

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jakub DRÁPAL, Institute of State and Law of the Czech Academy of Sciences, Czechia, Institute of Criminal Law and Criminology, Leiden University, the Netherlands;
(2) Hannes WESTERMANN, Cyberjustice Laboratory, Université de Montréal, Canada;
(3) Jaromir SAVELKA, School of Computer Science, Carnegie Mellon University, USA.
Table of Links
Conclusions, Future Work and References
Abstract.
Thematic analysis and other variants of inductive coding are widely used qualitative analytic methods within empirical legal studies (ELS). We propose a novel framework facilitating effective collaboration of a legal expert with a large language model (LLM) for generating initial codes (phase 2 of thematic analysis), searching for themes (phase 3), and classifying the data in terms of the themes (to kick-start phase 4).
We employed the framework for an analysis of a dataset (n = 785) of facts descriptions from criminal court opinions regarding thefts. The goal of the analysis was to discover classes of typical thefts.
Our results show that the LLM, namely OpenAI’s GPT-4, generated reasonable initial codes, and it was capable of improving the quality of the codes based on expert feedback. They also suggest that the model performed well in zero-shot classification of facts descriptions in terms of the themes. Finally, the themes autonomously discovered by the LLM appear to map fairly well to the themes arrived at by legal experts.
These findings can be leveraged by legal researchers to guide their decisions in integrating LLMs into their thematic analyses, as well as other inductive coding projects.
Keywords. Thematic analysis, empirical legal studies, criminal law, large language models, generative pre-trained transformers, GPT-4
1. Introduction
Empirical legal studies (ELS) is an approach to the study of law through empirical methods typical of economics, psychology, and sociology. Since law is a heavily text-based discipline ELS frequently focuses on text analytic methods, including deductive and inductive coding. Deductive coding focuses on applying a fixed set of codes to a dataset, whereas inductive coding leads to a simultaneous discovery of the codes from the data and their application.
While investigations into various methods to support deductive coding have attracted much recent attention in AI & Law [1,2,3] very few studies focused on inductive coding [4]. One popular inductive coding method is “thematic analysis” [5].
J. Drápal, H. Westermann, and J. Savelka / Using LLMs to Support Thematic Analysis in ELS
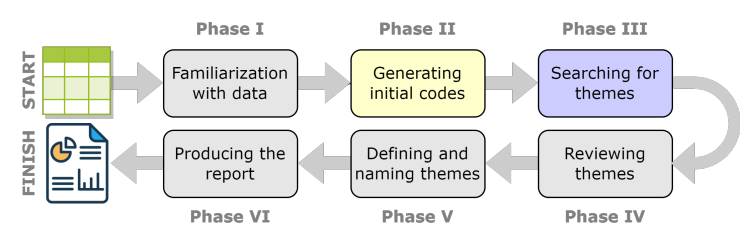
While rarely explicitly acknowledged thematic analysis is widely used in ELS. Figure 1 shows the six phases of the analysis, starting from the raw data and finishing with the scholarly report on the studied phenomena. We propose a novel LLM-powered framework to support a subject matter expert in performing phases 2 and 3 of the analysis.
We employed the proposed framework in a thematic analysis of criminal courts’ opinions, focused on the criminal offense of theft in Czechia. Criminal offense categories (e.g., theft, murder) are usually defined in statutory law while the individual criminal acts are described by courts when they apply the law to factual circumstances of the cases. An important question in criminal law and criminology is what behaviors are actually criminalized and whether it is done appropriately.
Neither the statutory definitions of the offenses (they are too general and not “sociologically relevant” [6]) nor the descriptions of the factual circumstances from cases (too specific) can answer the question.
To get insight into what behavior is criminalized and how effectively, it is necessary to identify shared features of criminal acts, generalize them into “typical crimes” [7,8] and arriving at behavioral-based categories [9,10].
This is akin to performing thematic analysis. While important, such analysis is an expensive and time-consuming endeavour. Hence, a (semi-)automated approach would be useful.
To assess the capability of a state-of-the-art LLM (GPT-4) to support selected stages of the thematic analysis, we investigated the following research questions:
(RQ1) How successfully can the LLM perform initial coding of the data?
(RQ2) To what degree can a subject matter expert improve the quality of the initial codes via natural language feedback?
(RQ3) How successfully can the LLM predict themes for the analyzed data points?
(RQ4) How successfully can the LLM autonomously discover themes and associate them with the analyzed data?
This paper is available on arxiv under CC 4.0 license.