

Table of Links
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
5 DISCUSSIONS
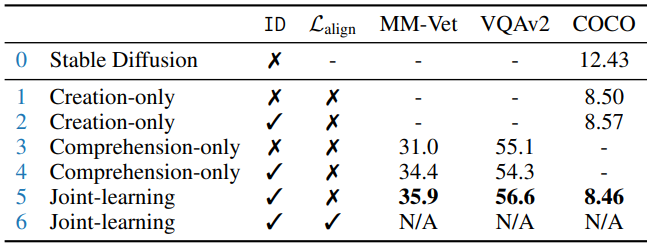
5.1 SYNERGY BETWEEN CREATION & COMPREHENSION?
To elucidate the synergy between multimodal creation and comprehension, we make the comparison among three methods with DREAMLLM architecture, each utilizing identical training data yet differing in their learning objectives: a) the Creation-only baseline, focused solely on text/document-conditional image synthesis; b) the Comprehension-only baseline, dedicated to word generation exclusively; c) the Joint-learning method, which is the default setting of DREAMLLM learning both image and language modeling.

Qualitative Analysis In Fig. 4, we compare answers to some examplar VQA tasks from comprehension-only and joint learning modules, respectively. It can be seen that: i) The joint-learning method exhibits superior multimodal comprehension, particularly in identifying subject relationships and attributes like object size. ii) In multimodal comprehension scenarios involving multiple image inputs, the joint-learning approach demonstrates enhanced precision. This improved performance is a natural outcome of I-GPT pretraining, allowing better modeling of multimodal correlations in various interleaved documents

Multimodal In-Context Generation Multimodal in-context generation is a critical emerging capability for MLLMs (Bommasani et al., 2021; Alayrac et al., 2022). While significant strides have been made in in-context visual question answering, in-context image synthesis remains relatively lacking in exploration. The multimodal context-conditional image synthesis capabilities of DREAMLLM, as demonstrated in Fig. 5, offer promising insights into this domain. Tasks such as in-context image edition, subject-driven image generation, and compositional generation, however, pose significant

challenges in a zero-shot setting, particularly without downstream fine-tuning as in DreamBooth (Ruiz et al., 2023) or attention modification techniques as in Prompt2Prompt (Hertz et al., 2023). Despite these hurdles, Fig. 5 illustrates DREAMLLM’s ability to generate images conditioned on the provided image context. This capability suggests promising potential for DREAMLLM in maintaining subject, identity, and semantic context, thereby paving a new way for resolving these complex tasks.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.