
Authors:
(1) Seokil Ham, KAIST;
(2) Jungwuk Park, KAIST;
(3) Dong-Jun Han, Purdue University;
(4) Jaekyun Moon, KAIST.
Table of Links
3. Proposed NEO-KD Algorithm and 3.1 Problem Setup: Adversarial Training in Multi-Exit Networks
4. Experiments and 4.1 Experimental Setup
4.2. Main Experimental Results
4.3. Ablation Studies and Discussions
5. Conclusion, Acknowledgement and References
B. Clean Test Accuracy and C. Adversarial Training via Average Attack
E. Discussions on Performance Degradation at Later Exits
F. Comparison with Recent Defense Methods for Single-Exit Networks
G. Comparison with SKD and ARD and H. Implementations of Stronger Attacker Algorithms
4.2 Main Experimental Results
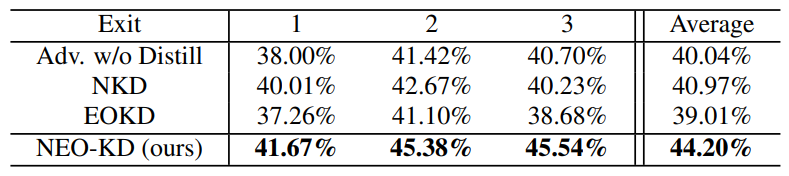
Result 1: Anytime prediction setup. Tables 1, 2, 3, 4, 5 compare the adversarial test accuracy of different schemes under max-average attack and average attack using MNIST, CIFAR-10/100, Tiny-ImageNet, and ImageNet, respectively. Note that we achieve adversarial accuracies between 40% - 50% for CIFAR-10, which is standard considering the prior works on robust multi-exit networks [12]. Our first observation from the results indicates that the performance of SKD [24] is generally lower than that of Adv. w/o Distill, whereas ARD [8] outperforms Adv. w/o Distill. This suggests that the naive application of self-knowledge distillation can either increase or decrease the adversarial robustness of multi-exit networks. Consequently, the method of knowledge distillation
significantly influences the robustness of multi-exit networks (i.e., determining which knowledge to distill and which exit to target). To further enhance robustness, we investigate strategies for distilling high-quality knowledge and mitigating adversarial transferability.
By combining EOKD with NKD to mitigate dependency across submodels while guiding a multi-exit network to extract high quality features from adversarial examples as original data, NEO-KD achieves the highest adversarial test accuracy at most exits compared to the baselines for all datasets/attacks. The overall results confirm the advantage of NEO-KD for robust multi-exit networks.
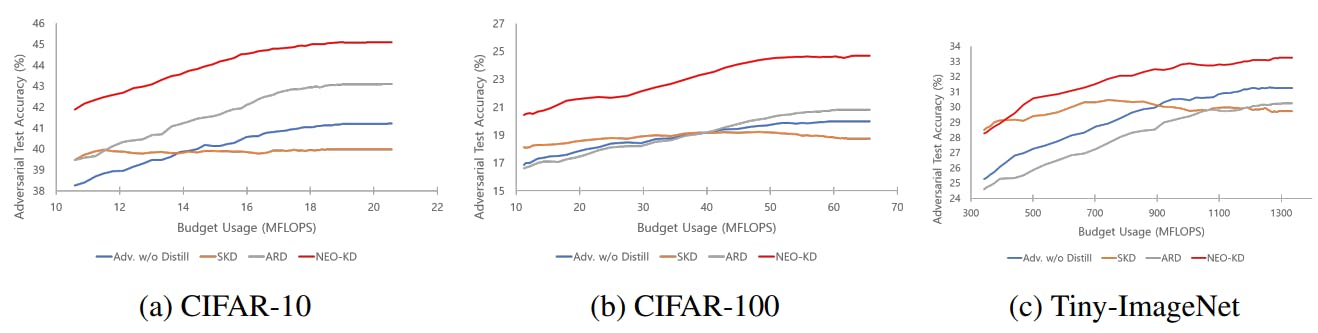
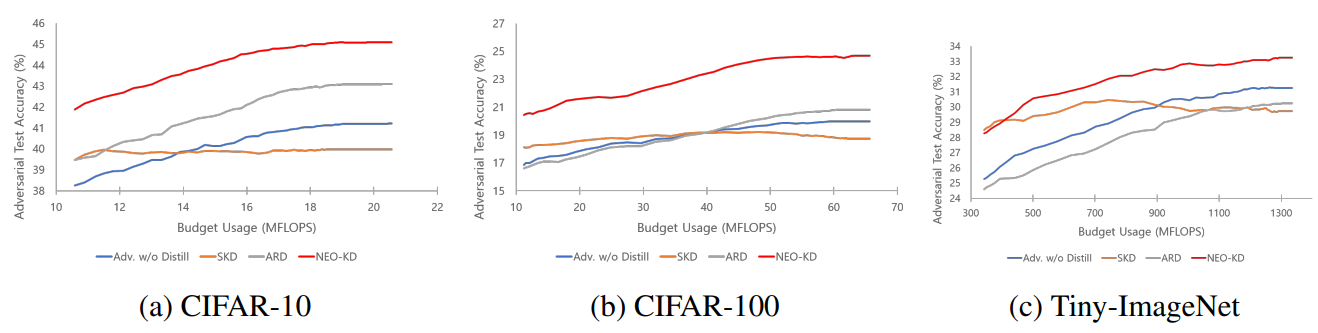
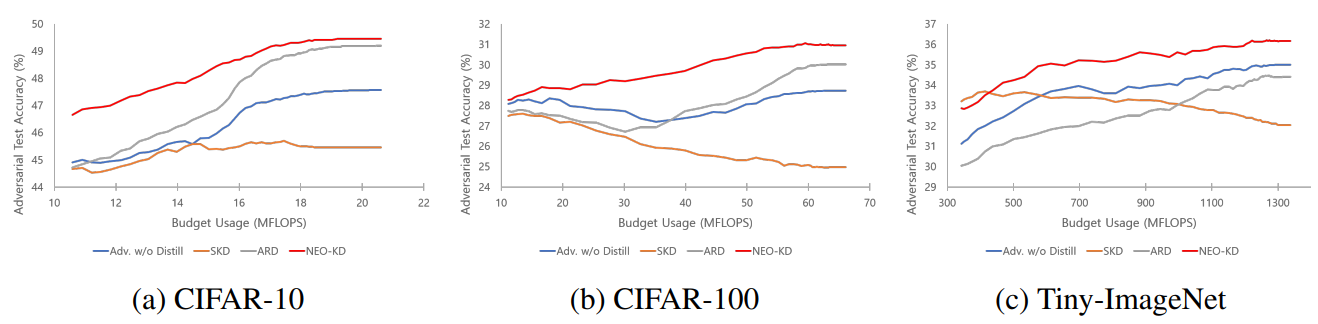
Result 2: Budgeted prediction setup. Different from the anytime prediction setup where the pure performance of each exit is measured, in this setup, we adopt ensemble strategy at inference time where the predictions from the selected exit (according to the confidence threshold) and the previous exits are ensembled. From the results in anytime prediction setup, it is observed that various schemes tend to show low performance at the later exits compared to earlier exits in the model, where more details are discussed in Appendix. Therefore, this ensemble strategy can boost the performance of the later exits. With the ensemble scheme, given a fixed computation budget, we compare adversarial test accuracies of our method with the baselines.
Figures 2 and 3 show the results in budgeted prediction setup under average attack and max-average attack, respectively. NEO-KD achieves the best adversarial test accuracy against both average and max-average attacks in all budget setups. Our scheme also achieves the target accuracy with significantly smaller computing budget compared to the baselines. For example, to achieve 41.21% of accuracy against average attack using CIFAR-10 (which is the maximum accuracy of Adv. w/o Distill), the proposed NEO-KD needs 10.59 MFlops compared to Adv. w/o Distill that requires 20.46 MFlops, saving 48.24% of computing budget. Compared to ARD, our NEO-KD saves 25.27% of computation, while SKD and LW are unable to achieve this target accuracy. For CIFAR-100 and Tiny-ImageNet, NEO-KD saves 81.60% and 50.27% of computing budgets compared to Adv. w/o Distill. The overall results are consistent with the results in anytime prediction setup, confirming the advantage of our solution in practical settings with limited computing budget.
Result 3: Adversarial transferability. We also compare the adversarial transferability of our NEOKD and different baselines among exits in a multi-exit neural network. When measuring adversarial transferability, as in [29], we initially gather all clean test samples for which all exits produce correct predictions. Subsequently, we generate adversarial examples targeting each exit using the collected clean samples (We use PGD-50 based single attack). Finally, we assess the adversarial transferability as the attack success rate of these adversarial examples at each exit. Figure 4 shows the adversarial transferability map of each scheme on CIFAR-100. Here, each row corresponds to the target exit for generating adversarial examples, and each column corresponds the exit where attack success rate is measured. For example, the (i, j)-th element in the map is adversarial transferability measured at exit
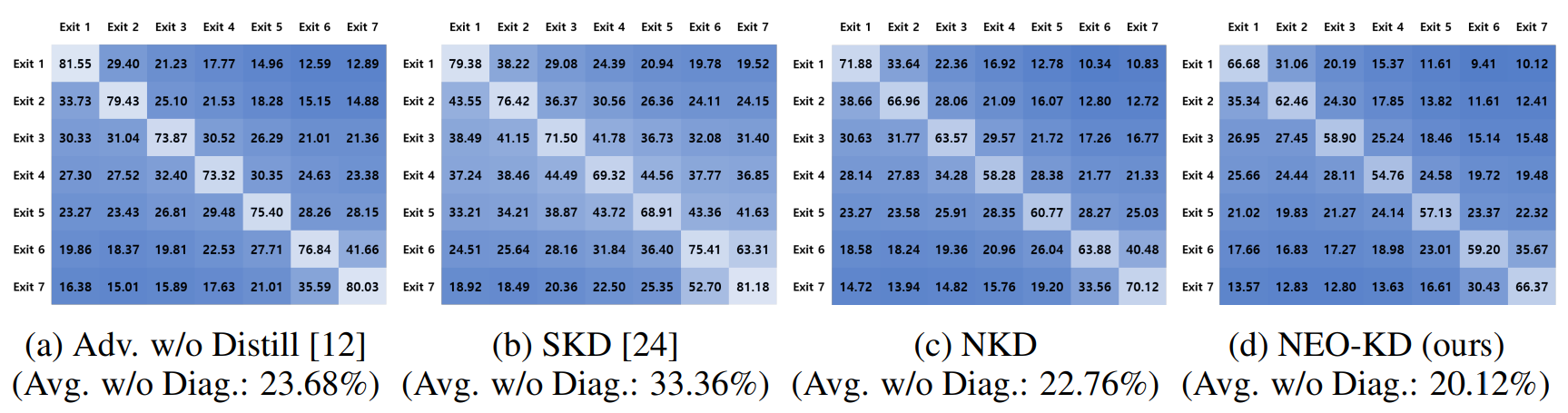

j, generated by the adversarial examples targeting exit i. The values and the brightness in the map indicate success rates of attacks; lower value (dark color) means lower adversarial transferability.
We have the following key observations from adversarial transferability map. First, as observed in Figure 4a, compared to Adv. w/o Distill [12], SKD [24] in Figure 4b exhibits higher adversarial transferability. This indicates that distilling the same teacher prediction to every exit leads to a high dependency across exits. Thus, it is essential to consider distilling non-overlapping knowledge across different exits. Second, when compared to the baselines [12, 24], our proposed NKD in Figure 4c demonstrates low adversarial transferability. This can be attributed to the fact that NKD takes into account the quality of the distilled features and ensures that the features are not overlapping among exits. Third, as seen in Figure 4d, the adversarial transferability is further mitigated by incorporating EOKD, which distills orthogonal class predictions to different exits, into NKD. Comparing the average of attack success rate across all exits (excluding the values of the target exits shown in the diagonal), it becomes evident that NEO-KD yields 3.56% and 13.24% gains compared to Adv. w/o Distill and SKD, respectively. The overall results confirm the advantage of our solution to reduce the adversarial transferability in multi-exit networks. These results support the improved adversarial test accuracy of NEO-KD reported in Section 4.2.
This paper is available on arxiv under CC 4.0 license.