

This paper is available on arxiv under CC 4.0 license.
Authors: Gemini Team, Google.
Table of Links
Discussion and Conclusion, References
Contributions and Acknowledgments
9. Appendix
9.1. Chain-of-Thought Comparisons on MMLU benchmark
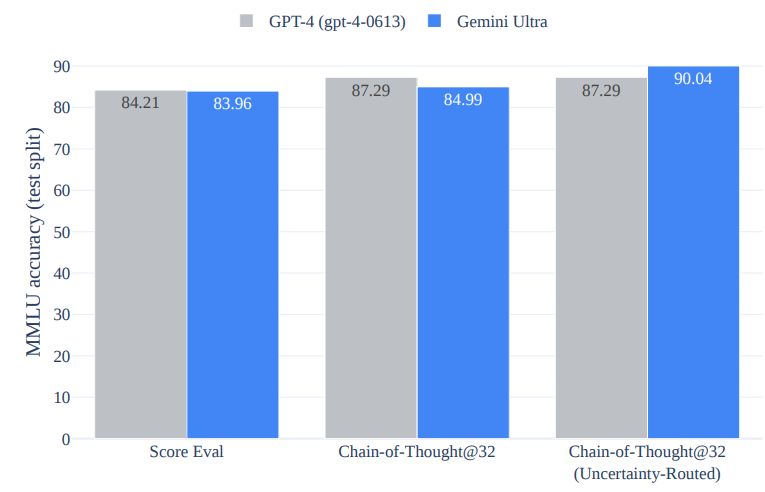
We contrast several chain-of-thought approaches on MMLU and discuss their results in this section. We proposed a new approach where model produces k chain-of-thought samples, selects the majority vote if the model is confident above a threshold, and otherwise defers to the greedy sample choice. The thresholds are optimized for each model based on their validation split performance. The proposed approach is referred to as uncertainty-routed chain-of-thought. The intuition behind this approach is that chain-of-thought samples might degrade performance compared to the maximum-likelihood decision when the model is demonstrably inconsistent. We compare the gains from the proposed approach on both Gemini Ultra and GPT-4 in Figure 7. We find that Gemini Ultra benefits more from this approach compared to using only chain-of-thought samples. GPT-4’s performance improves from 84.2% with greedy sampling to 87.3% with uncertainty-routed chain-of-thought approach with 32 samples, but it already achieves these gains from using 32 chain-of-thought samples. In contrast, Gemini Ultra improves its performance significantly from 84.0% with greedy sampling to 90.0% with uncertainty-routed chain-of-thought approach with 32 samples while it marginally improves to 85.0% with the use of 32 chain-of-thought samples only.
9.2. Capabilities and Benchmarking Tasks
We use more than 50 benchmarks as a holistic harness to evaluate the Gemini models across text, image, audio and video. We provide a detailed list of benchmarking tasks for six different capabilities in text understanding and generation: factuality, long context, math/science, reasoning, summarization, and multilinguality. We also enumerate the benchmarks used for image understanding, video understanding, and audio understanding tasks.
• Factuality: We use 5 benchmarks: BoolQ (Clark et al., 2019), NaturalQuestions-Closed (Kwiatkowski et al., 2019), NaturalQuestions-Retrieved (Kwiatkowski et al., 2019), RealtimeQA (Kasai et al., 2022), TydiQA-noContext and TydiQA-goldP (Clark et al., 2020).
• Long Context: We use 6 benchmarks: NarrativeQA (Kočiský et al., 2018), Scrolls-Qasper, Scrolls-Quality (Shaham et al., 2022), XLsum (En), XLSum (non-English languages) (Hasan et al., 2021), and one other internal benchmark.
• Math/Science: We use 8 benchmarks: GSM8k (with CoT) (Cobbe et al., 2021), Hendryck’s MATH pass@1 (Hendrycks et al., 2021b), MMLU (Hendrycks et al., 2021a), Math-StackExchange, Math-AMC 2022-2023 problems, and three other internal benchmarks.
• Reasoning: We use 7 benchmarks: BigBench Hard (with CoT) (Srivastava et al., 2022; Suzgun et al., 2022), CLRS (Veličković et al., 2022), Proof Writer (Tafjord et al., 2020), Reasoning-Fermi problems (Kalyan et al., 2021), Lambada (Paperno et al., 2016), HellaSwag (Zellers et al., 2019), DROP (Dua et al., 2019).
• Summarization: We use 5 benchmarks: XL Sum (English), XL Sum (non-English languages) (Hasan et al., 2021), WikiLingua (non-English languages), WikiLingua (English) (Ladhak et al., 2020), XSum (Narayan et al., 2018).
• Multilinguality: We use 10 benchmarks: XLSum (Non-English languages) (Hasan et al., 2021), WMT22 (Kocmi et al., 2022), WMT23 (Tom et al., 2023), FRMT (Riley et al., 2023), WikiLingua (Non-English languages) (Ladhak et al., 2020), TydiQA (no context), TydiQA (GoldP) (Clark et al., 2020), MGSM (Shi et al., 2023), translated MMLU (Hendrycks et al., 2021a), NTREX (Federmann et al., 2022), FLORES-200 (Team et al., 2022).
• Image and Video: We use 9 benchmarks for image understanding: MMMU (Yue et al., 2023), TextVQA (Singh et al., 2019), DocVQA (Mathew et al., 2021), ChartQA (Masry et al., 2022), InfographicVQA (Mathew et al., 2022), MathVista (Lu et al., 2023), AI2D (Kembhavi et al., 2016), VQAv2 (Goyal et al., 2017), XM3600 (Thapliyal et al., 2022) for multi-lingual image understanding, and 6 benchmarks for video understanding: VATEX (Wang et al., 2019) for captioning in two different languages, YouCook2 (Zhou et al., 2018), NextQA (Xiao et al., 2021), ActivityNet-QA (Yu et al., 2019), and Perception Test MCQA (Pătrăucean et al., 2023).
• Audio: We use 5 benchmarks including automatic speech recognition (ASR) tasks such as FLEURS (Conneau et al., 2023), VoxPopuli (Wang et al., 2021), Multi-lingual Librispeech (Pratap et al., 2020), and automatic speech translation task such as CoVoST 2 (Wang et al., 2020).
9.3. Qualitative Examples
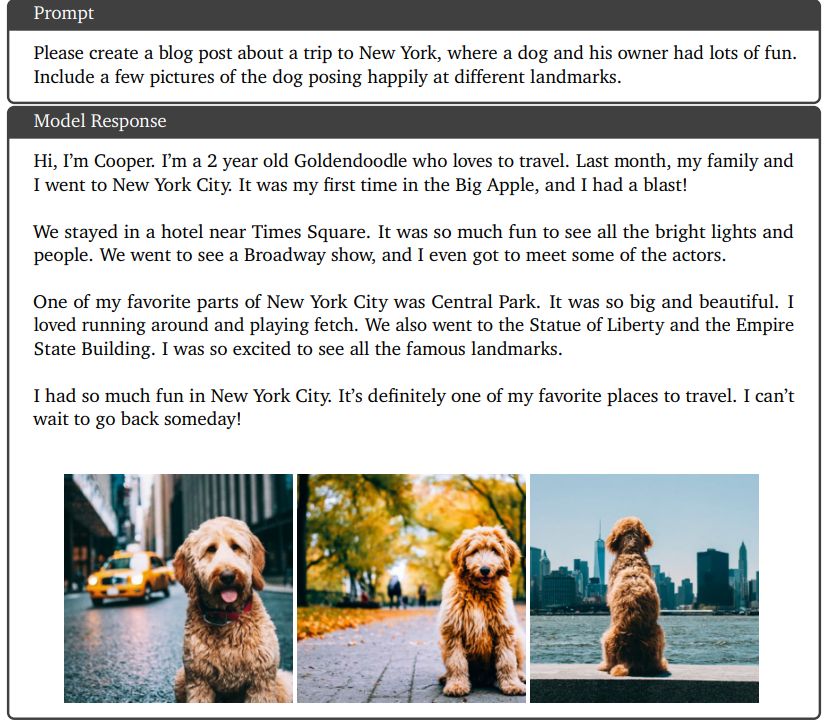
This section shows sample qualitative examples from prompting the Gemini Ultra model. Some illustrative examples of multimodal reasoning for image understanding tasks over charts, natural images and memes are shown in Figures 8, 9, 11, 13, 14, and 15. Figure 10 shows an example of image generation capabilities of Gemini Ultra where the user generates an interleaved sequence of image and text to design a blog post. Beyond English, Figure 16 shows model’s capability to understand images in a multilingual setting. Gemini models also show strong performance on multimodal image understanding and reasoning in mathematics, as shown in Figures 12, 18 and 19. Figure 20 is an example of complex multimodal reasoning demonstrating how the model composes complex image understanding, code generation, and instruction following capabilities for a given user task. In Figure 17, we see another example of the model being able to generate working code and follow complex user instructions. Finally, Figure 21 shows an example of Gemini Ultra’s capability of understanding video by reasoning over temporally connected set of frames.
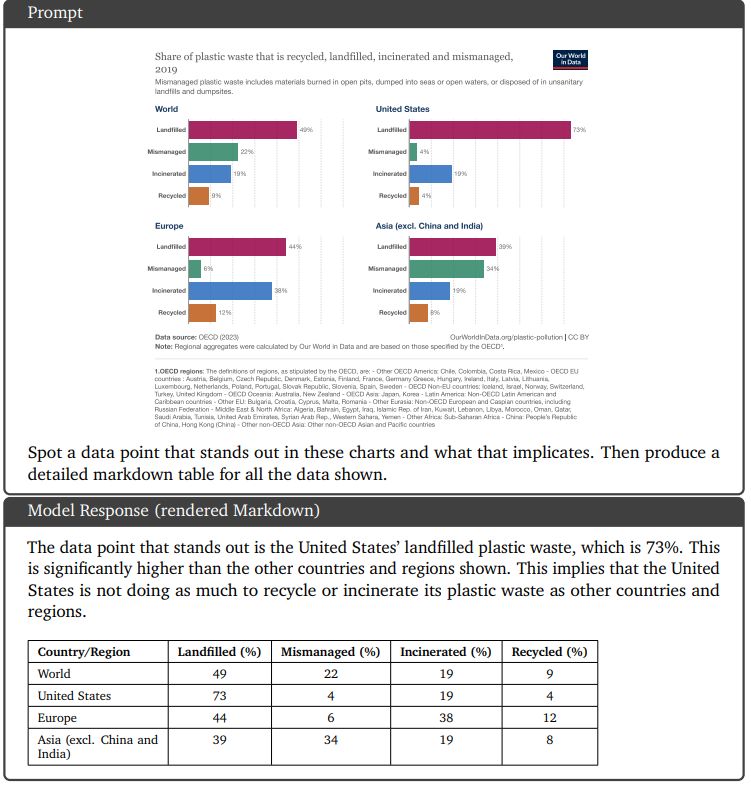
9.3.1. Chart understanding and reasoning over data
9.3.2. Multimodal question answering

9.3.3. Interleaved image and text generation
9.3.4. Image understanding and reasoning

9.3.5. Geometrical reasoning

9.3.6. Information seeking about objects

9.3.7. Multimodal reasoning based on visual cues

9.3.8. Multimodal humor understanding

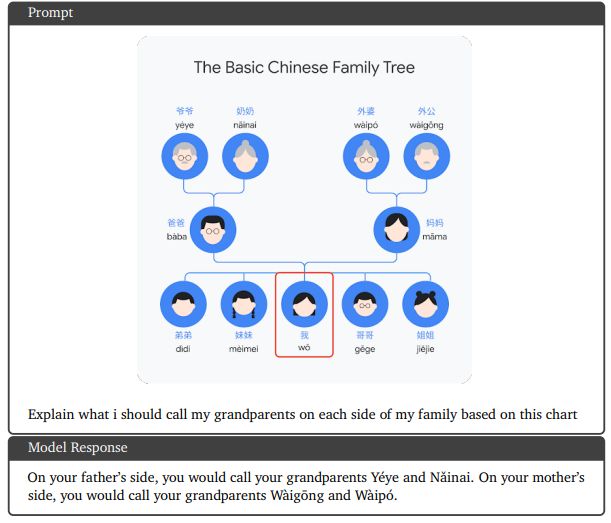
9.4. Commonsense reasoning in a multilingual setting
9.4.1. Reasoning and code generation

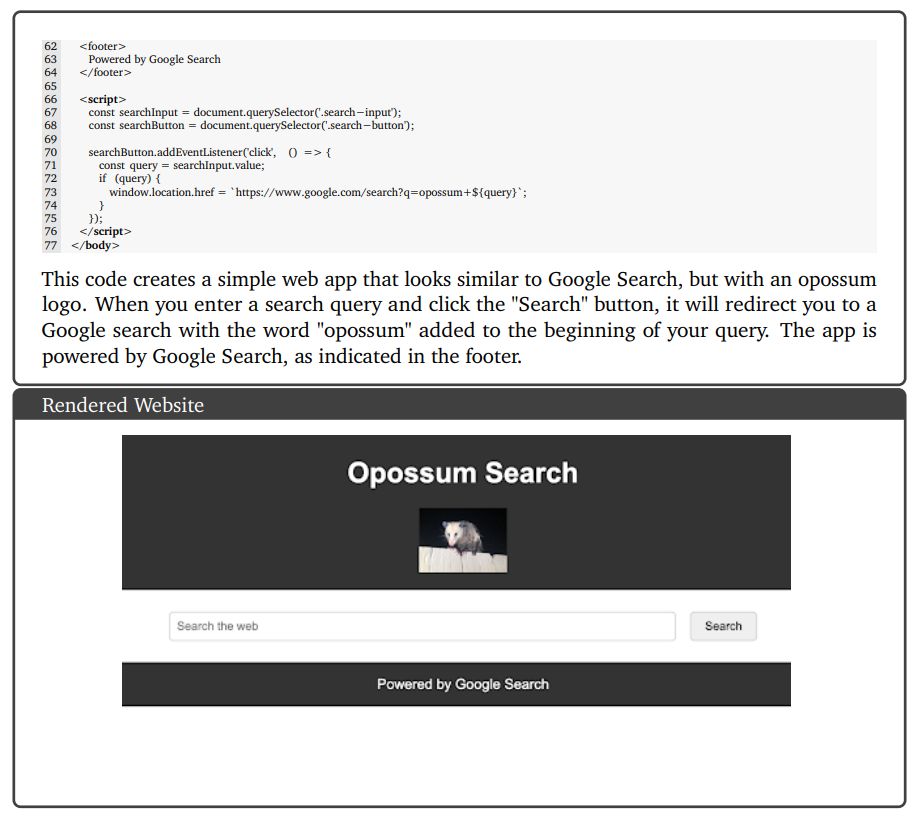
9.4.2. Mathematics: Calculus

9.5. Multi-step reasoning and mathematics
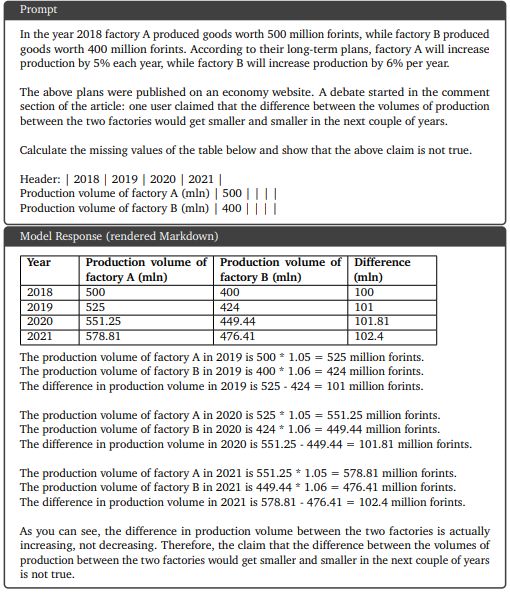
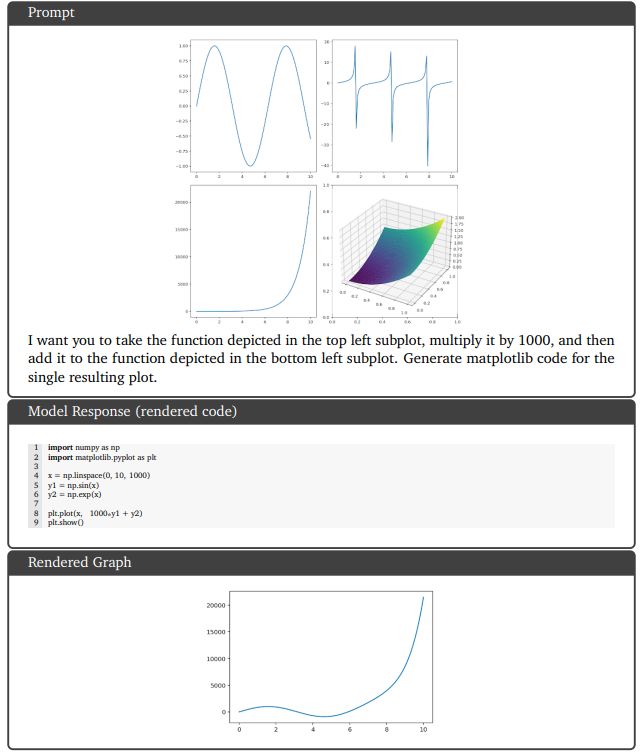
9.5.1. Complex image understanding, code generation, and instruction following
9.5.2. Video understanding and reasoning
