
Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
Table of Links
2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
5.4 Microbenchmarks
To ease presentation, results in this section use representative CV and NLP models (ResNet50, GPT2-medium) running on a random corpus video and Amazon reviews, respectively. All reported trends hold for all considered workloads.
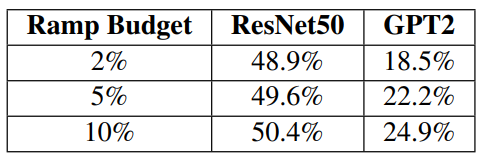
Parameter sensitivity. Recall that Apparate ingests values for two key parameters: ramp aggression (i.e., a ramp budget) and accuracy constraint (i.e., acceptable accuracy loss). Fig. 18 and Tab. 3 studies the effect that these parameters have on Apparate’s latency wins. The findings are intuitive: Apparate’s latency savings over vanilla models decrease as ramp budgets shrink or accuracy constraints tighten. Both trends are a result of Apparate being granted less flexibility for adaptation, either via smaller acceptable threshold ranges (that meet accuracy targets), or active ramp capacity (and thus potential ramp configurations). Importantly, accuracy constraint has a larger impact on Apparate’s wins. The reason is that inter-ramp dependencies result in overlap in the set of inputs that can exit at any ramp when run in isolation; thus, wins from using more ramps eventually hits diminishing returns. Indeed, Apparate begins by using the full budget, only to quickly disable many ramps that have a net negative effect on serving latencies.

Ramp architectures. Although Apparate opts for using many lightweight ramps, it’s adaptation algorithms can support any ramp architecture. To illustrate this, we ran Apparate with DeeBERT’s more expensive ramps (described above). Overall, on the Amazon Reviews dataset, we find that these costlier ramps dampen Apparate’s latency savings by 4% since they constrain Apparate’s runtime adaptation in terms of feasible configurations, i.e., fewer active ramps at any time. Crucially, we note that accuracy constraints were still entirely met due to Apparate’s frequent threshold tuning.
Impact of serving platform. Apparate runs atop existing serving platforms, responding to overall serving (and exiting patterns) rather than altering platform decisions, e.g., for queuing. Table 4 shows that, despite the discrepancies in platform scheduling strategies and knobs, Apparate’s performance wins are largely insensitive to the underlying platform when CV or NLP workloads are configured with the same SLO goal. For example, Apparate’s median latency savings for the Amazon workload and GPT-2 are within 2.9% when using Clockwork or TensorFlow-Serving.
Profiling Apparate. Figure 11 in §3.2 analyzes the runtime and optimality of Apparate’s threshold tuning algorithm. Beyond that, Apparate includes two other overheads while running: ramp adjustment and coordination between its CPU controller and serving GPUs. Ramp adjustment rounds take an average of 0.5 ms. Coordination overheads are also low because of Apparate’s small ramp sizes (definitions and weights consume only ∼10KB) and profiling data (simply a top-predicted result with an error score, collectively consuming around ∼1KB). Thus, CPU-GPU coordination delays take an average of 0.5ms per communication, 0.4ms of which comes from fixed PCIe latencies in our setup.
Importance of Apparate’s techniques. Apparate’s runtime adaptation considers frequent (accuracy-guided) threshold tuning, with periodic ramp adjustments. Table 2 highlights the importance of threshold tuning on average accuracies. Here, we evaluate the importance of ramp adjustment on Apparate’s latency improvements by comparing versions with and without this optimization. Overall, disabling ramp adjustment results in 20.8-33.4% lower median latency wins, though worst-case latency (and throughput) and accuracy constraints remain continually met.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.