

This paper is available on arxiv under CC 4.0 license.
Authors: Gemini Team, Google.
Table of Links
Discussion and Conclusion, References
Contributions and Acknowledgments
5. Evaluation
The Gemini models are natively multimodal, as they are trained jointly across text, image, audio, and video. One open question is whether this joint training can result in a model which has strong capabilities in each domain – even when compared to models and approaches that are narrowly tailored to single domains. We find this to be the case: Gemini sets a new state of the art across a wide range of text, image, audio, and video benchmarks.
5.1. Text
5.1.1. Academic Benchmarks
We compare Gemini Pro and Ultra to a suite of external LLMs and our previous best model PaLM 2 across a series of text-based academic benchmarks covering reasoning, reading comprehension, STEM, and coding. We report these results in Table 2. Broadly, we find that the performance of Gemini Pro outperforms inference-optimized models such as GPT-3.5 and performs comparably with several of the most capable models available, and Gemini Ultra outperforms all current models. In this section, we examine some of these findings.
On MMLU (Hendrycks et al., 2021a), Gemini Ultra can outperform all existing models, achieving an accuracy of 90.04%. MMLU is a holistic exam benchmark, which measures knowledge across a set of 57 subjects. Human expert performance is gauged at 89.8% by the benchmark authors, and Gemini Ultra is the first model to exceed this threshold, with the prior state-of-the-art result at 86.4%. Achieving high performance requires specialist knowledge across many domains (e.g. law, biology, history, etc.), alongside reading comprehension and reasoning. We find Gemini Ultra achieves highest accuracy when used in combination with a chain-of-thought prompting approach (Wei et al., 2022) that accounts for model uncertainty. The model produces a chain of thought with k samples, for example 8 or 32. If there is a consensus above a preset threshold (selected based on the validation split), it selects this answer, otherwise it reverts to a greedy sample based on maximum likelihood choice without chain of thought. We refer the reader to appendix for a detailed breakdown of how this approach compares with only chain-of-thought prompting or only greedy sampling.
In mathematics, a field commonly used to benchmark the analytical capabilities of models, Gemini Ultra shows strong performance on both elementary exams and competition-grade problem sets. For the grade-school math benchmark, GSM8K (Cobbe et al., 2021), we find Gemini Ultra reaches 94.4% accuracy with chain-of-thought prompting and self-consistency (Wang et al., 2022) compared to the previous best accuracy of 92% with the same prompting technique. Similar positive trends are observed in increased difficulty math problems drawn from middle- and high-school math competitions (MATH benchmark), with the Gemini Ultra model outperforming all competitor models, reaching 53.2% using 4-shot prompting. The model also outperforms the state of the art on even harder tasks derived from American Mathematical Competitions (150 questions from 2022 and 2023). Smaller models perform poorly on this challenging task scoring close to random, but Gemini Ultra can solve 32% of the questions, compared to the 30% solve rate for GPT-4.
Gemini Ultra also excels in coding, a popular use case of current LLMs. We evaluate the model on many conventional and internal benchmarks and also measure its performance as part of more complex reasoning systems such as AlphaCode 2 (see section 5.1.7 on complex reasoning systems). For example, on HumanEval, a standard code-completion benchmark (Chen et al., 2021) mapping function descriptions to Python implementations, instruction-tuned Gemini Ultra correctly implements 74.4% of problems. On a new held-out evaluation benchmark for python code generation tasks, Natural2Code, where we ensure no web leakage, Gemini Ultra achieves the highest score of 74.9%.
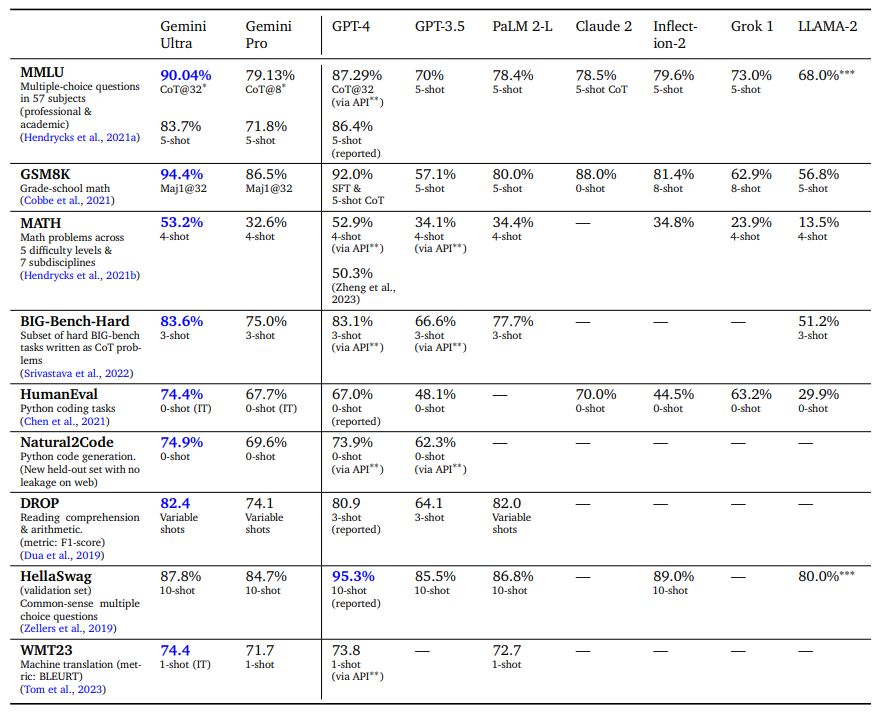
Evaluation on these benchmarks is challenging and may be affected by data contamination. We performed an extensive leaked data analysis after training to ensure the results we report here are as scientifically sound as possible, but still found some minor issues and decided not to report results on e.g. LAMBADA (Paperno et al., 2016). As part of the evaluation process, on a popular benchmark, HellaSwag (Zellers et al., 2019), we find that an additional hundred finetuning steps on specific website extracts corresponding to the HellaSwag training set (which were not included in Gemini pretraining set) improve the validation accuracy of Gemini Pro to 89.6% and Gemini Ultra to 96.0%, when measured with 1-shot prompting (we measured GPT-4 obtained 92.3% when evaluated 1-shot via the API). This suggests that the benchmark results are susceptible to the pretraining dataset composition. We choose to report HellaSwag decontaminated results only in a 10-shot evaluation setting. We believe there is a need for more robust and nuanced standardized evaluation benchmarks with no leaked data. So, we evaluate Gemini models on several new held-out evaluation datasets that were recently released, such as WMT23 and Math-AMC 2022-2023 problems, or internally generated from non-web sources, such as Natural2Code. We refer the reader to the appendix for a comprehensive list of our evaluation benchmarks.
Even so, model performance on these benchmarks gives us an indication of the model capabilities and where they may provide impact on real-world tasks. For example, Gemini Ultra’s impressive reasoning and STEM competencies pave the way for advancements in LLMs within the educational domain[4]. The ability to tackle complex mathematical and scientific concepts opens up exciting possibilities for personalized learning and intelligent tutoring systems.
5.1.2. Trends in Capabilities
We investigate the trends in capabilities across the Gemini model family by evaluating them on a holistic harness of more than 50 benchmarks in six different capabilities, noting that some of the most notable benchmarks were discussed in the last section. These capabilities are: “Factuality” covering open/closed-book retrieval and question answering tasks; “Long-Context” covering longform summarization, retrieval and question answering tasks; “Math/Science” including tasks for mathematical problem solving, theorem proving, and scientific exams; “Reasoning” tasks that require arithmetic, scientific, and commonsense reasoning; “Multilingual” tasks for translation, summarization, and reasoning in multiple languages. Please see appendix for a detailed list of tasks included for each capability.
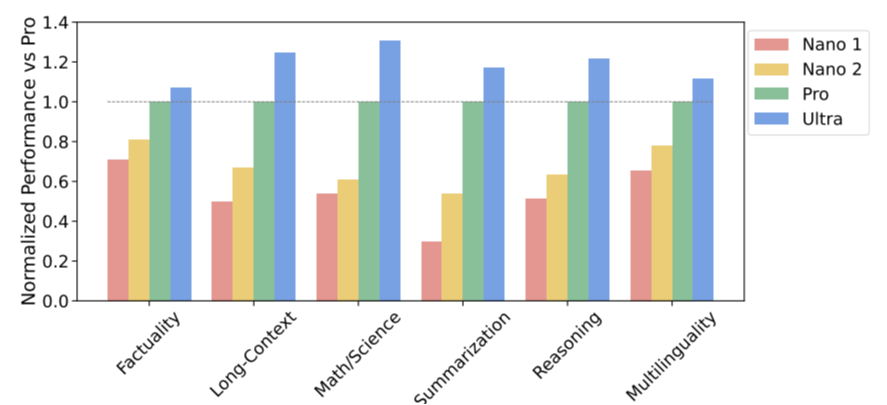
We observe consistent quality gains with increased model size in Figure 3, especially in reasoning, math/science, summarization and long-context. Gemini Ultra is the best model across the board for all six capabilities. Gemini Pro, the second-largest model in the Gemini family of models, is also quite competitive while being a lot more efficient to serve.
5.1.3. Nano
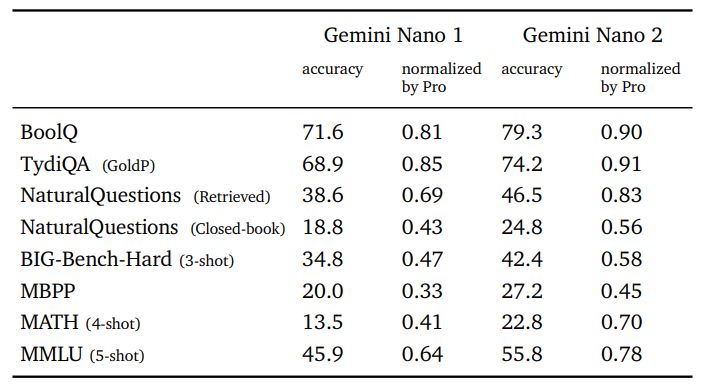
Bringing AI closer to the user, we discuss the Gemini Nano 1 and Nano 2 models engineered for on-device deployments. These models excel in summarization and reading comprehension tasks with per-task finetuning. Figure 3 shows the performance of these pretrained models in comparison to the much larger Gemini Pro model, while Table 3 dives deeper into specific factuality, coding, Math/Science, and reasoning tasks. Nano-1 and Nano-2 model sizes are only 1.8B and 3.25B parameters respectively. Despite their size, they show exceptionally strong performance on factuality, i.e. retrieval-related tasks, and significant performance on reasoning, STEM, coding, multimodal and multilingual tasks. With new capabilities accessible to a broader set of platforms and devices, the Gemini models expand accessibility to everyone.
5.1.4. Multilinguality
The multilingual capabilities of the Gemini models are evaluated using a diverse set of tasks requiring multilingual understanding, cross-lingual generalization, and the generation of text in multiple languages. These tasks include machine translation benchmarks (WMT 23 for high-medium-low resource translation; Flores, NTREX for low and very low resource languages), summarization benchmarks (XLSum, Wikilingua), and translated versions of common benchmarks (MGSM: professionally translated into 11 languages).
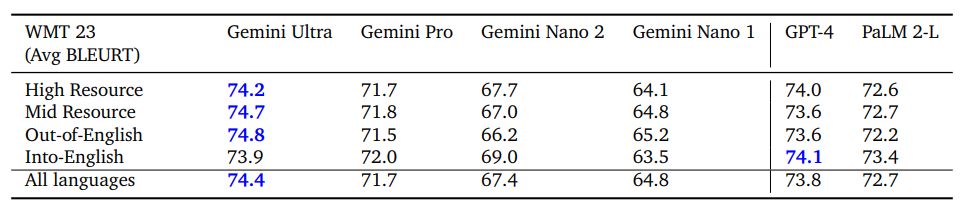
Machine Translation Translation is a canonical benchmark in machine learning with a rich history. We evaluated Gemini Ultra with instruction-tuning applied (see section 6.4.2) on the entire set of language pairs in the WMT 23 translation benchmark in a few-shot setting. Overall, we found that Gemini Ultra (and other Gemini models) performed remarkably well at translating from English to any other language, and surpassed the LLM-based translation methods when translating out-of-English, on high-resource, mid-resource and low-resource languages. In the WMT 23 out-of-English translation tasks, Gemini Ultra achieved the highest LLM-based translation quality, with an average BLEURT (Sellam et al., 2020) score of 74.8, compared to GPT-4’s score of 73.6, and PaLM 2’s score of 72.2. When averaged across all language pairs and directions for WMT 23, we see a similar trend with Gemini Ultra 74.4, GPT-4 73.8 and PaLM 2-L 72.7 average BLEURT scores on this benchmark.
In addition to the languages and translation tasks above, we also evaluate Gemini Ultra on very low-resource languages. These languages were sampled from the tail of the following language sets: Flores-200 (Tamazight and Kanure), NTREX (North Ndebele), and an internal benchmark (Quechua).
For these languages, both from and into English, Gemini Ultra achieved an average chrF score of 27.0 in 1-shot setup, while the next-best model, PaLM 2-L, achieved a score of 25.3.
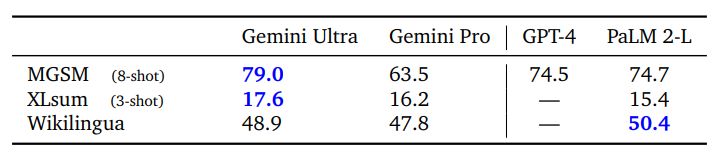
Multilingual Math and Summarization Beyond translation, we evaluated how well Gemini performs in challenging tasks across a range of languages. We specifically investigated the math benchmark MGSM (Shi et al., 2023), which is a translated variant of the math benchmark GSM8K (Cobbe et al., 2021). We find Gemini Ultra achieves an accuracy of 79.0%, an advance over PaLM 2-L which scores 74.7%, when averaged across all languages in an 8-shot setup. We also benchmark Gemini on the multilingual summarization benchmarks – XLSum (Hasan et al., 2021) and WikiLingua (Ladhak et al., 2020). In XLSum, Gemini Ultra reached an average of 17.6 rougeL score compared to 15.4 for PaLM 2. For Wikilingua, Gemini Ultra (5-shot) trails behind PaLM 2 (3-shot) measured in BLEURT score. See Table 5 for the full results. Overall the diverse set of multilingual benchmarks show that Gemini family models have a broad language coverage, enabling them to also reach locales and regions with low-resource languages.
5.1.5. Long Context
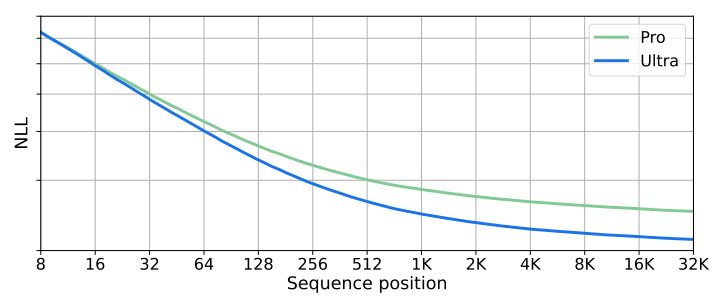
Gemini models are trained with a sequence length of 32,768 tokens and we find that they make use of their context length effectively. We first verify this by running a synthetic retrieval test: we place key-value pairs at the beginning of the context, then add long filler text, and ask for value associated with a particular key. We find that the Ultra model retrieves the correct value with 98% accuracy when queried across the full context length. We further investigate this by plotting the negative log likelihood (NLL) versus the token index across a held-out set of long documents in Figure 4. We find that the NLL decreases with sequence position up to the full 32K context length. The longer context length of Gemini models enable new use cases such as retrieval over documents and video understanding discussed in section 5.2.2.
5.1.6. Human Preference Evaluations
Human preference of the model outputs provides an important indication of quality that complements automated evaluations. We have evaluated the Gemini models in side-by-side blind evaluations where human raters judge responses of two models to the same prompt. We instruction tune (Ouyang et al., 2022) the pretrained model using techniques discussed in the section 6.4.2. The instruction-tuned version of the model is evaluated on a range of specific capabilities, such as following instructions, creative writing, multimodal understanding, long context understanding, and safety. These capabilities encompass a range of use cases inspired by current user needs and research-inspired potential future use cases.
Instruction-tuned Gemini Pro models provide a large improvement on a range of capabilities including preference for the Gemini Pro model over the PaLM 2 model API, 65.0% time in creative writing, 59.2% in following instructions, and 68.5% time for safer responses as shown in Table 6. These improvements directly translate into a more helpful and safer user experience.

5.1.7. Complex Reasoning Systems
Gemini can also be combined with additional techniques such as search and tool-use to create powerful reasoning systems that can tackle more complex multi-step problems. One example of such a system is AlphaCode 2, a new state-of-the-art agent that excels at solving competitive programming problems (Leblond et al, 2023). AlphaCode 2 uses a specialized version of Gemini Pro – tuned on competitive programming data similar to the data used in Li et al. (2022) – to conduct a massive search over the space of possible programs. This is followed by a tailored filtering, clustering and reranking mechanism. Gemini Pro is fine-tuned both to be a coding model to generate proposal solution candidates, and to be a reward model that is leveraged to recognize and extract the most promising code candidates.
AlphaCode 2 is evaluated on Codeforces,[5] the same platform as AlphaCode, on 12 contests from division 1 and 2, for a total of 77 problems. AlphaCode 2 solved 43% of these competition problems, a 1.7x improvement over the prior record-setting AlphaCode system which solved 25%. Mapping this to competition rankings, AlphaCode 2 built on top of Gemini Pro sits at an estimated 85th percentile on average – i.e. it performs better than 85% of entrants. This is a significant advance over AlphaCode, which only outperformed 50% of competitors.
The composition of powerful pretrained models with search and reasoning mechanisms is an exciting direction towards more general agents; another key ingredient is deep understanding across a range of modalities which we discuss in the next section.
5.2. Multimodal
Gemini models are natively multimodal. These models exhibit the unique ability to seamlessly combine their capabilities across modalities (e.g. extracting information and spatial layout out of a table, a chart, or a figure) with the strong reasoning capabilities of a language model (e.g. its state-of-art-performance in math and coding) as seen in examples in Figures 5 and 12. The models also show strong performance in discerning fine-grained details in inputs, aggregating context across space and time, and applying these capabilities over a temporally-related sequence of video frames and/or audio inputs.
The sections below provide more detailed evaluation of the model across different modalities (image, video, and audio), together with qualitative examples of the model’s capabilities for image generation and the ability to combine information across different modalities.
5.2.1. Image Understanding
We evaluate the model on four different capabilities: high-level object recognition using captioning or question-answering tasks such as VQAv2; fine-grained transcription using tasks such as TextVQA and DocVQA requiring the model to recognize low-level details; chart understanding requiring spatial understanding of input layout using ChartQA and InfographicVQA tasks; and multimodal reasoning using tasks such as Ai2D, MathVista and MMMU. For zero-shot QA evaluation, the model is instructed to provide short answers aligned with the specific benchmark. All numbers are obtained using greedy sampling and without any use of external OCR tools.
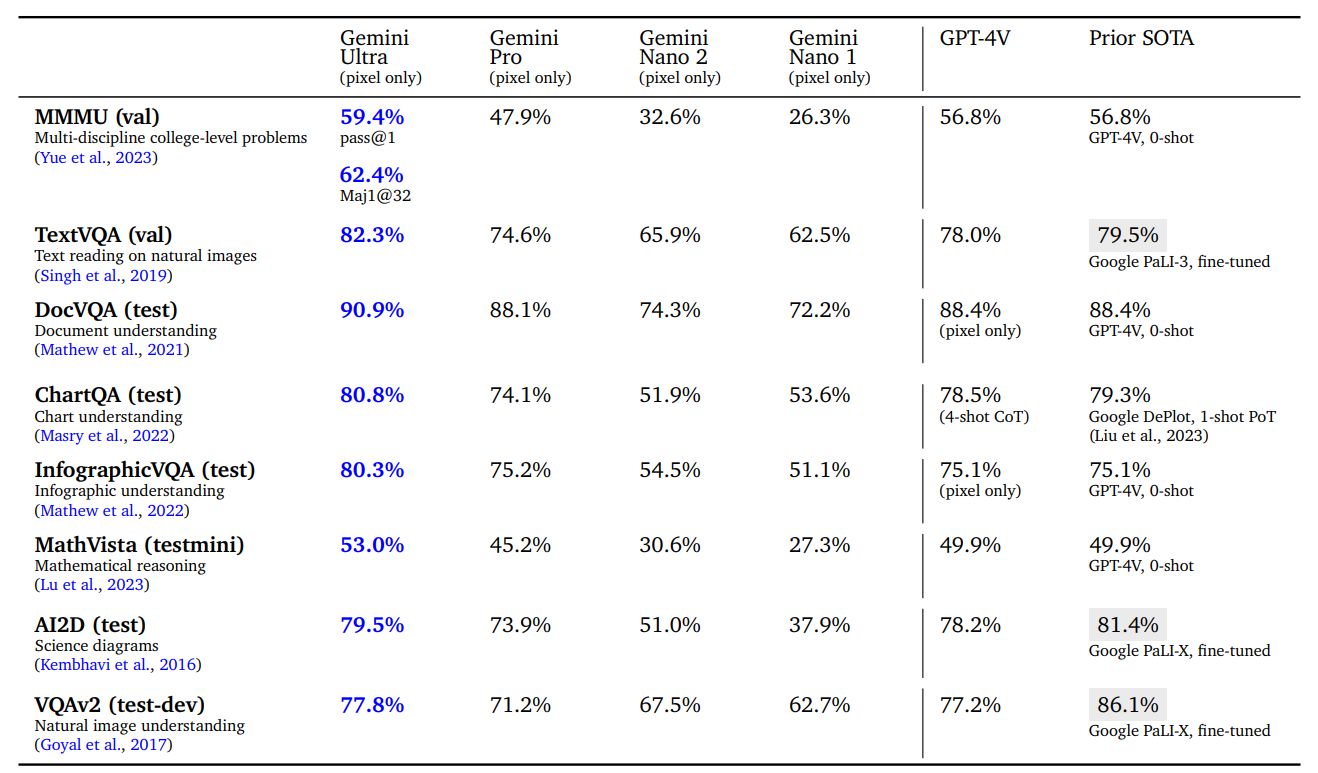
We find that Gemini Ultra is state of the art across a wide range of image-understanding benchmarks in Table 7. It achieves strong performance across a diverse set of tasks such as answering questions on natural images and scanned documents as well as understanding infographics, charts and science diagrams. When compared against publicly reported results from other models (most notably GPT-4V), Gemini is better in zero-shot evaluation by a significant margin. It also exceeds several existing models that are specifically fine-tuned on the benchmark’s training sets for the majority of tasks. The capabilities of the Gemini models lead to significant improvements in the state of the art on academic benchmarks like MathVista (+3.1%)[6] or InfographicVQA (+5.2%).
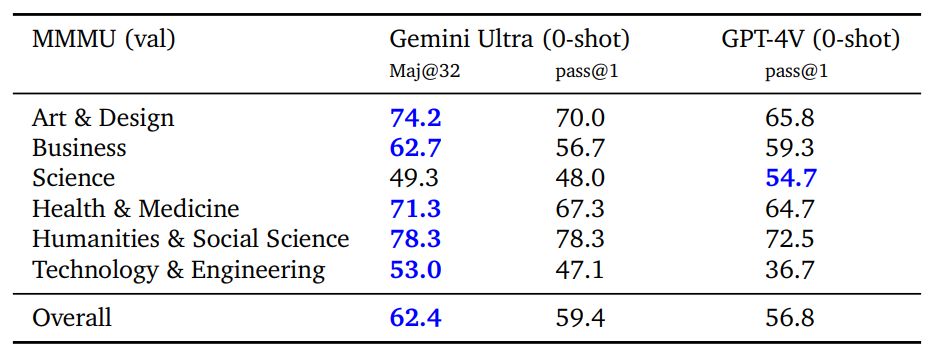
MMMU (Yue et al., 2023) is a recently released evaluation benchmark, which consists of questions about images across 6 disciplines with multiple subjects within each discipline that require collegelevel knowledge to solve these questions. Gemini Ultra achieves the best score on this benchmark advancing the state-of-the-art result by more than 5 percentage points and outperforms the previous best result in 5 of 6 disciplines (see Table 8), thus showcasing its multimodal reasoning capabilities.
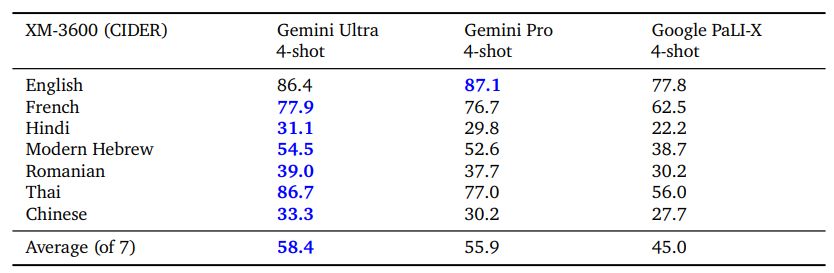
Gemini models are also capable of operating across modalities and a diverse set of global languages simultaneously, both for image understanding tasks (e.g., images containing text in Icelandic) and for generation tasks (e.g., generating image descriptions for a wide range of languages). We evaluate the performance of generating image descriptions on a selected subset of languages in the Crossmodal3600 (XM-3600) benchmark in a 4-shot setting, using the Flamingo evaluation protocol (Alayrac et al., 2022), without any fine-tuning for all models. As shown in Table 9, Gemini models achieve a significant improvement over the existing best model, Google PaLI-X.
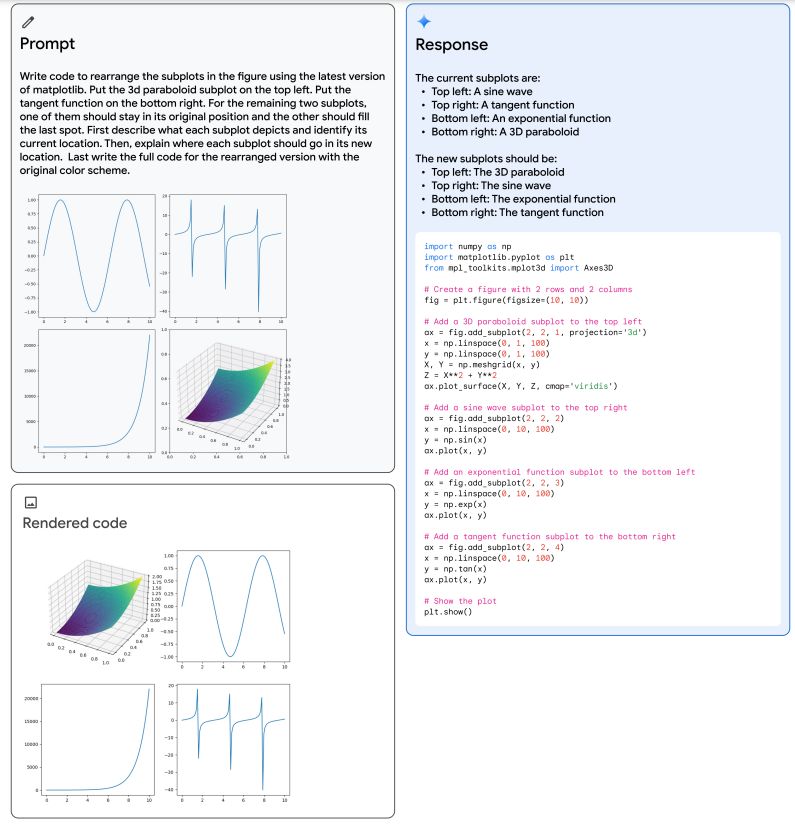
Qualitative evaluation in Figure 5 illustrates an example of Gemini Ultra’s multimodal reasoning capabilities. The model is required to solve the task of generating matplotlib code that would rearrange a set of subplots provided by the user. The model output shows that it successfully solves this task combining multiple capabilities of understanding the user plot, inferring the code required to generate it, following user instructions to put subplots in their desired positions, and abstract reasoning about the output plot. This highlights Gemini Ultra’s native multimodality and eludes to its more complex reasoning abilities across interleaved sequences of image and text. We refer the reader to the appendix for more qualitative examples.
5.2.2. Video Understanding
Understanding video input is an important step towards a useful generalist agent. We measure the video understanding capability across several established benchmarks that are held-out from training. These tasks measure whether the model is able to understand and reason over a temporally-related sequence of frames. For each video task, we sample 16 equally-spaced frames from each video clip and feed them to the Gemini models. For the YouTube video datasets (all datasets except NextQA and the Perception test), we evaluate the Gemini models on videos that were still publicly available in the month of November, 2023.
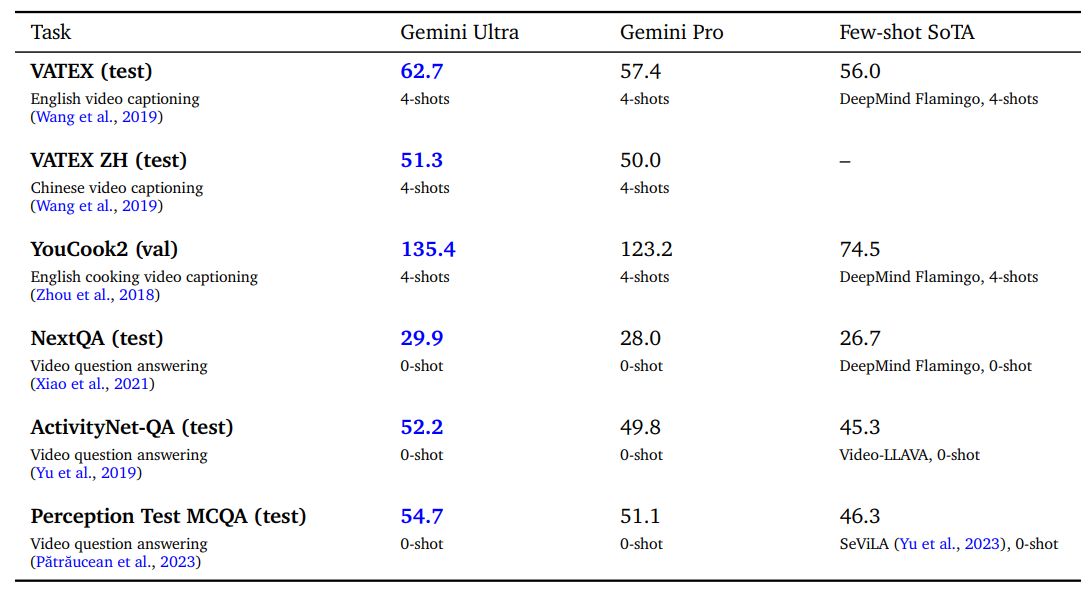
Gemini Ultra achieves state-of-the-art results on various few-shot video captioning tasks as well as zero-shot video question answering tasks as shown in Table 10. This demonstrates its capability of strong temporal reasoning across several frames. Figure 21 in the appendix provides a qualitative example of understanding the video of the ball-striking mechanics of a soccer player and reasoning about the player can improve their game.
5.2.3. Image Generation
Gemini is able to output images natively, without having to rely on an intermediate natural language description that can bottleneck the model’s ability to express images. This uniquely enables the model to generate images with prompts using interleaved sequences of image and text in a few-shot setting. For example, the user might prompt the model to design suggestions of images and text for a blog post or a website (see Figure 10 in the appendix).
Figure 6 shows an example of image generation in 1-shot setting. Gemini Ultra model is prompted with one example of interleaved image and text where the user provides two colors (blue and yellow) and image suggestions of creating a cute blue cat or a blue dog with yellow ear from yarn. The model is then given two new colors (pink and green) and asked for two ideas about what to create using these colors. The model successfully generates an interleaved sequence of images and text with suggestions to create a cute green avocado with pink seed or a green bunny with pink ears from yarn.

5.2.4. Audio Understanding
We evaluate the Gemini Nano-1 and Gemini Pro models on a variety of public benchmarks and compare it with Universal Speech Model (USM) (Zhang et al., 2023) and Whisper (large-v2 (Radford et al., 2023) or large-v3 (OpenAI, 2023) as indicated). These benchmarks include automatic speech recognition (ASR) tasks such as FLEURS (Conneau et al., 2023), VoxPopuli, (Wang et al., 2021), Multi-lingual Librispeech (Pratap et al., 2020), as well as the speech translation task CoVoST 2, translating different languages into English (Wang et al., 2020). We also report on an internal benchmark YouTube test set. ASR tasks report a word error rate (WER) metric, where a lower number is better. Translation tasks report a BiLingual Evaluation Understudy (BLEU) score, where a higher number is better. FLEURS is reported on 62 languages that have language overlap with the training data. Four segmented languages (Mandarin, Japanese, Korean and Thai)
Table 11 indicates that our Gemini Pro model significantly outperforms the USM and Whisper models across all ASR and AST tasks, both for English and multilingual test sets. Note that there is a large gain in FLEURS, compared to USM and Whisper, as our model is also trained with the FLEURS training dataset. However, training the same model without FLEURS dataset results in a WER of 15.8, which still outperforms Whisper. Gemini Nano-1 model also outperforms both USM and Whisper on all datasets except FLEURS. Note that we did not evaluate Gemini Ultra on audio yet, though we expect better performance from increased model scale.
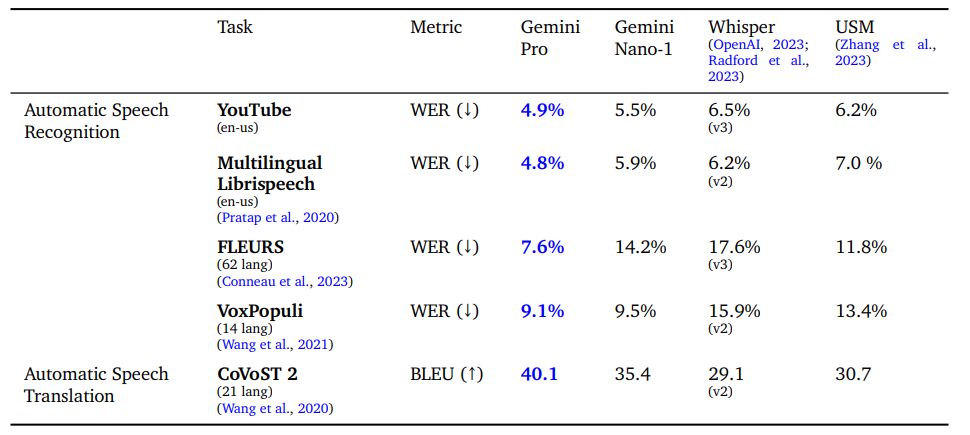
Table 12 shows further error analysis with USM and Gemini Pro. We find that Gemini Pro produces more understandable responses, particularly on rare words and proper nouns.

5.2.5. Modality Combination
Multimodal demonstrations often include a combination of text interleaved with a single modality, usually images. We demonstrate the ability to process a sequence of audio and images natively.
Consider a cooking scenario about making an omelet where we prompt the model with a sequence of audio and images. Table 13 indicates a turn-by-turn interaction with the model, providingpictures and verbally asking questions about the next steps for cooking an omelet. We note that the model response text is reasonably accurate, and shows that model processes fine grained image details to evaluate when the omelet is fully cooked. See demo on the website.

[4] See demos on website https://deepmind.google/gemini.
[5] http://codeforces.com/
[6] MathVista is a comprehensive mathematical reasoning benchmark consisting of 28 previously published multimodal datasets and three newly created datasets. Our MathVista results were obtained by running the MathVista authors’ evaluation script.