
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Gemini Team, Google.
Table of Links
Discussion and Conclusion, References
Contributions and Acknowledgments
6. Responsible Deployment
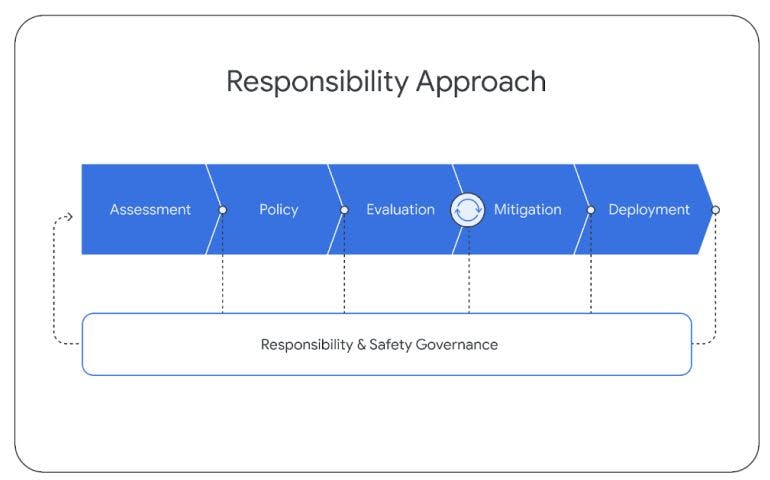
During the development of the Gemini models, we follow a structured approach to responsible deployment in order to identify, measure, and manage foreseeable downstream societal impacts of our models, in line with previous releases of Google’s AI technology (Kavukcuoglu et al., 2022). Throughout the lifecycle of the project, we follow the structure below. This section outlines our broad approach and key findings through this process. We will share more details on this in an upcoming report.
6.1. Impact Assessment
We develop model impact assessments to identify, assess, and document key downstream societal benefits and harms associated with the development of advanced Gemini models. These are informed by prior academic literature on language model risks (Weidinger et al., 2021), findings from similar prior exercises conducted across the industry (Anil et al., 2023; Anthropic, 2023; OpenAI, 2023a), ongoing engagement with experts internally and externally, and unstructured attempts to discover new model vulnerabilities. Areas of focus include: factuality, child safety, harmful content, cybersecurity, biorisk, representation and inclusivity. These assessments are updated in tandem with model development.
Impact assessments are used to guide mitigation and product delivery efforts, and inform deployment decisions. Gemini impact assessments spanned across different capabilities of Gemini models, assessing the potential consequences of these capabilities with Google’s AI Principles (Google, 2023).
6.2. Model Policy
Building upon this understanding of known and anticipated effects, we developed a set of “model policies” to steer model development and evaluations. Model policy definitions act as a standardized criteria and prioritization schema for responsible development and as an indication of launch-readiness. Gemini model policies cover a number of domains including: child safety, hate speech, factual accuracy, fairness and inclusion, and harassment.
6.3. Evaluations
To assess the Gemini models against policy areas and other key risk areas identified within impact assessments, we developed a suite of evaluations across the lifecycle of model development.
Development evaluations are conducted for the purpose of ‘hill-climbing’ throughout training and fine-tuning Gemini models. These evaluations are designed by the Gemini team, or are assessments against external academic benchmarks. Evaluations consider issues such as helpfulness (instruction following and creativity), safety and factuality. See section 5.1.6 and the next section on mitigations for a sample of results.
Assurance evaluations are conducted for the purpose of governance and review, usually at the end of key milestones or training runs by a group outside of the model development team. Assurance evaluations are standardized by modality and datasets are strictly held-out. Only high-level insights are fed back into the training process to assist with mitigation efforts. Assurance evaluations include testing across Gemini policies, and include ongoing testing for dangerous capabilities such as potential biohazards, persuasion, and cybersecurity (Shevlane et al., 2023).
External evaluations are conducted by partners outside of Google to identify blindspots. External groups stress-test our models across a range of issues, including across areas listed in the White House Commitments,[7] and tests are conducted through a mixture of structured evaluations and unstructured red teaming. The design of these evaluations are independent and results are reported periodically to the Google DeepMind team.
In addition to this suite of external evaluations, specialist internal teams conduct ongoing red teaming of our models across areas such as the Gemini policies and security. These activities include less structured processes involving sophisticated adversarial attacks to identify new vulnerabilities. Discovery of potential weaknesses can then be used to mitigate risks and improve evaluation approaches internally. We are committed to ongoing model transparency and plan to share additional results from across our evaluation suite over time.
6.4. Mitigations
Mitigations are developed in response to the outcomes of the assessment, policy, and evaluation approaches described above. Evaluations and mitigations are used in an iterative way, with evaluations being re-run following mitigation efforts. We discuss our efforts on mitigating model harms across data, instruction-tuning, and factuality below.
6.4.1. Data
Prior to training, we take various steps to mitigate potential downstream harms at the data curation and data collection stage. As discussed in the section on “Training Data”, we filter training data for high-risk content and to ensure all training data is sufficiently high quality. Beyond filtering, we also take steps to ensure all data collected meets Google DeepMind’s best practices on data enrichment,[8] developed based on the Partnership on AI’s “Responsible Sourcing of Data Enrichment Services”[9]. This includes ensuring all data enrichment workers are paid at least a local living wage.
6.4.2. Instruction Tuning
Instruction tuning encompasses supervised fine tuning (SFT) and reinforcement learning through human feedback (RLHF) using a reward model. We apply instruction tuning in both text and multimodal settings. Instruction tuning recipes are carefully designed to balance the increase in helpfulness with decrease in model harms related to safety and hallucinations (Bai et al., 2022a).
Curation of “quality” data is critical for SFT, reward model training, and RLHF. The data mixture ratios are ablated with smaller models to balance the metrics on helpfulness (such as instruction following, creativity) and reduction of model harms, and these results generalize well to larger models. We have also observed that data quality is more important than quantity (Touvron et al., 2023b; Zhou et al., 2023), especially for larger models. Similarly, for reward model training, we find it critical to balance the dataset with examples where the model prefers to say, “I cannot help with that,” for safety reasons and examples where the model outputs helpful responses. We use multi-objective optimization with a weighted sum of reward scores from helpfulness, factuality, and safety, to train a multi-headed reward model.
We further elaborate our approach to mitigate risks of harmful text generation. We enumerate approximately 20 harm types (e.g. hate speech, providing medical advice, suggesting dangerous behavior) across a wide variety of use cases. We generate a dataset of potential harm-inducing queries in these categories, either manually by policy experts and ML engineers, or via prompting high capability language models with topical keywords as seeds.
Given the harm-inducing queries, we probe our Gemini models and analyze the model responses via side-by-side evaluation. As discussed above, we balance the objective of model output response being harmless versus being helpful. From the detected risk areas, we create additional supervised fine-tuning data to demonstrate the desirable responses. To generate such responses at scale, we heavily rely on a custom data generation recipe loosely inspired from Constitutional AI (Bai et al., 2022b), where we inject variants of Google’s content policy language as “constitutions”, and utilize language model’s strong zero-shot reasoning abilities (Kojima et al., 2022) to revise responses and choose between multiple response candidates. We have found this recipe to be effective – for example in Gemini Pro, this overall recipe was able to mitigate a majority of our identified text harm cases, without any perceptible decrease on response helpfulness.
6.4.3. Factuality
It is important that our models generate responses that are factual in a variety of scenarios, and to reduce the frequency of hallucinations. We focused instruction tuning efforts on three key desired behaviors, reflecting real-world scenarios:
1. Attribution: If instructed to generate a response that should be fully attributed to a given context in the prompt, Gemini should produce a response with the highest degree of faithfulness to the context (Rashkin et al., 2023). This includes the summarization of a user-provided source, generating fine-grained citations given a question and provided snippets akin to Menick et al. (2022); Peng et al. (2023), answering questions from a long-form source such as a book (Mihaylov et al., 2018), and transforming a given source to a desired output (e.g. an email from a portion of a meeting transcript).
2. Closed-Book Response Generation: If provided with a fact-seeking prompt without any given source, Gemini should not hallucinate incorrect information (see Section 2 of Roberts et al. (2020) for a definition). These prompts can range from information-seeking prompts (e.g. “Who is the prime minister of India?”) to semi-creative prompts that may request factual information (e.g. “Write a 500-word speech in favor of the adoption of renewable energy”).
3. Hedging: If prompted with an input such that it is “unanswerable”, Gemini should not hallucinate. Rather, it should acknowledge that it cannot provide a response by hedging. These include scenarios where the input prompt contains false-premise questions (see examples in Hu et al. (2023)), the input prompt instructs the model to perform open-book QA, but the answer is not derivable from the given context, and so forth.
We elicited these desired behaviors from Gemini models by curating targeted supervised-fine tuning datasets and performing RLHF. Note that the results produced here do not include endowing Gemini with tools or retrieval that purportedly could boost factuality (Menick et al., 2022; Peng et al., 2023). We provide three key results on respective challenge sets below.
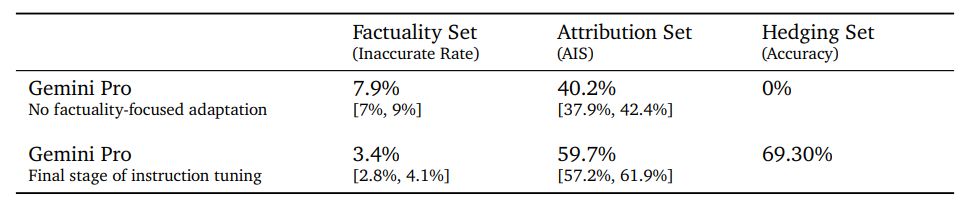
1. Factuality Set: An evaluation set containing fact-seeking prompts (primarily closed-book). This is evaluated via human annotators who fact-check each response manually; we report the percentage of factually-inaccurate responses as judged by annotators.
2. Attribution Set: An evaluation set containing a variety of prompts that require attribution to sources in the prompt. This is evaluated via human annotators who check for attribution to sources in the prompt for each response manually; the reported metric is AIS (Rashkin et al., 2023).
3. Hedging Set: An automatic evaluation setup where we measure whether Gemini models hedge
accurately
We compare Gemini Pro with a version of instruction-tuned Gemini Pro model without any factuality focused adaptation in Table 14. We observe that the rate of inaccuracy is halved in the factuality set, the accuracy of attribution is increased by 50% from the attribution set, and the model successfully hedges 70% (up from 0%) in the provided hedging set task.
6.5. Deployment
Following the completion of reviews, model cards (Mitchell et al., 2019) for each approved Gemini model are created for structured and consistent internal documentation of critical performance and responsibility metrics as well as to inform appropriate external communication of these metrics over time.
6.6. Responsible Governance
Across the responsible development process, we undertake ethics and safety reviews with the Google DeepMind’s Responsibility and Safety Council (RSC),[10] an interdisciplinary group which evaluates Google DeepMind’s projects, papers and collaborations against Google’s AI Principles. The RSC provides input and feedback on impact assessments, policies, evaluations and mitigation efforts. During the Gemini project, the RSC set specific evaluation targets across key policy domains (e.g. child safety).
[7] https://whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf
[8] https://deepmind.google/discover/blog/best-practices-for-data-enrichment/
[9] https://partnershiponai.org/responsible-sourcing-considerations/
[10] https://deepmind.google/about/responsibility-safety/