
Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
Table of Links
2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
5 EVALUATION
We evaluated Apparate across a wide range of NLP and CV workloads and serving platforms. Our key findings are:
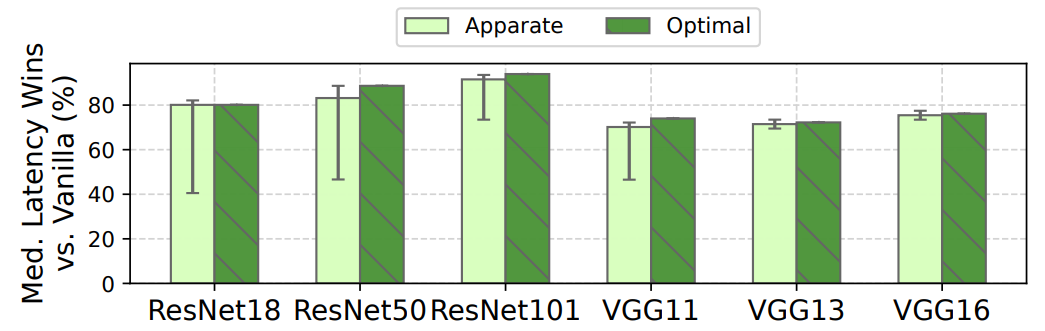
• Apparate lowers 25th percentile and median latencies by 40.5-91.5% and 70.2-94.2% for CV, and 16.0-37.3% and 10.0-24.2% for NLP workloads, compared to original (non-EE) models.
• Unlike existing EE models that unacceptably worsen accuracies and tail latencies by up to 23.9% and 11.0%, Apparate consistently meets specified accuracy and tail latency constraints.
• Apparate automatically generalizes to different model architectures (e.g., compressed) and EE configurations (e.g., ramp style), and its wins gracefully shrink as accuracy or tail-latency constraints grow.
5.1 Methodology
Models. We consider 10 models (across 4 families) that cover popular architectures and a variety of model sizes in both CV and NLP. For CV, we use the ResNet{18, 50, 101} residual models, as well VGG{11, 13, 16} models that follow a chained (linear) design. All of these models are pretrained on ImageNet and from the PyTorch Model Zoo [43]; we further fine-tune the models to our video scenes using a random sampling of 10% of frames across our dataset. For NLP, we consider 3 encoder-only transformers from the BERT family – BERT-base, BERT-large, and Distilbert [45] (a variant of BERT-base that was compressed via distillation) – as well as a decoder-only large language model: GPT2-medium. These models span 66-345 million parameters, were collected from HuggingFace [30], and were pretrained (without more fine-tuning) on Yelp reviews [8] that are separate from any evaluation dataset we use.
Workloads. CV workloads comprise real-time object classification (people, cars) on 8 one-hour videos used in recent video analytics literature [11, 27]. The videos were sampled at 30 frames per second, and collectively span day/night from diverse urban scenes; for each, we perform classification.
NLP workloads focus on sentiment analysis using two datasets: Amazon product reviews [10] and IMDB movie reviews [41]. To the best of our knowledge, there do not exist public streaming workloads for NLP classification, so we convert these datasets into streaming workloads as follows. For Amazon, we follow the order of product categories in the original dataset, but within each category, we keep reviews only from frequent users (i.e., those with >1k reviews) and order streaming by user (250k requests in total). For IMDB, we follow the order of reviews in the original dataset, but stream each in sentence by sentence (180k requests in total). We then define arrival patterns for these ordered requests by using the Microsoft Azure Functions (MAF) as in prior serving work [22]. Specifically, to ensure meaningful and realistic workloads despite the high degree of variation
in runtime across our models, we paired each model with a randomly selected trace snippet from the set that met the following criteria: (1) number of requests match that in our largest dataset, and (2) queries per second should not result in >20% dropped requests with vanilla serving for the given model and selected SLO (described next).
Parameter configurations. Given our focus on interactivity, we cope with heterogeneity in model runtimes by setting SLOs to be 2× each model’s inference time with batch size 1 in our main experiments. This results in SLOs between 13-204 ms, which match the ranges considered in prior work [22, 40, 49]; Table 5 in §A lists the specific SLO values per model, and we study the effect of SLO on Apparate in §5.4. Unless otherwise noted, results use 1% for Apparate’s accuracy constraint (in line with industry reports [42]) and a ramp budget of 2% impact on worst-case latency; we consider other values for both parameters in §5.4.
Setup. Experiments were conducted on a dedicated server with one NVIDIA RTX A6000 housing 48GB of memory, one AMD EPYC 7543P 32-Core CPU, and 256GB DDR4 RAM. We run experiments with two serving platforms: TensorFlow-Serving [39] and Clockwork [22]. We primarily present results with Clockwork due to space constraints, but note that report trends hold for both platforms; we compare cross-platform results in §5.4.
Metrics and baselines. Our main metrics of evaluation are classification accuracy and per-request latencies. Accuracy is defined as the percentage of inputs that are assigned the correct label as defined by each original (i.e., non-EE) model. Per-request latency is measured as the time between when a request arrives at a serving platform, and when its response is released by the platform. We mainly compare Apparate with two baselines: (1) original models without EEs (vanilla) running in serving platforms, and (2) optimal EEs as defined in §2.2, i.e., assuming all inputs exit at their earliest possible ramps with non-exiting inputs incurring no ramp overheads. We compare Apparate to existing EE strategies in §5.3.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.