

Authors:
(1) Kexun Zhang, UC Santa Barbara and Equal contribution;
(2) Hongqiao Chen, Northwood High School and Equal contribution;
(3) Lei Li, Carnegie Mellon University;
(4) William Yang Wang,UC Santa Barbara.
Table of Links
- Abstract and Intro
- Related Work
- ToolDec: LLM Tool Use via Finite-State Decoding
- Experiment: ToolDec Eliminates Syntax Errors
- Experiment: ToolDec Enables Generalizable Tool Selection
- Conclusion and References
- Appendix
5. EXPERIMENT II: TOOLDEC ENABLES GENERALIZABLE TOOL SELECTION
In Experiment II, we show how TOOLDEC generalizes to unseen tools without additional training data and tool documentation. We compare TOOLDEC with two strong baselines—ToolkenGPT (Hao et al., 2023) as a representative fine-tuning approach, and RestGPT (Song et al., 2023) as a representative in-context learning approach. We conducted experiments on three benchmarks— FuncQA (Hao et al., 2023) and KAMEL (Kalo & Fichtel, 2022), and RestBench (Song et al., 2023). These benchmarks require diverse tool sets from very different domains, including math reasoning, knowledge question answering and real-world web services. In all three domains, our results show that TOOLDEC is able to efficiently generalize to new tools without fine-tuning on extra data.
5.1 FINE-TUNING BASELINE: TOOLKENGPT
ToolkenGPT is a fine-tuning approach to tool use that learns a special token for every tool. To generalize to new tools, ToolkenGPT still needs additional data and extra fine-tuning involving the use of new tools. We demonstrate that TOOLDEC, once fine-tuned on a given set of seen tools, doesn’t need additional data and further fine-tuning to adopt unseen tools. We compare TOOLDEC and the baselines by tuning them on the same subset of tools, denoted as “seen tools”, and then evaluate their performance on “unseen tools”.
To guarantee a fair comparison, We mimic ToolkenGPT’s planning method to solve the “when to use tools” problem. Specifically, we fine-tune the embedding of a single special token <T> to represent all tools, reducing the size of extra vocabulary to 1. Once <T> is generated, a tool call begins.
We prompt LLM to generate a tool name. The generation of this tool name is guided by an FSM constructed from a list of all available tools. This tool name is then plugged back into the context to start the generation of arguments. We show an example of this process in Appendix A.2.
We selected a small subset of “seen tools” out of all available tools and tuned the embedding only with demonstrations of the tools in the selected subset. We fine-tuned the baseline using the same subset. Then, we evaluated our method and the baselines on tasks that involve unseen tools in the subset to demonstrate TOOLDEC’s generalization ability.
Benchmark on Math Functions. We use FuncQA multi-hop questions to evaluate our method. Tools in FuncQA, such as permutate, gcd, power are mathematical functions that strictly limits on their arguments to be numbers in certain ranges. We select 4 out of 13 tools as the seen subset to tune the baseline and evaluate different approaches on the remaining 9 unseen tools.
Benchmark on Knowledge Graph Relations. To further investigate TOOLDEC’s generalizability on a larger set of tools, we also evaluate on KAMEL (Kalo & Fichtel, 2022), a question-answering dataset containing a total of 234 knowledge relations that resemble the characteristics of APIs (e.g. number of children). More examples can be found in Appendix A.4. The tools in KAMEL are many more than those in FuncQA. They are also more complex and diverse because the number of arguments to their tools varies from 1 to 3, and their types include strings, locations, dates, numbers and other ad-hoc types. We select 30 out of 234 tools as the seen subset and evaluate on 4 different evaluation sets, with 30, 60, 100, and 234 tools, respectively. Following Hao et al. (2023), we use prompting, few-shot, and zero-shot as extra baselines. (1) Prompting relies on the internal knowledge of LLM, since no tool was provided. (2) Few-shot demonstrates tool use through few-shot examples. (3) Zero-shot provides descriptions of all available tools in context. Since the KAMEL’s training and evaluation dataset share the same question template for every tool, which is often not true in real-world settings, we compare TOOLDEC only to ToolkenGPT trained on the synthetic dataset proposed by the original study. We use the accuracy of tool calls as a metric, which is determined by the proportion of responses that invoke the correct knowledge relation.
5.2 IN-CONTEXT LEARNING BASELINE: RESTGPT
RestGPT (Song et al., 2023) is an in-context learning approach that learns tool use from in-context tool documentation. We demonstrate the generalization ability of TOOLDEC-enhanced RestGPT by showing that RestGPT with TOOLDEC can achieve better accuracy without in-context documentation than the RestGPT baseline with documentation. Since TOOLDEC needs access to the next token distribution, we use Vicuna-based (Zheng et al., 2023) RestGPT as the baseline. For our method, we remove all tool documentation from the prompt, leaving only the instructions for reasoning.
Benchmark on APIs for Real-World Web Services. We evaluate on RestBench (Song et al., 2023). It consists of tasks in real-world scenarios including TMDB, a website for movie information, and Spotify, an online music player. These tasks directly come from real-user instructions and require multiple tools in the form of RESTful APIs to solve. RESTful APIs are the de facto standard for web services (Li et al., 2016) that use HTTP methods to manipulate resources. The ground truth solutions are annotated by humans in the form of tool call chains. We evaluate our method and the baseline on TMDB, which consists of 55 RESTful APIs. Since HTTP methods such as GET and POST have a format different from the tool call, tool arguments format of TOOLDEC. We rewrote these APIs to follow this format. We use the correct path rate (CP%) proposed by the original paper as the metric to measure accuracy. Correct path rate is the proportion of model outputs that contain the correct tool call path annotated by humans.
5.3 EXPERIMENT RESULTS
Generalization to Unseen Math Functions. In Figure 5a, we present the results on FuncQA. While ToolkenGPT and TOOLDEC achieved similar accuracies on tasks that involved only seen tools, ToolkenGPT failed to generalize to unseen tools, resulting in a significant performance drop. On the other hand, TOOLDEC was able to maintain a comparable accuracy even on unseen tools and achieve 8x better accuracy on multi-hop problems, underscoring its generalizability. Consequently, TOOLDEC significantly outperformed ToolkenGPT on total accuracy.

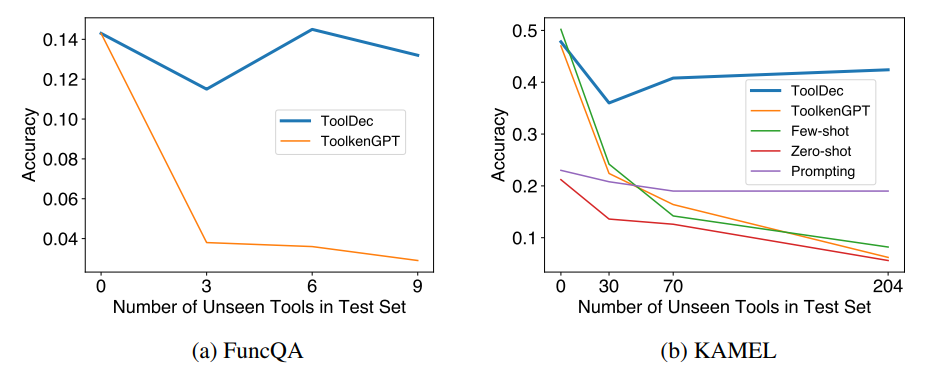
Generalization to Unseen Knowledge Graph Functions. We present our results on KAMEL in Figure 5b. As the number of available tools increased, the two ICL methods suffered from the context length limit (Hao et al., 2023) and experienced a significant drop in accuracy. ToolkenGPT, fine-tuned on the first 30 tools, was also unable to generalize to more tools. Prompting kept a stable low accuracy because it did not rely on in-context tool documentation. On the other hand, TOOLDEC was able to maintain its accuracy even when the amount of unseen tools reached 204.
Generalization to Unseen Web Services. The results on RestBench are reported in Table 5. TOOLDEC enabled the model to use web-service APIs without in-context documentation, reducing the prompt size from 1974 tokens to only 880 tokens. Nevertheless, TOOLDEC still significantly outperformed the baseline in terms of correctness indicated by correct path ratio (CP%), raising it by 8 points. These results suggest that TOOLDEC can also improve the generalizability of in-context learning tool use in real-world web applications.
Results from all three settings indicate that not only does TOOLDEC help fine-tuning tool LLMs generalize without extra training data, it also helps in-context learning tool LLMs generalize without in-context documentation. This capability of TOOLDEC has been proven in three different domains.
This paper is available on arxiv under CC 4.0 DEED license.