

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Ke Hong, Tsinghua University & Infinigence-AI;
(2) Guohao Dai, Shanghai Jiao Tong University & Infinigence-AI;
(3) Jiaming Xu, Shanghai Jiao Tong University & Infinigence-AI;
(4) Qiuli Mao, Tsinghua University & Infinigence-AI;
(5) Xiuhong Li, Peking University;
(6) Jun Liu, Shanghai Jiao Tong University & Infinigence-AI;
(7) Kangdi Chen, Infinigence-AI;
(8) Yuhan Dong, Tsinghua University;
(9) Yu Wang, Tsinghua University.
Table of Links
- Abstract & Introduction
- Backgrounds
- Asynchronized Softmax with Unified Maximum Value
- Flat GEMM Optimization with Double Buffering
- Heuristic Dataflow with Hardware Resource Adaption
- Evaluation
- Related Works
- Conclusion & References
2 Backgrounds
2.1 LLM Inference Dataflow Overview
The task of LLM inference is to generate tokens from the input sequence, which can be used to complete a sentence or answer a question. An overview of the LLM inference dataflow is shown in Figure 2. As we can see, the LLM inference dataflow can be organized into two typical phases with similar operations: one prefill phase and several decode phases. The prefill phase “understands" the input sequence (i.e., “What is the largest ocean?”). Each token (we set one word as a token in Figure 2 is encoded as an embedding vector, and the input sequence is organized into a matrix. The main output of the prefill phase is a new token, which is predicted to be the next token after the input sequence (i.e., “Pacific" in this figure). The decode phase “generates" the output sequence (i.e., “Pacific”, “Ocean", etc.) The output token of the prefill phase is taken as the input of the decode phase. The decode phase is executed autogressively, and each output token is used as the input token for the next The decode (e.g., “Ocean" is further used as the input).
2.2 Operations in LLM Inference
The main operations in LLM inference are depicted as operation ① to ⑥ in Figure 2, including the linear projection (① and ⑤), the attention (②, ③, and ④), and the feedforward network (⑥). For simplicity, operations like position embedding [26], non-linear activation [27, 28, 29], mask [26], and others are not shown in the figure. Operations in the prefill phase and the decode phase are different in the shape of data. Because only one token (batch size=1) or few tokens (batch size>1) are processed at one time, input matrices in the decode phase are flat-shape matrices or even vectors.
Linear Projection. The linear projection performs as the fully connected layer, multiplying the input with weight matrices (i.e., WK, WQ, WV , WO, called K, Q, V projection and O projection). For the prefill phase, the K, Q, V projection generates matrices K, Q, V . For the decode phase, the K, Q, V projection generates three corresponding vectors and concatenated with K and V (i.e., KVcache, yellow and light blue in Figure 2 in the prefill phase.
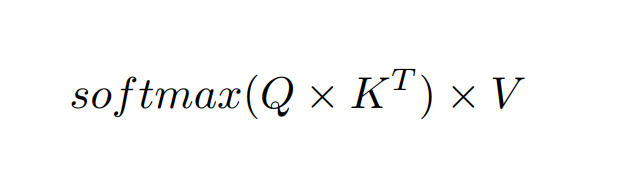

Attention. The attention operation is mainly divided into three operations (② to ④ Q × K, sof tmax, Attention × V ), as shown in Eq. (1). For P = Q × KT , the softmax operation is performed for each row of the result matrix of P. The detailed softmax computation is shown in Figure 4(a). The maximum value m(x) is first calculated. The exponent of each element divided by e m(x) , f(x), is then processed. These exponents are normalized to the summation of all exponents (i.e., l(x)) to get the softmax result.
Feedforward Network. The feedforward network primarily comprises two fully connected layers. The first one (⑥ F F N1) expands the feature dimensions to enhance the representational capacity. The second one (⑥ F F N2) restores the feature dimensions and serves as the output layer.
2.3 Attention Optimization
The softmax operation shown in Figure 4(a) requires all global data to be calculated and stored before it can proceed. This results in high memory consumption and low parallelism. Latter works propose the partial softmax technique to reduce memory consumption [18, 19] or improve parallelism [13]. Figure 4(b) shows the diagram of the partial softmax operation. The main idea is to divide the vector x into partial vectors (i.e, x ′ and x ′′). The partial softmax results of x ′ and x ′′ are calculated separately according to Figure 4(a), and then synchronously updated by each other. The detailed computation of this synchronized update is shown in Equation (2). With the implementation of partial softmax, we can achieve efficient parallelism of computation while reducing memory cost for attention computation.
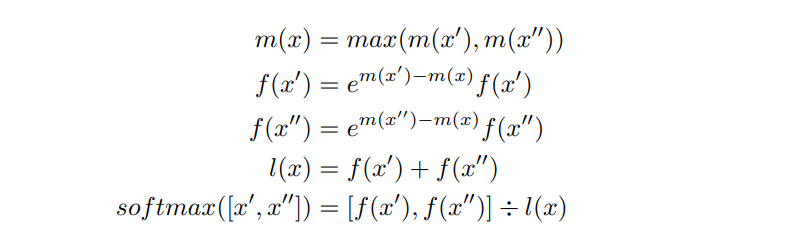
However, since the partial softmax needs to be updated according to other partial softmax results, it unavoidably introduces data synchronization operations. According to our profiling result, such a synchronized update operation leads to 18.8% overheads in the attention computation for Llama2-7B inference on NVIDIA Tesla A100 GPU with 1024 input length.