
Analytics on DynamoDB
Engineering teams often need to run complex filters, aggregations and text searches on data from DynamoDB. However, DynamoDB is an operational database that is optimized for transaction processing and not for real-time analytics. As a result, many engineering teams hit limits on analytics on DynamoDB and look to alternative options.
That’s because operational workloads have very different access patterns than complex analytical workloads. DynamoDB only supports a limited set of operations, making analytics challenging and in some situations not possible. Even AWS, the company behind DynamoDB, advises companies to consider offloading analytics to other purpose-built solutions. One solution commonly referenced is Elasticsearch which we will be diving into today.
DynamoDB is one of the most popular NoSQL databases and is used by many web-scale companies in gaming, social media, IoT and financial services. DynamoDB is the database of choice for its scalability and simplicity, enabling single-digit millisecond performance at scales of 20M requests per second. In order to achieve this speed at scale, DynamoDB is laser focused on nailing performance for operational workloads- high frequency, low latency operations on individual records of data.
Elasticsearch is an open-source distributed search engine built on Lucene and used for text search and log analytics use cases. Elasticsearch is part of the larger ELK stack which includes Kibana, a visualization tool for analytical dashboards. While Elasticsearch is known for being flexible and highly customizable, it is a complex distributed system that requires cluster and index operations and management to stay performant. There are managed offerings of Elasticsearch available from Elastic and AWS, so you don’t need to run it yourself on EC2 instances.
Shameless Plug: Rockset is a real-time analytics database built for the cloud. It has a built-in connector to DynamoDB and ingests and indexes data for sub-second search, aggregations and joins. But this post is about highlighting use cases for DynamoDB and Elasticsearch, in case you want to explore that option.
Connecting DynamoDB to Elasticsearch Using AWS Lambda
You can use AWS Lambda to continuously load DynamoDB data into Elasticsearch for analytics. Here’s how it works:
- Create a lambda function to sync every update from a DynamoDB stream into Elasticsearch
- Create a lambda function to take a snapshot of the existing DynamoDB table and send it to Elasticsearch. You can use an EC2 script or an Amazon Kinesis stream to read the DynamoDB table contents.
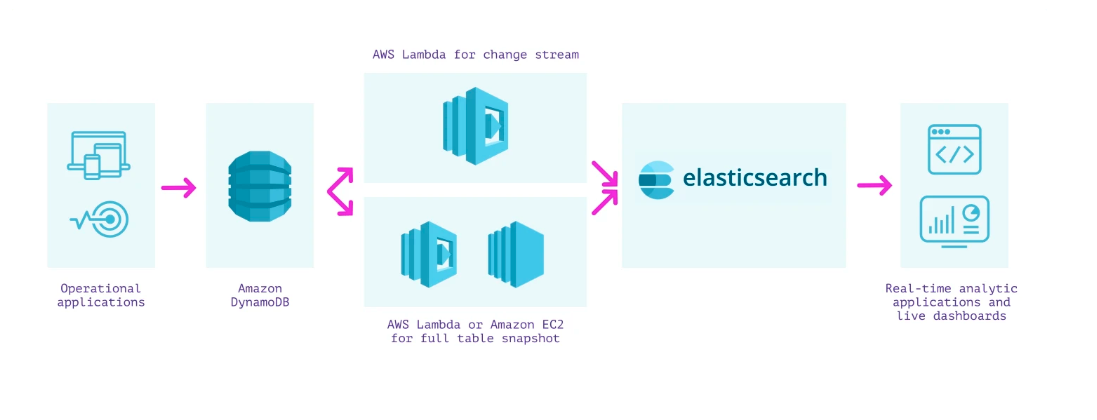
There is an alternative approach to syncing data to Elasticsearch involving the Logstash Plugin for DynamoDB but it is not currently supported and can be complex to configure.
Text Search on DynamoDB Data Using Elasticsearch
Text search is the searching of text inside a document to find the most relevant results. Oftentimes, you’ll want to search for a part of a word, a synonym or antonyms of words or a string of words together to find the best result. Some applications will even weight search terms differently based on their importance.
DynamoDB can support some limited text search use cases just by using partitioning to help filter data down. For instance, if you are an ecommerce site, you can partition data in DynamoDB based on a product category and then run the search in-memory. Apparently, this is how Amazon.com retail division handles a lot of text search use cases. DynamoDB also supports a contains function that enables you to find a string that contains a particular substring of data.
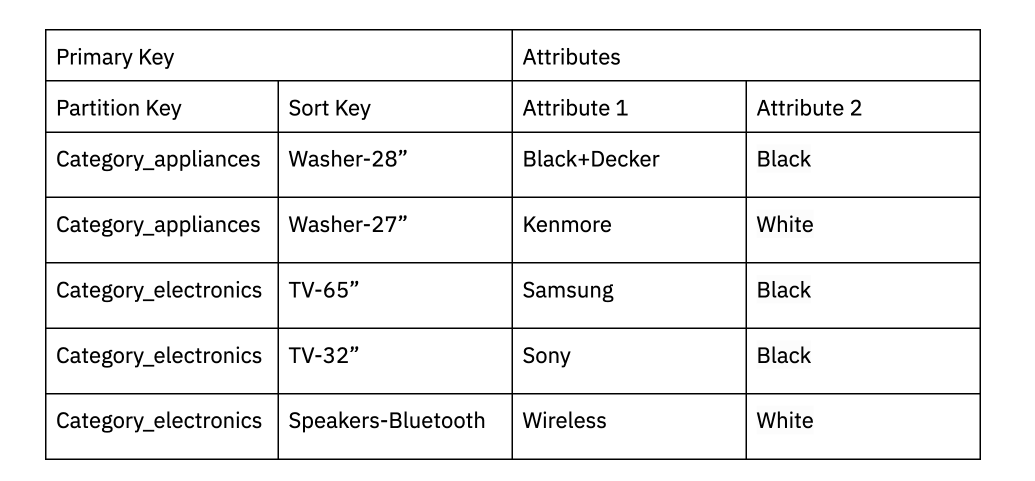
An e-commerce site might partition data based on product category. Additional attributes may be shown with the data being searched like the brand and color.
In scenarios where full text search is core to your application, you’ll want to use a search engine like Elasticsearch with a relevancy ranking. Here’s how text search works at a high level in Elasticsearch:
-
Relevance ranking: Elasticsearch has a relevance ranking that it gives to the search results out-of-the-box or you can customize the ranking for your specific application use case. By default, Elasticsearch will create a ranking score based on the term frequency, inverse document frequency and the field-length norm.
-
Text analysis: Elasticsearch breaks text down into tokens to index the data, called tokenizing. Analyzers are then applied to the normalized terms to enhance search results. The default standard analyzer splits the text according to the Unicode Consortium to provide general, multi-language support.
Elasticsearch also has concepts like fuzzy search, auto-complete search and even more advanced relevancy can be configured to meet the specifics of your application.
Complex Filters on DynamoDB Data Using Elasticsearch
Complex filters are used to narrow down the result set, thereby retrieving data faster and more efficiently. In many search scenarios, you’ll want to combine multiple filters or filter on a range of data, such as over a period of time.
DynamoDB partitions data and choosing a good partition key can help make filtering data more efficient. DynamoDB also supports secondary indexes so that you can replicate your data and use a different primary key to support additional filters. Secondary indexes can be helpful when there are multiple access patterns for your data.
For instance, a logistics application could be designed to filter items based on their delivery status. To model this scenario in DynamoDB, we’ll create a base table for logistics with a partition key of Item_ID, a sort key of Status and attributes buyer, ETA and SLA.
We also need to support an additional access pattern in DynamoDB for when delivery delays exceed the SLA. Secondary indexes in DynamoDB can be leveraged to filter down for only the deliveries that exceed the SLA.
An index will be created on the field ETADelayedBeyondSLA which is a replica of the ETA attribute already in the base table. This data is only included in ETADelayedBeyondSLA when the ETA exceeds the SLA. The secondary index is a sparse index, reducing the amount of data that needs to be scanned in the query. The buyer is the partition key and the sort key is ETADelayedBeyondSLA.
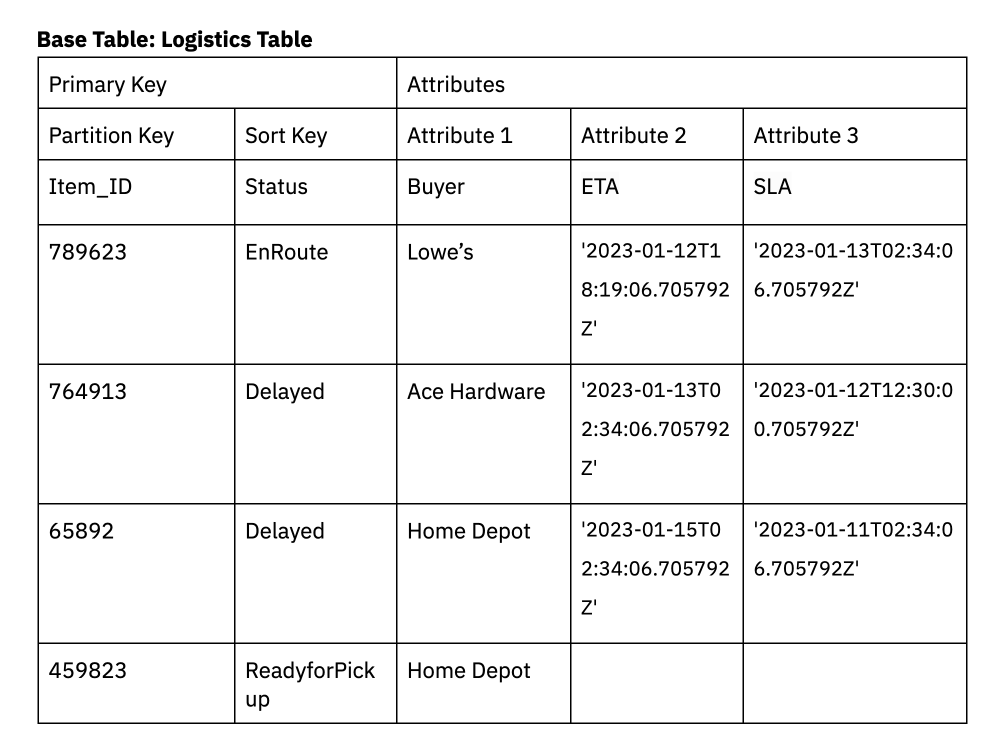
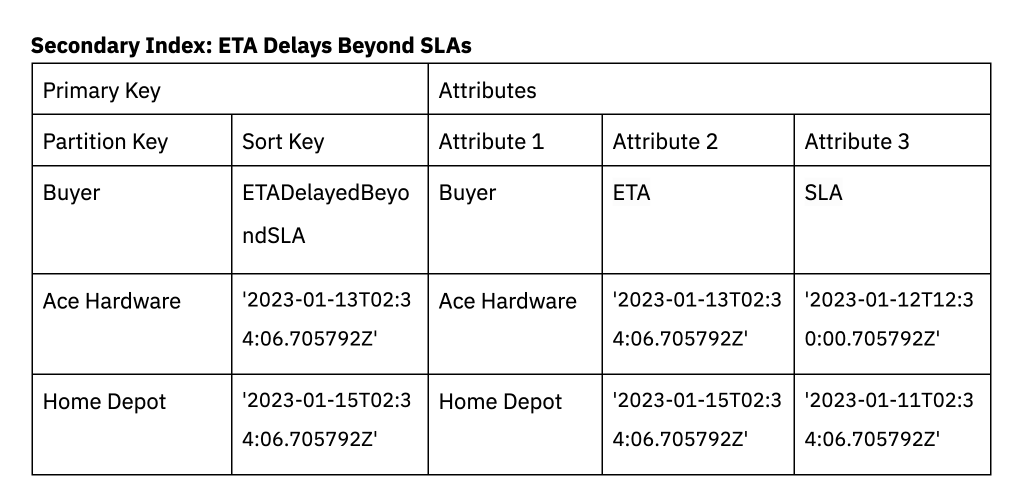
Secondary indexes can be used to support multiple access patterns in the application, including access patterns involving complex filters.
DynamoDB does have a filterexpression operation in its Query and Scan API to filter results that don’t match an expression. The filterexpression is applied only after a query or scan table operation so you are still bound to the 1MB of data limit for a query. That said, the filterexpression is helpful at simplifying the application logic, reducing the response payload size and validating time-to-live expiry. In summary, you’ll still need to partition your data according to the access patterns of your application or use secondary indexes to filter data in DynamoDB.
DynamoDB organizes data in keys and values for fast data retrieval and is not ideal for complex filtering. When you require complex filters you may want to move to a search engine like Elasticsearch as these systems are ideal for needle in the haystack queries.
In Elasticsearch, data is stored in a search index meaning the list of documents for which column-value is stored as a posting list. Any query that has a predicate (ie: WHERE user=A) can quickly fetch the list of documents satisfying the predicate. As the posting lists are sorted, they can be merged quickly at query time so that all filtering criteria is met. Elasticsearch also uses simple caching to speed up the retrieval process of frequently accessed complex filter queries.
Filter queries, commonly referred to as non-scoring queries in Elasticsearch, can retrieve data faster and more efficiently than text search queries. That’s because relevance is not needed for these queries. Furthermore, Elasticsearch also supports range queries making it possible to retrieve data quickly between an upper and lower boundary (ie: age between 0-5).
Aggregations on DynamoDB Data Using Elasticsearch
Aggregations are when data is gathered and expressed in a summary form for business intelligence or trend analysis. For example, you may want to show usage metrics for your application in real-time.
DynamoDB does not support aggregate functions. The workaround recommended by AWS is to use DynamoDB and Lambda to maintain an aggregated view of data in a DynamoDB table.
Let’s use aggregating likes on a social media site like Twitter as an example. We’ll make the tweet_ID the primary key and then the sort key the time window by which we are aggregating likes. In this case, we’ll enable DynamoDB streams and attach a Lambda function so that as tweets are liked (or disliked) they are tabulated in like_count with a timestamp (ie: last_ updated).
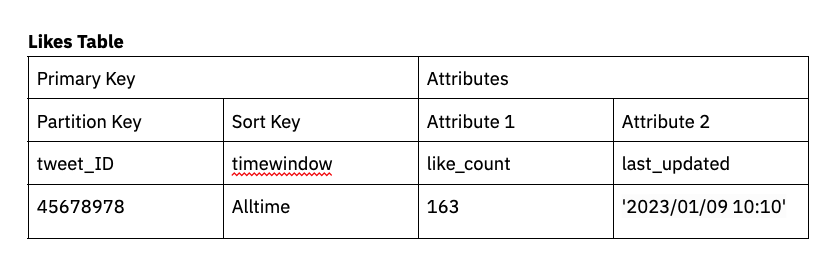
In this scenario, DynamoDB streams and Lambda functions are used to tabulate a like_count as an attribute on the table.
Another option is to offload aggregations to another database, like Elasticsearch. Elasticsearch is a search index at its core and has added extensions to support aggregation functions. One of those extensions is doc values, a structure built at index time to store document values in a column-oriented way. The structure is applied by default to fields that support doc values and there is some storage bloat that comes with doc values. If you only require support for aggregations on DynamoDB data, it may be more cost-effective to use a data warehouse that can compress data efficiently for analytical queries over wide datasets.
Here’s a high-level overview of Elasticsearch’s aggregation framework:
-
Bucket aggregations: You can think of bucketing as akin to
GROUP BYin the world of SQL databases. You can group documents based on field values or ranges. Elasticsearch bucket aggregations also include the nested aggregation and parent-child aggregation that are common workarounds to the lack of join support. -
Metric aggregations: Metrics allow you to perform calculations like
SUM,COUNT,AVG,MIN,MAX, etc. on a set of documents. Metrics can also be used to calculate values for a bucket aggregation. -
Pipeline aggregations: The inputs on pipeline aggregations are other aggregations rather than documents. Common uses include averages and sorting based on a metric.
There can be performance implications when using aggregations, especially as you scale Elasticsearch.
Alternative to Elasticsearch for Search, Aggregations and Joins on DynamoDB
While Elasticsearch is one solution for doing complex search and aggregations on data from DynamoDB, many serverless proponents have echoed concerns with this choice. Engineering teams choose DynamoDB because it is severless and can be used at scale with very little operational overhead. We’ve evaluated a few other options for analytics on DynamoDB, including Athena, Spark and Rockset on ease of setup, maintenance, query capability and latency in another blog.
Rockset is an alternative to Elasticsearch and Alex DeBrie has walked through filtering and aggregating queries using SQL on Rockset. Rockset is a cloud-native database with a built-in connector to DynamoDB, making it easy to get started and scale analytical use cases, including use cases involving complex joins. You can explore Rockset as an alternative to Elasticsearch in our free trial with $300 in credits.