

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(2) Chunyang Chen, Monash University, Melbourne, Australia;
(3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author;
(4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China;
(9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author.
Table of Links
Motivational Study and Background
Discussion and Threats to Validity
3 APPROACH
This paper aims at automatically generating a batch of unusual text inputs which can possibly make the mobile apps crash. The common practice might directly produce the target inputs with LLM as existing studies in valid input generation [44] and fuzzing deep learning libraries [20, 21]. Yet, this would be quite inefficient for our task, because each interaction with the LLM requires a few seconds waiting for the response and consumes lots of energy. Instead, this paper proposes to produce the test generators (a code snippet) with LLM, each of which can generate a batch of unusual text inputs under the same mutation rule (e.g., insert special characters into a string), as demonstrated in Figure 4 ⑤.
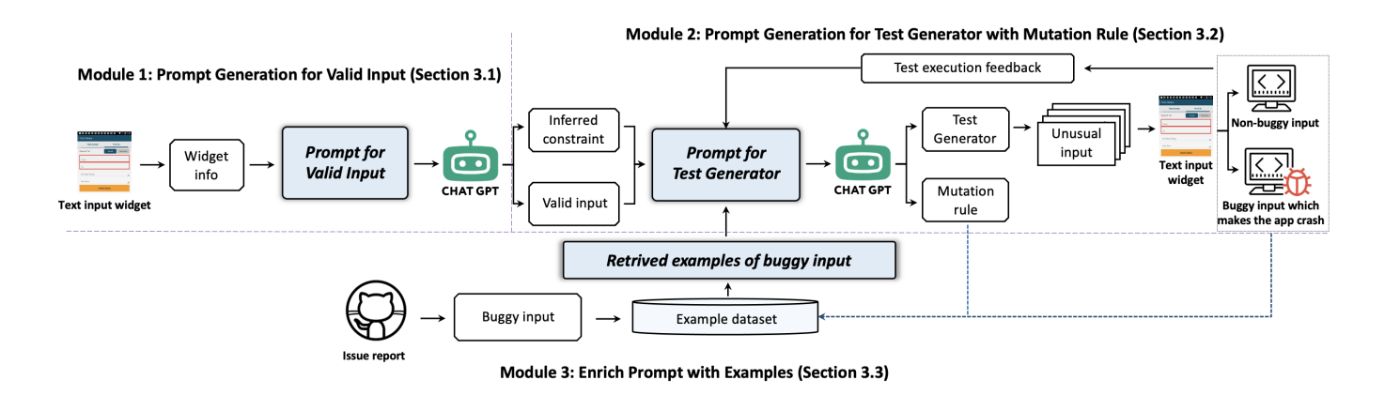
To achieve this, we propose InputBlaster which leverages LLM to produce the test generators together with the mutation rules which serve as the reasoning chains for boosting the performance, and each test generator then automatically generates a batch of unusual text inputs, as shown in Figure 3. In detail, given a GUI page with text input widgets and its corresponding view hierarchy file, we first leverage LLM to generate the valid text input which can pass the GUI page (Sec 3.1). We then leverage LLM to produce the test generator which can generate a batch of unusual text inputs, and simultaneously we also ask the LLM to output the mutation rule which serves as the reasoning chain for guiding the LLM in making the effective mutations from valid inputs (Sec 3.2). To further boost the performance, we utilize the in-context learning schema to provide useful examples when querying the LLM, from online issue reports and historical running records (Sec 3.3).
3.1 Prompt Generation for Valid Input
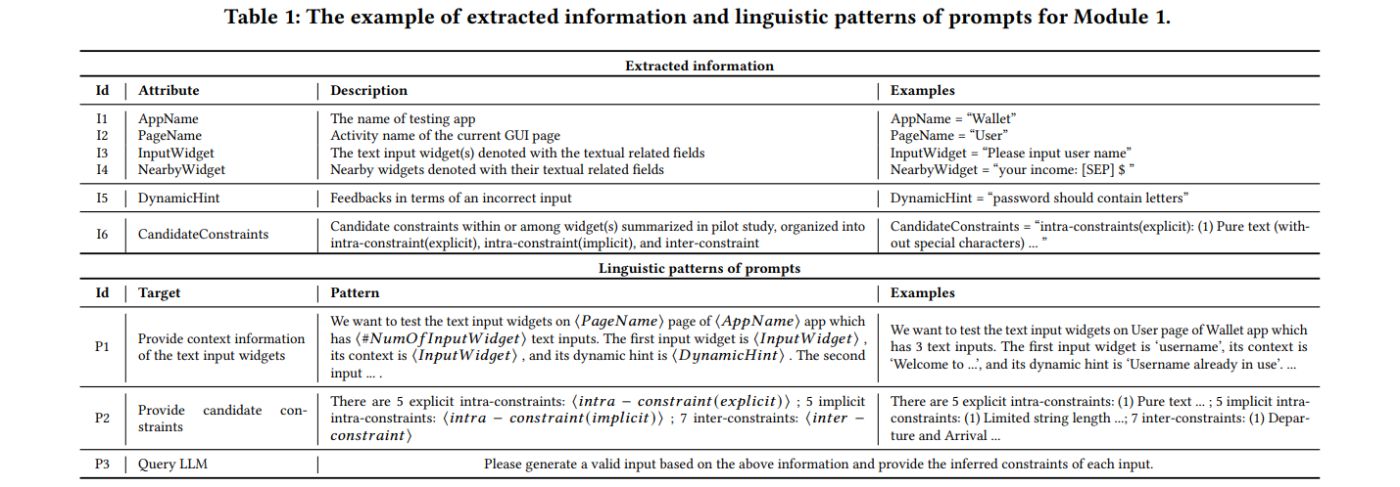
InputBlaster first leverages LLM to generate the valid input which will serve as the target towards which the following mutation can be conducted. The context information relates to the input widgets and its belonged GUI page can provide important clues about what the valid input should be, therefore we input this information into LLM (in Section 3.1.1). In addition, we also include the dynamic feedback information when interacting with the input widgets (in Section 3.1.2), and the constraint categories we summarized in the previous section (in Section 3.1.3) to improve the performance. Furthermore, besides the valid text input, we also ask LLM to output its inferred constraints for generating the valid input which will facilitate the approach to generating the mutation rules in the next section. We summarize all the extracted information with examples in Table 1.
3.1.1 Context Extraction. The context information is extracted from the view hierarchy file, which is easily obtained by automated GUI testing tools [26, 48, 49, 61]. As shown in Table 1, we extract the text-related field of the input widget which indicates how the valid input should be. In detail, we extract the “hint text”, “resource id”, and ‘text’ fields of the input widget, and utilize the first non-empty one among the above three fields.
We also extract the activity name of the GUI page and the mobile app name, and this global context further helps refine the understanding of the input widget. In addition, we extract the local context of the input widget (i.e., from nearby widgets) to provide thorough viewpoints and help clarify the meaning of the widget. The candidate information source includes the parent node widgets, the leaf node widget, widgets in the same horizontal axis, and fragment of the current GUI page. For each information source, we extract the “text” field (if it is empty, use the “resource-id” field), and concatenate them into the natural-language description with the separator (‘;’).
3.1.2 Dynamic Hint Extraction. When one inputs an incorrect text into the app, there are some feedbacks (i.e., dynamic hints) related to the inputs, e.g., the app may alter the users that the password should contain letters and digits. The dynamic hint can further help LLM understand what the valid input should look like.
We extract the dynamic hints via differential analysis which compares the differences of the GUI page before and after inputting the text, and extracts the text field of the newly emerged widgets (e.g., a popup window) in the later GUI page, with examples shown in Figure 2. We also record the text input which makes the dynamic hint happens, which can help the LLM to understand the reason behind it.
3.1.3 Candidate Constraints Preparation. Our pilot study in Section 2.1.2 summarizes the categories of constraints within and among the widgets. The information can provide direct guidance for the LLM in generating the valid inputs, for example, the constraint explicitly requires the input should be pure text (without special characters). We provide this list of all candidate constraints described in natural language as in Section 2.1.2 to the LLM.
3.1.4 Prompt Generation. With the extracted information, we use three kinds of information to generate prompts for inputting into the LLM, as shown in Table 1. Generally speaking, it first provides the context information and the dynamic hints (if any) of the input widgets, followed by the candidate constraints, and then queries the LLM for the valid input. Due to the robustness of LLM, the generated prompt sentence does not need to fully follow the grammar.
After inputting the prompt, the LLM will return its recommended valid text input and its inferred constraints, as demonstrated in Figure 4 ②. We then input it into the widget, and check whether it can make the app transfer to the new GUI page (i.e., valid input). If the app fails to transfer, we iterate the process until the valid input is generated.
3.2 Prompt Generation for Test Generator with Mutation Rule
Based on the valid input in the previous section, InputBlaster then leverages LLM to produce the test generator together with the mutation rule. As demonstrated in Figure 4 ⑤, the test generator is a code snippet that can generate a batch of unusual inputs, while the mutation rule is the natural language described operation for mutating the valid inputs which automatically output by LLM based on our prompt and serves as the reasoning chain for producing the test generator. Note that the mutation rule here is output by LLM.
Each time when a test generator is produced, we can obtain a batch of automatically generated unusual text inputs, and will input them into the text widgets to check whether they have successfully made the mobile app crash. This test execution feedback (in Section 3.2.2) will be incorporated in the prompt for querying the LLM which can enable it more familiar with how the mutation works and potentially produce more diversified outcomes. We also include the inferred constraints in the previous section in the prompt (in Section 3.2.1), since the natural language described explanation would facilitate the LLM in producing effective mutation rules, for example, the inferred constraint is that the input should be in pure text (without special characters) and the LLM would try to insert certain characters to violate the constraint.
3.2.1 Inferred Constraints and Valid Input Extraction. We have obtained the inferred constraints and valid input from the output of the LLM in the previous section, here we extract this information from the output message and will input it into the LLM in this section. We design a flexible keyword matching method to automatically extract the description between the terms like ‘constraints’ and ‘the input’ and treat it as the inferred constraints, and extract the description after the terms like ‘input is’ and treat it as the valid input, as demonstrated in Figure 4 ②.
3.2.2 Test Execution Feedback Extraction. After generating the unusual text inputs, we input them into the mobile app and check whether they can successfully trigger the app crash. This test execution information will be inputted into the LLM to generate more effective and diversified text inputs. We use the real buggy text inputs and the other unusual inputs (which don’t trigger bugs) to prompt LLM in the follow-up generation. The former can remind the LLM to avoid generating duplicate ones, while the latter aims at telling the LLM to consider other mutation rules.
Besides, we also associate the mutation rules with the text input to enable the LLM to better capture its semantic meaning. As shown in Figure 4 ⑤, we extract the content between the keywords “Mutation rule” and “Test generator” as mutation rules.
3.2.3 Prompt Generation. With the extracted information, we design linguistic patterns of the prompt for generating the test generator and mutation rules. As shown in Figure 4 ④, the prompt includes four kinds of information, namely inferred constraints, valid input, text execution feedback, and question. The first three kinds of information are mainly based on the extracted information as described above, and we also add some background illustrations to let the LLM better understand the task, like the inferred constraint in Figure 4 ④. For the question, we first ask the LLM to generate the mutation rule for the valid input, then let it produce a test generator following the mutation rule. Due to the robustness of LLM, the generated prompt sentence does not need to follow the grammar completely.
3.3 Enriching Prompt with Examples
It is usually difficult for LLM to perform well on domain-specific tasks as ours, and a common practice would be employing the in-context learning schema to boost the performance. It provides the LLM with examples to demonstrate what the instruction is, which enables the LLM better understand the task. Following the schema, along with the prompt for the test generator as described in Section 3.2, we additionally provide the LLM with examples of the unusual inputs. To achieve this, we first build a basic example dataset of buggy inputs (which truly trigger the crash) from the issue reports of open-source mobile apps, and continuously enlarge it with the running records during the testing process (in Section 3.3.1). Based on the example dataset, we design a retrieval-based example selection method (in Section 3.3.2) to choose the most suitable examples in terms of an input widget, which further enables the LLM to learn with pertinence.
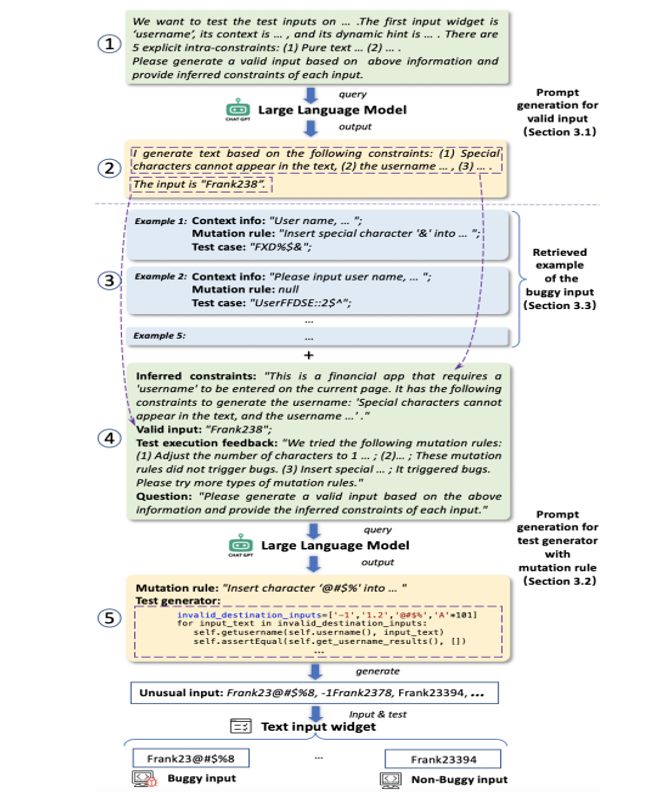
3.3.1 Example Dataset Construction. We collect the buggy text inputs from GitHub and continuously build an example dataset that serves as the basis for in-context learning. For each data instance, as demonstrated in 4 ③, it records the buggy text inputs and the mutation rules which facilitate the LLM understanding of how the buggy inputs come from. It also includes the context information of the input widgets which provides the background information of the buggy inputs, and enables us to select the most suitable examples when querying the LLM.
Mining buggy text inputs from GitHub. First, we automatically crawl the issue reports and pull requests from the Android mobile apps in GitHub (updated before September 2022). Then we use keyword matching to filter these related to the text inputs (e.g., EditText) and have triggered crashes. Following that, we then employ manual checking to further determine whether there is a crash triggered by the buggy text inputs by running the app. In this way, we obtain 50 unusual inputs and store them in the example dataset (There is no overlap with the evaluation datasets.). We then extract the context information of the input widget with the method in Section 3.1.1, and store it together with the unusual input. Note that, since these buggy inputs don’t associate with the mutation rules, we set them as null.
Enlarging the dataset with buggy text inputs during testing. We enrich the example dataset with the newly emerged unusual text inputs which truly trigger bugs during InputBlaster runs on
various apps. Specifically, for each generated unusual text input, after running it in the mobile apps, we put the ones which trigger crashes into the example dataset. We also add their associated mutation rules generated by the LLM, as well as the context information extracted in Section 3.1.1.
3.3.2 Retrieval-based Example Selection and In-context Learning. Examples can provide intuitive guidance to the LLM in accomplishing a task, yet excessive examples might mislead the LLM and cause the performance to decline. Therefore, we design a retrieval based example selection method to choose the most suitable examples (i.e., most similar to the input widgets) for LLM.
In detail, the similarity comparison is based on the context information of the input widgets. We use Word2Vec (Lightweight word embedding method) [50] to encode the context information of each input widget into a 300-dimensional sentence embedding, and calculate the cosine similarity between the input widget and each data instance in the example dataset. We choose the top-K data instance with the highest similarity score, and set K as 5 empirically.
The selected data instances (i.e., examples) will be provided to the LLM in the format of context information, mutation rule, and buggy text input, as demonstrated in Figure 4 ③.
3.4 Implementation
We implement InputBlaster based on the ChatGPT which is released on the OpenAI website[3]. It obtains the view hierarchy file of the current GUI page through UIAutomator [65] to extract context information of the input widgets. InputBlaster can be integrated by replacing the text input generation module of the automated GUI testing tool, which automatically extracts the context information and generates the unusual inputs.
[3] https://beta.openai.com/docs/models/chatgpt