
Authors:
(1) Seokil Ham, KAIST;
(2) Jungwuk Park, KAIST;
(3) Dong-Jun Han, Purdue University;
(4) Jaekyun Moon, KAIST.
Table of Links
3. Proposed NEO-KD Algorithm and 3.1 Problem Setup: Adversarial Training in Multi-Exit Networks
4. Experiments and 4.1 Experimental Setup
4.2. Main Experimental Results
4.3. Ablation Studies and Discussions
5. Conclusion, Acknowledgement and References
B. Clean Test Accuracy and C. Adversarial Training via Average Attack
E. Discussions on Performance Degradation at Later Exits
F. Comparison with Recent Defense Methods for Single-Exit Networks
G. Comparison with SKD and ARD and H. Implementations of Stronger Attacker Algorithms
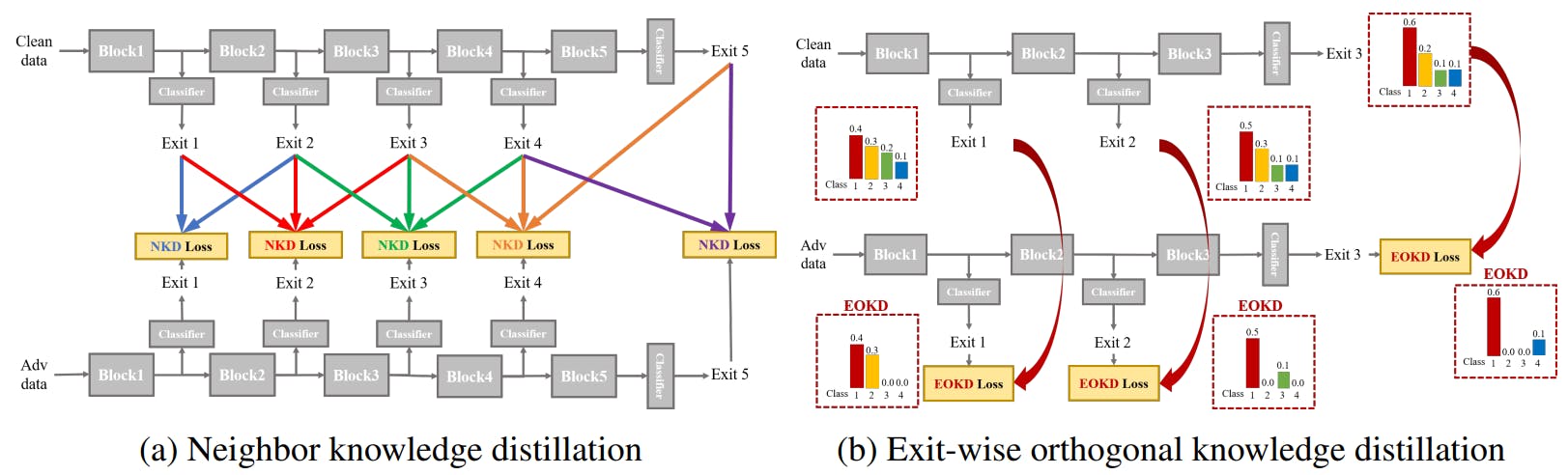
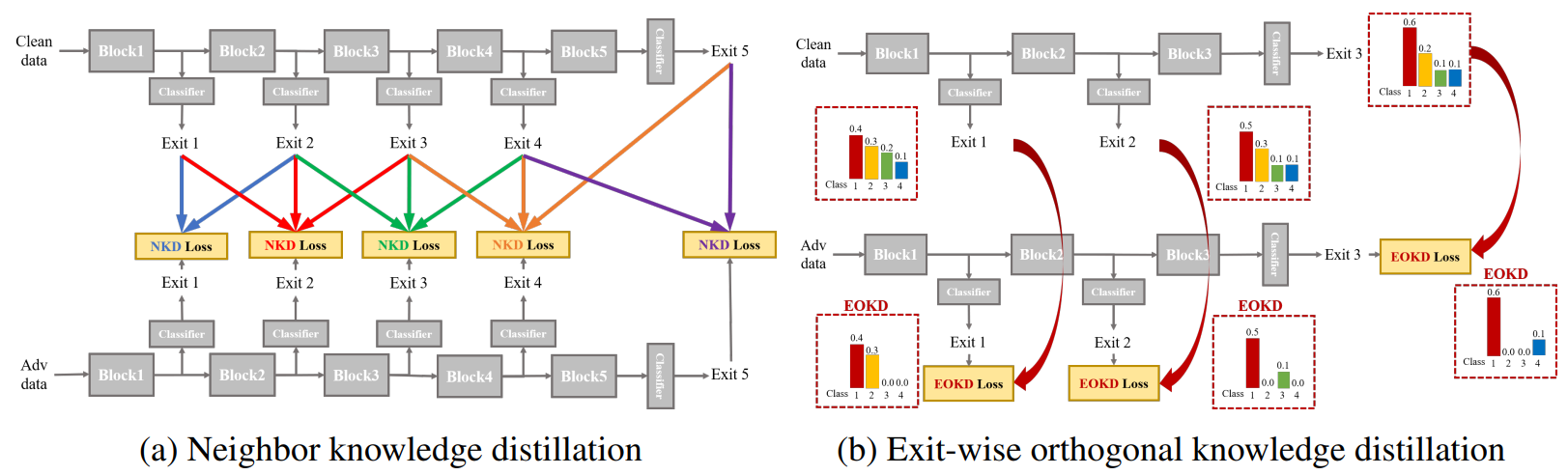
3 Proposed NEO-KD Algorithm

3.1 Problem Setup: Adversarial Training in Multi-Exit Networks


This paper is available on arxiv under CC 4.0 license.