

Test-Time Training for LLMs: Scaling Problem Solving via TextGrad
4 Jun 2026
Discover how TextGrad utilizes test-time training and iterative self-refinement to maximize LLM reasoning.

TextGrad Code Optimization: Outperforming Reflexion on LeetCode Hard
4 Jun 2026
Discover how TextGrad leverages instance optimization and computation graphs to programmatically debug and refine code.
Textual Autograd Mechanics: Computation Graphs in Language Optimization
3 Jun 2026
Explore the core mechanics of TextGrad. Learn how Textual Gradient Descent (TGD) leverages computation graphs and natural language constraints

Textual Gradient Descent: A New Tuning Paradigm for Compound AI
3 Jun 2026
Explore the PyTorch-style approach transforming prompt engineering, software design, and scientific workflows.
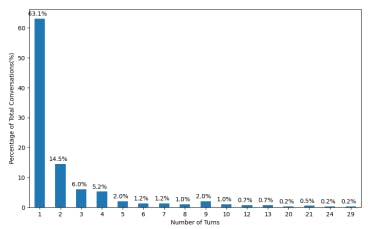
What Developers Ask ChatGPT When Writing Code
13 Nov 2025
Developers are using ChatGPT to code, debug, and review collaboratively. Here’s what GitHub conversations reveal about AI-assisted teamwork.
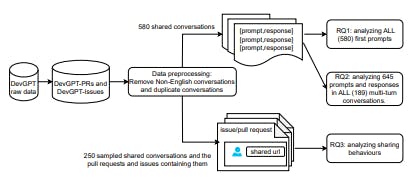
How Developers Use ChatGPT in GitHub Pull Requests and Issues
13 Nov 2025
How developers use ChatGPT in GitHub issues and pull requests—and what their shared conversations reveal about AI-assisted coding.
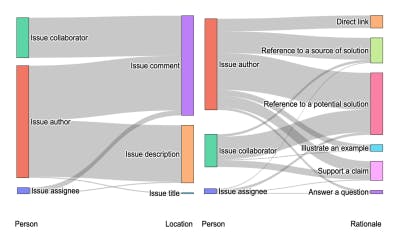
Foundation Models Are Reshaping How Developers Code Together
13 Nov 2025
Developers are sharing ChatGPT chats in open-source projects. Here’s what it reveals about AI-powered collaboration and benchmark design.
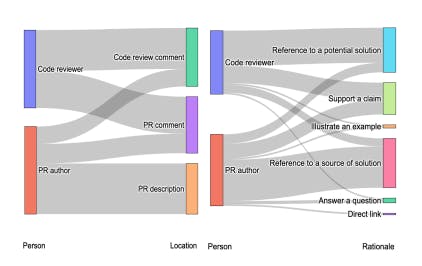
Mapping Why and How Developers Share AI-Generated Conversations on GitHub
13 Nov 2025
Developers are sharing ChatGPT chats in GitHub. This study reveals why, where, and how they do it—and what it means for open-source collaboration.
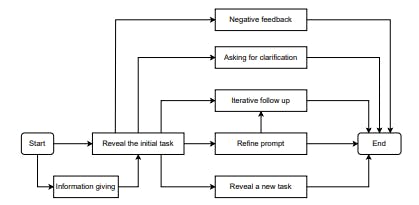
Analyzing the Flow of Developer Prompts in ChatGPT Conversations
12 Nov 2025
How developers interact with ChatGPT across multiple turns—analyzing prompts, feedback, and flow patterns from 645 developer conversations.