

Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
2.3 Sentence Variational Autoencoder
Variational autoencoders are models that combine latent-variable modeling and neural networks. As a type of variational autoencoders, sentence variational autoencoders (SVAEs) seek to model a sentence through latent variables. The use of latent variables allows for design choices that reflect certain aspects of a sentence: e.g., sentiment and formality, leading to controllable and interpretable neural architectures. Below we briefly review the related work.
2.3.1 Related Work
SVAEs with a single latent variable often assumes that the latent variable follows Gaussian distributions, where researchers primarily focus on improving the SVAEs capabilities in language modeling (as measured by perplexities) and generating from interpolated samples from latent distributions (Bowman et al., 2016). Relevant work studies the effect of different latent distributions, including von Mises-Fisher distributions (Xu and Durrett, 2018), Gaussian mixtures (Ding and Gimpel, 2021), Gumbel-softmax distributions (Zhou and Neubig, 2017), discrete variables (Wiseman et al., 2018; Deng et al., 2018; Ziegler and Rush, 2019; Stratos and Wiseman, 2020; Jin et al., 2020a), piecewise constant distributions (Serban et al., 2017), samplebased (Fang et al., 2019) and flow-based distributions (Ma et al., 2019; Setiawan et al., 2020; Ding and Gimpel, 2021).
Apart from language modeling, researchers have used SVAEs for machine translations (Zhang et al., 2016; Schulz et al., 2018; Eikema and Aziz, 2019; Ma et al., 2019; Calixto et al., 2019; Setiawan et al., 2020), relation extraction (Marcheggiani and Titov, 2016), dependency parsing (Corro and Titov, 2019), word representations (Rios et al., 2018), dialogue generation (Shen et al., 2017b; Bahuleyan et al., 2018; Shen et al., 2018b), text classification (Ding and Gimpel, 2019; Gururangan et al., 2019; Jin et al., 2020a), and question generation (Bahuleyan et al., 2018). Increasing attention has also been devoted to interpretable representation learning (Bastings et al., 2019; Zhou et al., 2020; Goyal et al., 2020; Cheng et al., 2020; Mercatali and Freitas, 2021; Vishnubhotla et al., 2021) and controllable generation (e.g., controling sentiment (Hu et al., 2017; Shen et al., 2017a) or formality (Ficler and Goldberg, 2017)).
2.3.2 Formal Preliminaries
Below we derive the training objectives for sentence variational autoencoders using Gaussian and vMF distributions. These materials will be used in Section 5.1 and Section 5.2.

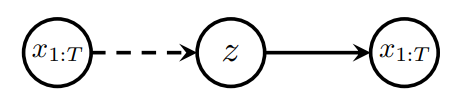

where KL divergence is a distance measure between two probability distributions (Kullback and Leibler, 1951) and we have introduced the variational posterior q parametrized by new parameters φ. q is referred to as an “inference model” as it encodes an input into the latent space. We also have the generative model probabilities p parametrized by θ. The parameters are trained in a way that reflects a classical autoencoder framework: encode the input into a latent space, decode the latent space to reconstruct the input. These models are therefore referred to as “variational autoencoders”.
The lower bound (also known as the evidence lower bound (ELBO)) consists of two terms: reconstruction loss and KL divergence. The KL divergence term provides a regularizing effect during learning by ensuring that the learned posterior remains close to the prior over the latent variables.


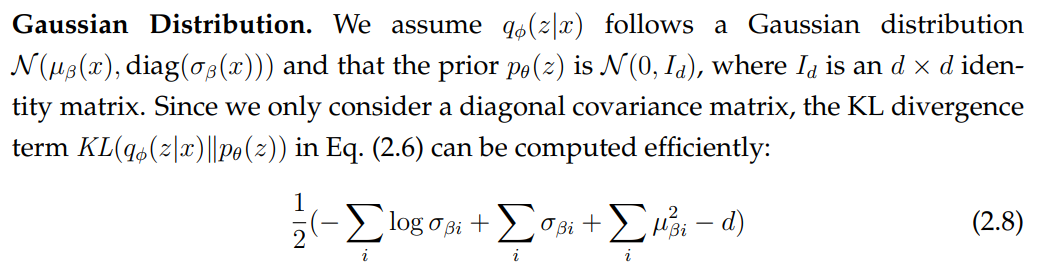
This paper is available on arxiv under CC 4.0 license.