

Author:
(1) Brandon T. Willard, Normal Computing;
(2) R´emi Louf, Normal Computing.
Table of Links
- Abstract and Intro
- LLM Sampling and Guided Generation
- Iterative FSM Processing and Indexing
- Extensions to Iterative Parsing
- Discussion, References and Acknowledgments
3. Iterative FSM Processing and Indexing

To be precise, we consider regular expressions in 5-tuple finite automaton form [Sipser, 1996, Definition 1.5]:
Definition 1 (Finite Automaton). A finite automaton, or finite-state machine, is given by (Q, Σ, δ, q0, F), where Q is a finite set of states, Σ a finite alphabet, δ : Q × Σ → Q the transition function, q0 ∈ Q the start state, and F ⊆ Q the set of accept states.
The characters comprising the strings in V are drawn from Σ: i.e. V ⊂ P(Σ). Throughout, the FSM states, Q, will be represented by integer values for simplicity.

Example 1. We illustrate the FSM sampling process in Figure 1 for the regular expression ([0-9]*)?\.?[0-9]*, which can be used to generate floatingpoint numbers. For simplicity, let the vocabulary, V, consist of only the strings: "A", ".", "42", ".2", and "1".
When the generation begins, the FSM is in state 0, so our algorithm masks the string "A", since it would not be accepted by the FSM. We can only sample ".", "42", ".2", and "1" in this case.
If we sample ".2", we advance the FSM to state 3. In this case, only "42" and "1" are valid completions, so we mask the other values before sampling. If we sample "1" instead, we advance the FSM to state 1, in which case ".", ".42", ".2", and "1" are valid completions and the mask remains unchanged.
![Figure 1: FSM masking for the regular expression ([0-9]*)?\.?[0-9]*.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-dwa3u6g.png)
Looping through the vocabulary to determine the valid next tokens is still the biggest issue. For that, we pre-process the vocabulary using the regular expression’s FSM and build an index. The important part is that we consider starting in every viable FSM state, because the strings in the vocabulary could match arbitrary parts of a regular expression, and those parts are implicitly the FSM states.
A procedure for producing matches starting at any point in the FSM is given in Algorithm 3. The result is a list of sub-sequences detailing the states through which the FSM would traverses when accepting the provided string.

By matching the starting states of these sub-sequences to the last FSM state arrived at in a single step of the loop in Algorithm 2, we can efficiently index the vocabulary with a map, σ : Q → P(V), connecting FSM states and sets of elements of the vocabulary that will be accepted by the FSM in those states.
Algorithm 4 describes the construction of σ.
Using a hash-map for σ can make the m step in Algorithm 2 cost only O(1) on average. Furthermore, since σ is constructed outside of the token sampling procedure, its run-time cost is effectively irrelevant, although it theoretically requires memory equal to the number of states in the FSM (i.e. |Q|). Fortunately, for non-pathological combinations of regular expressions and vocabularies, not every string in the vocabulary will be accepted by the FSM, and not every FSM state will be represented by a string in V.
3.1 Examples
In this section we use GPT2-medium (355M parameters) to illustrate how regular expression guided generation works in practice. We use the library Outlines to generate them:

Listing 3.1 – continued



Listing 3.3 – continued

3.2 Comparison with current methods
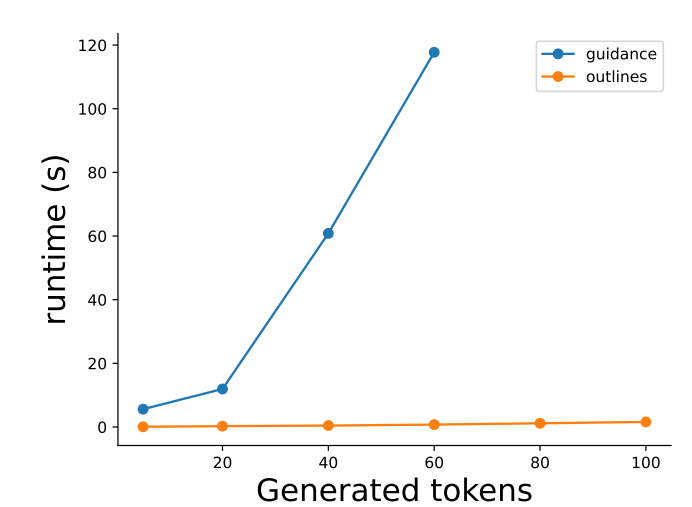
To illustrate the efficiency of the indexing approach described here, and implemented in Outlines, we perform a simple comparison with the Guidance library. As of this writing, the Guidance library uses partial regular expression matching–applied from the start of the sampled sequence each time–and must iterate over the LLM’s vocabulary (N = 50, 257) on each step.
The Guidance code and prompt used for this comparison are as follows:

Listing 3.4 – continued

The corresponding Outlines code is as follows:

Listing 3.5 – continued

The value of max_tokens is varied and the timings are recorded with timeit for a single loop and single repeat value (i.e. only one sample is collected for each value of max_tokens). The results are plotted in Section 3.2.
Barring any configuration oversights that might be creating a large runtime discrepancy, the observed scaling in the maximum number of sampled tokens is striking and is indicative of the growing computational problem implied by the approach.
This paper is available on arxiv under CC 4.0 license.