are tuned and which ones are kept frozen. Figure 2 shows the results.
We observe that the 128-token configuration has the lowest training cost: significantly less time per epoch than the other variants and fast convergence (reaching its best NDCG already after 15 epochs in ca. 3000 seconds). The 256- and 512-token models eventually reach higher NDCG, but only by a small margin and after much longer training time. This confirms that concise user profiles, with a small token budget, are the best approach in terms of benefit/cost ratio.
As for configurations with more or less tunable parameters, we observe that the variant with frozen BERT takes much longer to converge and is inferior to the preferred CUP method even after more than 50 epochs. The other extreme, allowing all of BERT parameters to be altered together with the FFN parameters, performs best after enough training epochs, better than the CUP configuration that tunes only the last BERT layer. However, it takes almost twice as much time per epoch. So again, from the benefit/cost perspective, our design choice hits a sweet spot in the spectrum of model configurations.